在前面文章中介绍过LCM(Latent Consistency Model)跳过将随机过程转化为固定过程(将随机微分SDE转化为常微分ODE)进而实现生成(只需要3-5步生成图像)加速,简单回顾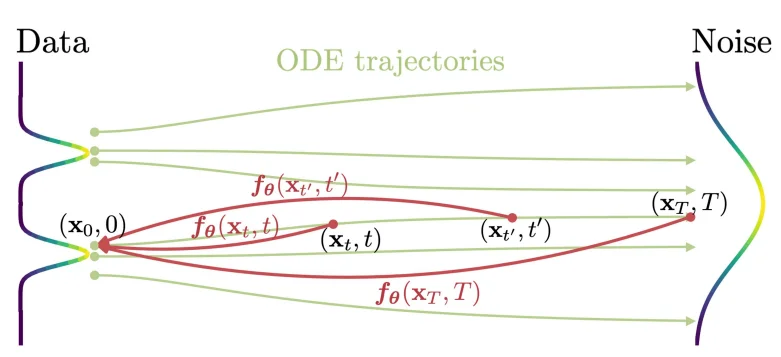
将随机生成过程变成“确定”过程,这样一来生成就是确定的,那么就可以实现跳跃式生成,从 $T\rightarrow t_0$ 所有的点都在“一条线”上等式 $f(x_t,t)=f(x_{t^\prime},t^\prime)$ 其中 $t,t^\prime \in [\epsilon,T]$ 成立那么就保证了模型不需要再去不断依靠 $t+1$ 生成内容去推断 $t$时刻内容。而本文介绍的Flow Matching算法,通过直接学习一个连续的确定性向量场(velocity field),构造出从噪声到数据的最优(通常近似直线)的概率路径从而实现生成的加速。
Flow Matching基本原理
简单介绍
用基本例子进行理解,比如说给定一个全随机的橡皮泥(相当于纯噪声),将其慢慢捏成一个具体的雕像(比如一只猫图像)。传统扩散模型:先把雕像一点点加上各种小随机扰动,直到完全看不出是猫了(前向加噪)。然后训练一个神经网络学会“反过来一点点去掉扰动”,从乱泥巴慢慢还原成猫(反向去噪)。这个过程有很多随机性,每走一步都有点“抖动”,所以路径是弯弯曲曲的,采样时通常要走很多步(20–100步)。Flow Matching:直接跳过一条最平滑、最直接的路,让这团乱橡皮泥顺着这条路一直往前走,就能变成猫,其核心思想就是,学习一条从噪声到数据的连续“流动”路径(flow),并且这条路径是确定的。
对于其中所谓的“流动”路径,比如说生成过程从t=0(纯噪声数据)到t=1(真实数据),如果存在“速度场”,能够了解在每一个时刻 t、每一个位置x上,东西应该往哪个方向、以多大的速度移动,才能最终到达正确图像,也就是对于微分方程 $\frac{dx}{dt}=v_{\theta}(x,t)$相对于告诉每一个瞬时速度。模型训练过程中1,在传统的SD模型训练过程中是去预测每一步的噪声(而后去减掉该步的噪声),而Flow Matching则是直接让模型去预测移动速度,比如下面代码
对于上图中数据直接就是MNIST数据集(x_1,y,x_0分别对应图像、标签、噪声)而上述黄色框中过程首先去生成时间步(正如上面描述的时间从t=0–>t=1)那么就对应每张图像都是$t\in [0,1]$,除此之外其中的path_sampler就对应上面提到的流动路径,返回的两个值:$x_t=t\times x_1+ (1-t)x_0$ 以及对应的速度 $dx_t=x_1-x_0$那么最后模型预测过程也就是去预测这个速度。在得到最后的优化模型之后就是直接去采样,采样过程:
对于上述的采样路径($x_t=t\times x_1+ (1-t)x_0$)可以直接替换为其他的都可以,除此之外Flow Matching可能不能直接(效果不佳)去作用在SD1.5此类模型可以借鉴2中方法进行操作,主要是因为两者在寻览过程中预测内容就是不同的,前者是直接预测噪声,并且其采样路径是随机的,而FM路径是固定的。
深度介绍
ing……….
https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html#introduction
https://peterroelants.github.io/posts/flow_matching_intro/
https://federicosarrocco.com/blog/flow-matching
https://arxiv.org/pdf/2210.02747