系列文章:
1、强化学习算法-1:GRPO、DPO与PPO解析
2、强化学习算法-2:熵坍缩以及奖励坍缩问题机制分析及解决措施
3、强化学习算法-3:GSPO、SAPO及KL散度改进
简单回顾LLM训练过程
在Blog里面讨论过LLM框架这里简单讨论一下LLM训练过程,一般而言在LLM中训练主要分为如下几个阶段:1、预训练阶段:这部分简单理解就是让LLM能够说“人话”,自回归模型通过前一段文本然后预测下一个文本,并且让模型能够较好的“说话”(比如说:大语言模,下一个字可以正确输出 “型”);2、后训练阶段:在得到一个能够说人话的模型之后,就需要让模型能够“思考”,这部分主要分为两部分:1、监督微调(SFT Supervised Training);2、人类反馈强化学习(RLHF Reinforcement Learning from Human Feedback)。前者:顾名思义,我们首先使用监督学习方法,在少量高质量的专家推理数据上对 LLM 进行微调,例如指令跟踪、问题解答和/或思维链。希望在训练阶段结束时,模型已经学会如何模仿专家演示。后者:RLHF 利用人类反馈来训练奖励模型,然后通过 RL 引导 LLM 学习。这就使模型与人类的细微偏好保持一致。对于SFT以及RL两者之间差异可以简单理解为:SFT是模型对数据的“拟合”因为SFT过程中一般就是让模型输出去贴近我的数据集,而RL更加像模型对问题探索
DPO
DPO直接根据人类偏好数据对模型进行微调,使其生成更符合人类期望的输出,损失函数为:
\[\mathcal{L}_{\text{DPO}}(\pi_{\theta};\pi_{\text{ref}})=-\mathbb{E}_{(x,y_c,y_r)\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_c|x)}{\pi_{\text{ref}}(y_c|x)}-\beta\log\frac{\pi_{\theta}(y_r|x)}{\pi_{\text{ref}}(y_r|x)}\right)\right]\]其中:
$\pi_{\theta}$:当前优化的语言模型(策略模型,实际应用可能就是添加Lora的模型)。
$\pi_{\text{ref}}$:参考模型,通常是监督微调后的模型(或者就是原始模型,亦或者更加强大的模型),用于稳定训练。
$\sigma$:Sigmoid 函数,将偏好分数映射到 (0, 1)。
$\beta$:一个超参数,控制偏好强度的缩放(通常取值在 0.1 到 1 之间)。
$y_c,y_r$:优选和劣选回答。
$\mathcal{D}$:偏好数据集。
DPO 优化过程
直观理解上面过程,DPO模型是一种纯粹数据驱动的训练范式,比如说下面例子: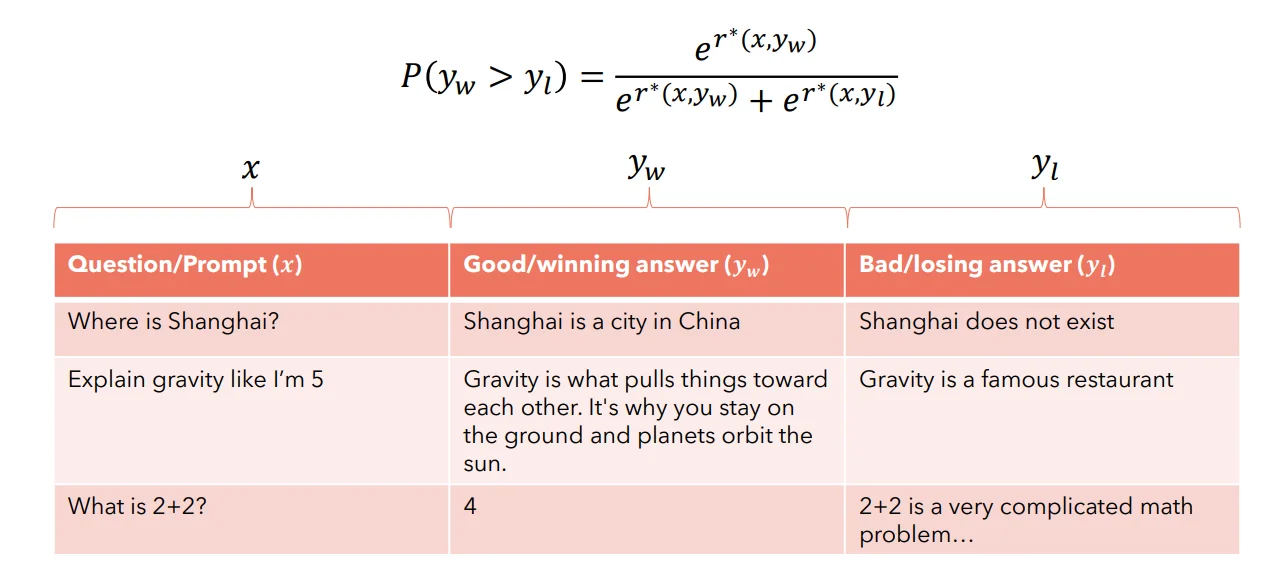
模型的优化目标就是需要让 我们的模型生成更加倾向生成Good answer 并且降低生成Bad answer的概率。假设存在数据集$\mathcal{D}=(\text{Prompt}, \text{GoodAnswer}, \text{BadAnswer})$(简化为:$D=(x, y_c, y_r)$);模型:$\pi_{\theta}$、$\pi_{\text{ref}}$。损失函数为:
那么DPO处理过程为:
第一步进行数据准备与拼接。将输入数据通过tokenizer处理然后进行拼接得到两个输入队列: $[x,y_w]$ 以及 $[x,y_l]$
第二步前向计算 log-probabilities(只计算回答部分的 token 概率)。分别将两个序列输入 $\pi_\theta$ 和 $\pi_{\rm ref}$,得到 logitsq((batch_size, seq_len, vocab_size))。比如说对于chosen 序列:模型的输入长度为:$|x| + |y_w|$,模型输出 logits直接通过 logits = model(input_ids_chosen).logits 形状:$(1, |x|+|y_w|, V)$,只需要回答部分的 log-prob(log_probs = log_softmax(logits, dim=-1)),即从第 $|x|$ 个位置开始(注意:自回归模型中,第 $|x|$ 个 token 的预测对应 $y_w$ 的第一个 token)
per_token_logps = torch.gather(
log_probs,
dim=-1,
index=labels.unsqueeze(-1)
).squeeze(-1) # shape: (bs, seq_len)
# 忽略 prompt 部分(mask 掉前 |x| 个位置的 loss)
masked_logps = per_token_logps * response_mask
logps_chosen_θ = masked_logps.sum(dim=-1) / response_mask.sum(dim=-1).clamp(min=1)
通过上面代码就可以直接得到 $\log \pi_\theta(y_w | x) \approx \text{logps_chosen_θ}$。同理计算 $\log \pi_\theta(y_l | x)$、参考模型的 $\log \pi_{\rm ref}(y_w | x)$ 和 $\log \pi_{\rm ref}(y_l | x)$。
第三步计算loss并且反向传播。
log_ratio_w = logps_chosen_θ - logps_chosen_ref
log_ratio_l = logps_rejected_θ - logps_rejected_ref
diff = β * (log_ratio_w - log_ratio_l)
loss = -log(sigmoid(diff)).mean()
PPO

PPO是一种基于策略梯度的强化学习算法,核心思想是通过限制策略更新的幅度来保持训练的稳定性。其目标函数(通过KL散度处理)为:
$\pi_\theta$: 当前策略参数化的策略函数
$A_t$: 优势函数,衡量动作$a_t$相对于平均水平的优势
$\epsilon$: 超参数(通常0.1-0.2),限制策略更新的最大幅度
Clipping机制:通过截断重要性采样比率,防止策略更新过大导致训练不稳定
对于上述公式里面优势函数$A_t$(用来衡量的是某个动作相对于平均水平的优势,也就是说,这个动作比平均情况好多少)具体计算公式为:$A_t=Q(s_t, a_t)-V(s_t)$,分别表示:1、$Q(s_t, a_t)$:在状态$s_t$下执行动作$a_t$得到的期望汇报;2、$V(s_t)$:状态$s_t$的平均累计期望。对于其计算可以通过GAE(广义优势估计)来进行计算。在实际优化过程中计算的loss是
PPO优化过程
对于PPO模型优化过程:
第一步 数据采样与 rollout(on-policy 生成)。从当前策略 $\pi_\theta$(通常是 SFT 后的模型,或者直接Lora处理的模型)采样一批 prompt $x$,然后让模型自回归生成完整的模型输出 $y \sim \pi_\theta(\cdot | x)$。记录每个 token 的 log-prob(用于后续 importance ratio 计算)和 entropy(可选)。此外,通常会生成多个响应(e.g. 4~64 条)来增加多样性以及更加稳定的优势估计。
第二步 前向计算 reward + advantage(使用 Reward Model + Critic + GAE)。对每条生成的响应 $y$。
用 Reward Model $r_\phi(x, y)$ 计算标量奖励 $r$,通常在序列末尾打分,或 process-level 每步打分,一般而言对于Reward Model会直接用一个独立的模型直接将我的prompt+模型输出丢给模型然后输出一个评分。
用参考模型 $\pi_{\rm ref}$(通常是冻结的 SFT 模型)计算 KL 散度(防止偏离过远)。
\(\tilde{r}_t = r_t - \beta \cdot \text{KL}\bigl(\pi_\theta(\cdot|s_t) \big\| \pi_{\rm ref}(\cdot|s_t)\bigr)\)
其中 $r_t = 0$(对于 $t < T$),$r_T = r$(序列末尾),$\beta$ 是 KL 系数(常见 0.01–0.05,可动态调整)。
用价值模型(Critic)$V_\psi(s)$ 估计状态价值。一般价值模型和策略模型(一般而言就是Lora分装的模型)共享大部分参数(transformer backbone),但在最后一层额外接一个线性头,输出 scalar value $V_\psi(s_t)$。计算GAE得到每一个token的优势估计 $\hat{A}_t$:
其中($\gamma \approx 1.0$ 或 0.99,$\lambda \approx 0.95$)。$r_t$ 在第 t 步(生成第 t 个 token 后)获得的即时奖励即 Reward Model 给整个响应的分数。对于GAE过程可以这么理解:最开始模型对于prompt生成一条(多条)输出,也就是下面一个token序列
s_0 = prompt
a_0 → s_1 = prompt + token_0
a_1 → s_2 = prompt + token_0 + token_1
...
a_{T-1} → s_T = prompt + 全部生成 token(结束)
直接整个序列输入给 Critic 网络,得到每一个位置的价值估计:
states = [s_0, s_1, ..., s_T] # 实际上是累积的 input_ids
values = critic(states) # shape: [T+1] 或 [seq_len]
第三步 前向计算 PPO 损失并反向传播。分别使用当前策略 $\pi_\theta$ 和旧策略 $\pi_{\theta_{\rm old}}$(通常是 rollout 开始时的策略拷贝,或上一次更新的快照)计算每个 token 的 log-probability,得到重要性采样比率 $r_t(\theta)$:
\[r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\rm old}}(a_t \mid s_t)} = \exp\left( \log\pi_\theta(a_t \mid s_t) - \log\pi_{\theta_{\rm old}}(a_t \mid s_t) \right)\]基于这个比率和前面计算得到的优势 $\hat{A}_t$,构造 PPO-Clip 的代理目标(surrogate objective):
\[L^{\mathrm{CLIP}}(\theta) = \min\left( r_t(\theta) \hat{A}_t,\ \mathrm{clip}\bigl(r_t(\theta), 1-\epsilon, 1+\epsilon\bigr) \hat{A}_t \right)\]然后计算 PPO 的完整损失函数(实际训练中最小化这个 loss):
\[L(\theta,\phi) = -\mathbb{E}_t \Bigl[ L^{\mathrm{CLIP}}(\theta) \Bigr]+ c_1 \mathbb{E}_t \Bigl[ \bigl(V_\phi(s_t) - \hat{R}_t\bigr)^2 \Bigr]- c_2 \mathbb{E}_t \Bigl[ S[\pi_\theta](s_t) \Bigr]+ \beta \cdot \mathrm{KL}\bigl(\pi_{\theta_{\rm old}} \big\| \pi_\theta\bigr)\]其中:
- 第一项:policy loss(负的 clipped surrogate,最大化它等价于鼓励好动作)
- 第二项:value loss(Critic 的 MSE 损失,$\hat{R}_t$ 是 GAE 计算的 discounted returns 或 bootstrapped target)
- 第三项:entropy bonus(鼓励探索,防止过早收敛)
- 第四项:KL 惩罚(可选,防止策略偏离过远,常见于 adaptive KL 或 early stopping)
对于上述过程中用到模型有:1、policy_model(一般而言就是SFT之后的模型,被Lora封装的,模型需要被训练);2、value_model(一般就是在policy_model基础上额外补充一个处理头去计算每个token概率,模型一般需要训练);3、ref_model(一般就是SFT之后的模型,模型不需要训练);4、reward_model(模型不需要训练)。另外两个模型——reward_model 和 value_model——主要是用来一起算出“优势值”(Advantage),也就是告诉模型“这个选择到底比平均水平好多少”。 简单用开车比喻:
reward_model 就像路上的导航终点 + 路牌评分,它告诉你“往左拐这条路通向风景最好的山顶(高奖励)”,或者“直走这条路会掉进沟里(低/负奖励)”。它负责定义“什么叫好开、什么叫开砸了”。
value_model 就像车载仪表盘上的剩余路程 + 坡度提示.它实时估算:“你现在开到半山腰了,前面还有多陡的坡、多远的路、预计还能赚多少分(剩余价值)”。它帮你知道当前位置的“价值基准”,避免每次都靠运气猜。
把两者结合起来,就能算出优势值(δ_t ≈ r_t + γ V(s_{t+1}) - V(s_t)):
相当于仪表盘告诉你:“刚才右转这个弯,比直走平均水平多省了 20 分钟油钱 + 风景更好(正优势),应该多学学这个动作!”或者:“刚才超车这个操作,虽然过了,但前面堵得更严重,实际比平均水平亏了(负优势),下次别这么干。”
一句话总结:
- reward_model:告诉你“哪条路是终极好路”(目标方向)
- value_model:告诉你“现在开到哪儿了,离好路还有多远、多陡”(当前基准)
缺了任何一个,车就只能瞎开——要么不知道终点在哪,要么不知道自己开得好不好,全靠蒙。
# 1. 计算重要性比率(importance ratio)
ratio = torch.exp(log_probs_theta - log_probs_old) # shape: [bs, seq_len]
# 2. PPO-Clip 代理目标
clipped_ratio = torch.clamp(ratio, 1.0 - epsilon, 1.0 + epsilon) # epsilon 通常 0.1~0.2
surrogate1 = ratio * advantages # advantages: [bs, seq_len]
surrogate2 = clipped_ratio * advantages
policy_loss = -torch.min(surrogate1, surrogate2).mean() # 负号:最小化 loss → 最大化 surrogate
# 3. Value loss(Critic 回归到 GAE target 或 returns)
# returns 可以是 GAE discounted sum,或 advantages + values
value_loss = F.mse_loss(values, returns, reduction='mean')
# 4. Entropy bonus(鼓励动作多样性)
# probs: 当前策略的 softmax 概率分布
entropy = -(probs * log_probs_theta).sum(dim=-1).mean()
# 5. 可选:KL 惩罚(per-token 或 sequence-level,防止崩坏)
# 实际中常使用 ref model 的 log_probs_ref 计算
kl = (log_probs_ref - log_probs_theta).mean() # 近似 KL(或用更精确的无偏估计)
# 6. 组合总损失(典型权重:c1 ≈ 0.5, c2 ≈ 0.01, β ≈ 0.01~0.05)
loss = (
policy_loss
+ c1 * value_loss
- c2 * entropy
+ beta * kl
)
GRPO
GRPO是DPO的扩展形式,处理组级别的偏好优化问题,其核心公式:
\[\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}_{x \sim \mathcal{D}} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min\left( r_{i,t}(\theta) \hat{A}_i,\ \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_i \right) - \beta \, D_{\text{KL}}(\pi_\theta || \pi_{\rm ref}) \right]\] \[D_{\text{KL}}(\pi_\theta || \pi_{\rm ref})=\frac{\pi_{ref}(o_i \vert q)}{\pi_{\theta}(o_i \vert q)}-\log\frac{\pi_{ref}(o_i \vert q)}{\pi_{\theta}(o_i \vert q)}-1, \quad r_{i,t}(\theta)=\frac{\pi_{\theta}(o_{i,t} \vert q,o_{i<t})}{\pi_{\theta_{old}}(o_{i,t} \vert q,o_{i<t})}\] \[A_i=\frac{r_i- \text{mean}({r_1,...,r_G})}{\text{std}({r_1,...,r_G})}\\\]$r^*$: 组内最优响应
$\mathcal{R}$: 包含k个响应的候选集
$q$: 问题, $o_i$: 对于问题生成的第 $i$ 个回答,$r_i$: 回答对应的奖励得分
KL项:防止模型过度偏离初始策略,缓解模式坍塌。对于上面的loss计算公式内部的平均($\frac{1}{\vert o_i \vert}$)是对每条轨迹的token去计算平均值,而外部的平均是对每条轨迹去计算平均值,会带来一些小的问题以及一些小的tips:
1、模型的输出变长(对于错误输出格外明显)1主要由如下两点导致:1、$\frac{1}{\vert o_i \vert}$ 偏差,在正确回答中 $A_i>0$ 那么在除token长度时候就更加倾向长度越短才能保证内部min,而错误回答 $A_i<0$ 则是相反会导致输出长度更加长。2、问题难度偏差,标准差较低的问题(例如,那些过于简单或过于困难,结果奖励几乎全部为 1 或 0 的问题),就会导致计方差很小但是最后优势值极大。针对这两种问题直接:1、去掉计算 $\frac{1}{\vert o_i \vert}$ ;2、不去计算 $\text{std}$
上述为 Dr.GRPO 论文中提出改进
2、模型奖励信号是0,这点问题其实就是如果模型回答后内容奖励函数进行打分发现结果都是相同的就会导致优势值为0进而导致模型无法更新。解决措施2:直接添加虚拟满分样本
rewards = [0.8, 0.8, 0.8, 0.8]
augmented = rewards + [1.0] # 虚拟满分样本
mean = sum(augmented) / len(augmented) # 0.84
std = sqrt(variance(augmented)) # 0.08
advantage = (r - mean) / std # 非零!
GRPO 优化过程

上图中几个比较关键词:1、Policy Model:即我们需要通过强化学习优化的模型;2、Reward Model:奖励模型,即对模型做出的决策所给出的反馈(分类打分的);3、Value Model:估计状态的价值,帮助指导策略优化(分类打分的);4、Reference Model:提供历史策略的参考,确保优化过程中策略变化不过度。其模型优化过程为:
第一步数据采样与生成。对每个 prompt $x$,用当前旧策略(亦或者没有加Lora模型) $\pi_{\theta_{\rm old}}$ 生成 G 条完整响应 ${y_1, y_2, \dots, y_G} $(通常 G=16~64,采样时带 temperature >0 以增加多样性)。每条 $ y_i $ 都是自回归生成的完。同时记录每条响应的 per-token log-prob(用于后续 ratio 计算)。
第二步计算奖励 + 组相对优势。对每条生成的响应 $ y_i $ 计算标量奖励 $ r_i $(verifiable reward),然后在组内归一化得到相对优势:
($ \epsilon $ 小常数防除零,通常 1e-8)
import torch
rewards = torch.tensor([r1, r2, ..., rG]) # shape [G]
mean_r = rewards.mean()
std_r = rewards.std() + 1e-8
advantages = (rewards - mean_r) / std_r # shape [G],每个响应的相对优势
这个 $A_i$ 会广播到该响应 $y_i$ 的所有 token 上(因为 reward 是 sequence-level),和PPO区别在于PPO中会通过模型(直接在Lora封装模型外接一层直接计算每一个token的状态估计值,而后通过GAE去估计最后的优势值)
第三步计算 GRPO 损失并反向传播。计算当前策略 $ \pi_\theta $ 和旧策略 $ \pi_{\theta_{\rm old}} $ 的 log-prob ratio(per-token):
# ratio shape: [bs, seq_len] 或 per-response
ratio = torch.exp(log_probs_theta - log_probs_old)
clipped_ratio = torch.clamp(ratio, 1-ε, 1+ε) # ε 通常 0.2
# surrogate objective(最大化这个,或最小化负值)
surrogate1 = ratio * advantages_i # advantages_i 广播到该响应的所有 token
surrogate2 = clipped_ratio * advantages_i
policy_loss = -torch.min(surrogate1, surrogate2).mean() # 平均过所有 token 和所有组
kl = ... # 计算 π_θ 和 π_ref 的 KL(通常 per-token 平均,或无偏估计)
loss = policy_loss + β * kl # β 通常 0.01~0.05