前面介绍了在pytorch中不同的分布式训练实现方式,这里简单介绍分布式框架(更加多的设计到了模型部署、服务器调度之间内容,非严格的pytorch内容)Ray以及Docker等内容。
前置知识
所有内容只去介绍基本概念与使用,更加丰富的细节建议去看官方文档(或者直接AI)。docker文档1、FastAPI2
并发控制
对于高并发问题最简单理解方式:100个请求同时发送过来你如何进行处理这100个请求。可以串行解决(做完A做B)也可以并行处理(处理A的同时去处理B)
高并发是一个复杂工程设计问题:比如说你的请求优先级高那么如何进行“插队”处理、你的视频内容很长直接下载放到内存中会导致内存问题、其他请求超时如何处理(比如处理1个请求10s超时设置时间是30s那么如果请求很多就会出现超时问题)等等
下面主要去介绍常用的处理 高并发处理方式如通过异步/多线程/多进程进行处理、通过Redis队列进行控制、基于Ray原生的处理方式进行控制等等。
异步/多线程/多进程
首先程序任务主要为两类:1、CPU 密集:一直在”算“,CPU 满载(图片处理、模型推理、加密、大量计算);2、IO 密集:大量时间在”等“(网络请求/读写文件)。而对于异步/多线程/多进程可以简单理解为(以餐厅服务多人为例):一个服务员等菜的时候去别的桌子(异步)、多个服务员同时共用一个厨师(多线程)、直接开多家餐厅(多进程)
进程好理解,在python有 GIL(全局解释器锁),同一时刻只有一个线程能执行 Python 代码,因此对于多线程和异步(两个都是处理IO密集的)使用“差异不大”,如果并发大(比如1w请求)可以考虑异步(不可能开1w个进程)、如果库是同步的就多线程(如request)
异步核心语法3,一般而言异步核心(一般而言涉及到高IO的可以用异步)就是如下几组语法:
import asyncio
# 声明协程函数
async def main():
# 等待可以去执行其他任务
await asyncio.sleep(3)
# 创建 task,提交给事件循环调度执行(await 让出后才真正跑)
task = asyncio.create_task(fetch())
# 创建 event loop 将main放进去进行循环调度
asyncio.run(main())
写异步操作过程中需要去注意:1、先去分析任务类型(如果是IO密集的),比如说使用fastapi中构建请求,就可以直接大胆的用异步比如说:
@app.get("/health")
async def health():
...
2、对于异步中其他语法可以简单理解:
await:等待一个异步任务执行完成,并在等待期间主动让出 CPU 控制权,让事件循环去执行其他协程,不过await后只能跟协程/task/futureasyncio.run:启动整个异步程序,并创建事件循环(Event Loop)去执行指定协程asyncio.create_task:去创建多个task任务,比如说一般会有health任务去检查所有服务,那么可以直接通过此方法直接去创建多个task然后异步执行asyncio.gather:并发执行多个协程,并等待所有协程全部完成后统一返回结果
Ray原始并发控制
Ray 在 actor/task 层面提供了原生的并发与容错控制,核心参数都写在 @ray.remote 装饰器(或调用时的 .options())里:
@ray.remote(
num_gpus=0.25, # GPU 配额:分数=多个 actor 分时共用一张卡(逻辑调度配额,非物理隔离)
max_concurrency=4, # actor 内并发上限:一个 actor 同时最多处理 4 个调用(线程池)
max_restarts=3, # actor 进程崩溃后最多自动重建 3 次
max_task_retries=2, # 单次调用失败后最多自动重试 2 次
)
class Model:
def infer(self, x): ...
并发控制原理:Ray 对 Actor 的并发控制分为两层——调度层 和 执行层。调度层由 Raylet + GCS 负责:当多个调用同时发往同一个 Actor 时,Raylet 先把它们放进该 Actor 的内部任务队列;执行层由 Actor 进程内的线程池(大小 = max_concurrency)消费这个队列——每个线程从队列取一个调用执行,执行完再取下一个,直到队列为空。
sequenceDiagram
participant C1 as 调用方 A
participant C2 as 调用方 B
participant C3 as 调用方 C
participant RL as Raylet (本地调度)
participant TQ as Actor 内部任务队列
participant TP as Actor 线程池<br/>(max_concurrency=2)
participant GPU as GPU
C1->>RL: actor.infer.remote(img1)
C2->>RL: actor.infer.remote(img2)
C3->>RL: actor.infer.remote(img3)
RL->>TQ: 三个调用依次入队
Note over TP: 线程-1 取任务1<br/>线程-2 取任务2<br/>任务3 排队等待
TP-->>GPU: 线程-1 执行推理
TP-->>GPU: 线程-2 执行推理
Note over GPU: GPU kernel 实际串行<br/>但预处理/后处理可重叠
TP->>C1: 返回结果1
Note over TP: 线程-1 空闲 → 取任务3
TP->>C2: 返回结果2
TP-->>GPU: 线程-1 执行推理 (任务3)
TP->>C3: 返回结果3
关键理解:
max_concurrency只是决定了同时有几个线程在”伺候”这个 Actor,但 GPU 计算本身是串行的——多个线程的 GPU kernel 在 CUDA stream 上排队执行。所以max_concurrency的实际收益来自让 IO/预处理与 GPU 计算重叠(线程 A 等在 GPU 上时,线程 B 可以做图像解码),而不是让 GPU “同时算两件事”。
几个要点:
max_concurrency:控制单个 actor 内部的并发。注意 Python GIL + GPU kernel 本身是串行的,设>1主要让预处理/IO 与计算重叠,真正的 GPU 计算还是排队;对非线程安全的模型(比如 vLLM 引擎)必须设成1强制串行,否则并发进同一模型会崩。num_gpus:填分数(<1)时多个 actor 会被打包到同一张卡分时复用,它是 Ray 的调度配额不是显存物理隔离,所以同卡上几个 actor 的显存要自己算好别超(比如0.2+0.5+0.3=1.0刚好一张卡)。max_restarts+max_task_retries:容错,actor 崩了 Ray 自动拉起、调用失败自动重试。- 超时取消:
ray.get(ref, timeout=...)超时后可ray.cancel(ref),但同步方法一旦开跑就无法中断,cancel 只能撤掉还没起跑的排队任务(所以超时了 GPU 其实还在跑,要靠限流从源头控制)。
Ray 原生并发是”actor 内”的并发,实际工程里常在它之上再加一层
API 入口的信号量/限流做背压:给每个模型建一个大小 = 它max_concurrency的信号量,满额直接拒绝(快速失败返回503),而不是让请求堆在 Ray 队列里干等到超时——这样慢模型的积压不会白白空耗 GPU,超时也不会误触发熔断。
Redis队列控制
用 Redis 做队列本质是削峰填谷:请求先进队列缓冲,后端 worker 按自己的处理能力慢慢消费,避免瞬时高并发直接压垮推理服务。典型三个角色:
生产者(API 层):收到请求把任务塞进 Redis 队列(LPUSH),立刻返回一个任务 id(异步任务模式,不阻塞等结果)。消费者(worker):循环从队列阻塞取任务(BRPOP)处理,结果写回 Redis(SET result:<id>)。客户端:拿 id 轮询结果,或用 WebSocket 等服务端推送。
并发控制原理:Redis 队列实现的是消费端拉取模式——不是服务端主动推送,而是多个 worker 自己去抢任务,天然形成竞争消费。核心依赖 Redis List 的以下特性:
| 命令 | 行为 | 并发中的作用 |
|---|---|---|
LPUSH | 从左侧入队(生产者写) | O(1),瞬时写入不阻塞,抗住突发流量 |
BRPOP | 从右侧阻塞弹出(消费者取) | 队列空时阻塞等待,不空转 CPU;多个消费者同时 BRPOP 同一队列时,Redis 单线程保证同一任务只会被一个消费者取走,不会有”抢到同一个任务”的问题 |
LLEN | 查看队列长度 | 监控积压:队列持续增长说明消费跟不上,需要加 worker 或优化推理 |
sequenceDiagram
participant P as 生产者 (FastAPI)
participant R as Redis List<br/>"infer_queue"
participant W1 as Worker 1
participant W2 as Worker 2
participant M as GPU (模型推理)
participant S as Redis KV<br/>result:(id)
Note over P,S: ═══ 正常消费(消费 > 生产) ═══
P->>R: LPUSH task_1
W1->>R: BRPOP (阻塞等待)
R->>W1: 弹出 task_1
W1->>M: model.infer(task_1)
M->>W1: 推理结果
W1->>S: SET result:1
Note over P,S: ═══ 多个 Worker 竞争消费 ═══
P->>R: LPUSH task_2
P->>R: LPUSH task_3
par 竞争弹出
W1->>R: BRPOP → 拿到 task_2
W2->>R: BRPOP → 拿到 task_3
end
Note over W1,W2: Redis 单线程保证<br/>task_2 和 task_3 不会<br/>被同一个 Worker 取走
par 并行推理
W1->>M: infer(task_2)
W2->>M: infer(task_3)
end
W1->>S: SET result:2
W2->>S: SET result:3
Note over P,S: ═══ 削峰场景(生产 > 消费) ═══
P->>R: 瞬时 LPUSH 1000 个任务
Note over R: 队列堆积 1000 条<br/>生产者已返回 task_id<br/>不阻塞、不丢请求
loop 逐条消费
W1->>R: BRPOP → 取一条 → 推理 → 写结果
W2->>R: BRPOP → 取一条 → 推理 → 写结果
end
Note over R: 队列逐渐消化,最终归零
关键理解:Redis 队列的并发能力来自 “单队列 + 多消费者竞争”——队列本身只是一条 List,没有复杂的锁或分片,但多个 Worker 同时
BRPOP时,Redis 的单线程模型天然保证每条任务只被一个 Worker 取走,不需要额外的分布式锁。横向扩展只需要加 Worker 进程数即可,Worker 之间完全无状态、无协调开销。
import redis
r = redis.Redis()
# 生产者:入队,立即返回 task_id
r.lpush("infer_queue", task_json)
# 消费者:阻塞取任务 --> 推理 --> 结果回写(存1小时)
_, task = r.brpop("infer_queue")
result = model.infer(task)
r.set(f"result:{task_id}", result, ex=3600)
它的价值:
削峰:1w 请求瞬时进来,队列缓冲,worker 不会被打爆;限流/优先级:用多个队列(高优先级队列先消费)就能实现前面说的“插队”;解耦+横向扩展:worker 可以多开几个进程/机器一起消费同一个队列。
生产上一般不自己撸队列,直接用 Celery / RQ(底层就是拿 Redis 当 broker)。这套模式最适合
耗时任务异步化——比如前面提到的“长视频处理”,把同步 HTTP 变成“提交任务–>轮询/回调拿结果”,请求端秒回不占连接。
增加节点副本数量
在使用 Ray进行并发控制中单 actor 进程内推理串行(一个模型实例同时只跑一个请求),如果去提高并发数量可以直接 “扩充节点副本”(比如将开始的同一个功能的一个节点直接拓展到n个节点,通过这种方式同时也会带来显存的额外占用)其本质和多进程是相似的比如说下面代码:
import ray
from itertools import cycle
@ray.remote
class ModelA:
def __init__(self): pass
def output(self): return "A"
@ray.remote
class ModelB:
def __init__(self): pass
def output(self): return "B"
# 1) 配置里加副本数:(类, 副本数)
config = {
"ModelA": (ModelA, 2), # 起 2 副本
"ModelB": (ModelB, 1), # 单副本
}
ray.shutdown()
ray.init()
# 2) 命名展开 + 创建:N 副本注册为 name#0..name#N-1;1 副本沿用原名
def replica_names(name, n):
return [name] if n <= 1 else [f"{name}#{i}" for i in range(n)]
actors = {} # {注册名: handle}
replicas = {} # {逻辑名: [注册名...]}
for name, (cls, n) in config.items():
names = replica_names(name, n)
replicas[name] = names
for ray_name in names:
actors[ray_name] = cls.options(name=ray_name).remote()
# 3) 轮询分流:每个逻辑名一个游标,round-robin 选副本
cursors = {name: cycle(names) for name, names in replicas.items()}
def pick(name):
return actors[next(cursors[name])]
# ---- 使用 ----
print(actors) # {'ModelA#0':.., 'ModelA#1':.., 'ModelB':..}
for _ in range(4): # 连续 4 次调用 ModelA,轮流落到 #0/#1
ref = pick("ModelA").output.remote()
print(ray.get(ref))
批处理
不去拓展额外的进程数量,可以通过批处理的方式提高并发,主要分为两种:1、动态批处理;2、连续批处理对于两种批处理方式解释如下:
- 1、动态批处理
对于同时输入的请求,可以尝试将这些请求进行合并组合到一起交给模型处理,比如说又yolo节点,同时输入3张图像(ABC)需要处理,如果是普通处理过程可能是:A->B->C,通过动态批处理则是直接将ABC三组图像组合交给模型处理( 简单理解为模型训练过程中batch_size ),唯一需要注意的是需要设定批处理上线防止OOM出现,比如说以Yolo节点补充动态批处理为例:
import asyncio
import ray
from ultralytics import YOLO
@ray.remote(num_gpus=0.25)
class YOLOActor:
def __init__(self, model_path="yolov8n.pt", max_batch_size=8, max_wait_ms=10):
self.model = YOLO(model_path)
self.max_batch_size = max_batch_size
self.max_wait = max_wait_ms / 1000.0
self._queue = None
self._worker = None
def _ensure_worker(self):
if self._queue is None:
self._queue = asyncio.Queue()
self._worker = asyncio.create_task(self._batch_loop())
async def _batch_loop(self):
while True:
first = await self._queue.get() # 阻塞等第一个请求
batch = [first]
start = asyncio.get_running_loop().time()
while len(batch) < self.max_batch_size:
remaining = self.max_wait - (asyncio.get_running_loop().time() - start)
if remaining <= 0:
break
try:
batch.append(await asyncio.wait_for(self._queue.get(), remaining))
except asyncio.TimeoutError:
break # 窗口到,不再等
await self._run_batch(batch)
async def _run_batch(self, batch):
paths = [b[0] for b in batch]
confs = [b[1] for b in batch]
futs = [b[2] for b in batch]
batch_conf = min(confs)
try:
loop = asyncio.get_running_loop()
# 前向是同步阻塞(但 torch 计算段释放 GIL),丢到线程池避免卡住攒批循环
results = await loop.run_in_executor(
None, lambda: self.model(paths, conf=batch_conf, verbose=False)
)
for res, conf, fut in zip(results, confs, futs):
fut.set_result(self._postprocess(res, conf)) # 按各请求自己的 conf 过滤
except Exception as e:
for fut in futs:
if not fut.done():
fut.set_exception(e) # 整批失败,逐个报错
@staticmethod
def _postprocess(res, conf):
dets = []
if res.boxes is not None:
for box in res.boxes:
c = float(box.conf[0])
if c < conf: # 批用了最小 conf,这里按自身阈值筛
continue
x1, y1, x2, y2 = box.xyxy[0].tolist()
dets.append({
"bbox": [round(x1, 1), round(y1, 1), round(x2, 1), round(y2, 1)],
"class": res.names[int(box.cls[0])],
"conf": round(c, 4),
})
return dets
async def infer(self, image_path: str, conf: float = 0.25):
self._ensure_worker()
fut = asyncio.get_running_loop().create_future()
await self._queue.put((image_path, conf, fut))
return await fut
ray.init()
actors = {"yolo": YOLOActor.options(name="yolo").remote()}
refs = [actors["yolo"].infer.remote(f"street{i}.jpg", conf=0.5) for i in range(16)]
for r in ray.get(refs):
print(r)
对于上述批处理过程也比较简单:在每个节点内部创建队列在限制时间内的所有请求同时往队列中补充,在队满之后直接交给模型处理即可
- 2、连续批处理
主要是用在大模型文本生成过程中,比如说一般大模型模型处理过程4: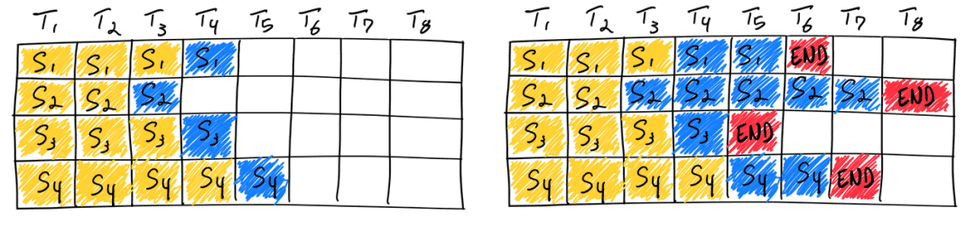
同时输入4个请求只有在最长的请求处理完毕之后这个批次才算解释,那么就会造成较大浪费,比如请求3在 $T_5$ 就已经处理完毕但是必须等到 $T_8$才能完成输出。那么 连续批处理过程就是优化这点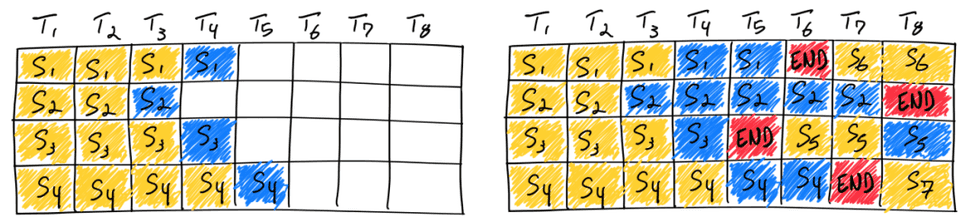
在 $S_3$ 在 $T_5$ 处理完毕之后下一秒直接将新的输入 $S_5$ 接着加入进来进行推理(保证时间利用最大化)。用下面列子解释过程,比如说bs=4其中ABC请求已经在生成处理,而请求E为新加入的请求其token长度为512,那么为了优化计算直接将4个请求就行拼接,那么此时输入形状为: [3+512,4096],将输入拆分为不同的头(假设num_heads=32)那么:[515, 32, 128],因为ABC这3个请求有KV-cache但是新的E是没有的那么:对于ABC这3组请求其KV为 [L+1, 32, 128](其中L为历史长度)而E则是 [512, 32, 128]
值得注意的是:KV维度和Q一致都是
[1,32,128]但是因为attention计算需要“之前内容”,因此就会把缓存的KVcache直接拿出来就行拼接也就是得到了[L+1, 32, 128]
并发分析
除去上面介绍的几种方法,在并发控制中对于N卡还可以使用MPS5或者MIG6机制就行处理(需要注意不是所有的卡都支持),对于这两种机制都是都是让一张 GPU 被多个任务共享的机制。在模型部署推理过程中需要区分当前过程中的上限在哪里一般需要分析的有:
FastAPI
可以简单理解为将你的程序“打包成服务”,别人可以直接通过端口去访问你的代码,一个最简单例子:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(title="fun-fastapi")
# 构建请求体
class SimpleComRequest(BaseModel):
a: int = Field(description="实数A")
b: int = Field(description="实数B")
@app.get("/v1/simple_com")
async def simple_com(request: SimpleComRequest):
return request.a+ request.b
@app.接口类型
一般而言 接口类型 如下几种,使用比较多的也就是get和post前者一般是获取信息,后者是提交任务
启动方式:一帮而言启动方式有两种:uvicorn main:app --port 8000 --host 127.0.0.1 --reload或者直接pyhton main.py其中第一种通过--reload参数保证代码修改之后自动重启服务不用每次都去手动启动服务,一般启动之后可以直接访问127.0.0.1:8000/docs去看所有的请求以及参数请求体:可以简答理解为“函数参数”,别人调用你的服务用什么参数(对于参数越详细描述越好)
补充内容,除去上面使用的几种方式之外,实际开发过程中还会遇到如下几种场景:
1、实时交互,比如说我的模型都部署在服务器,但是我如果做实时视频监控识别/实时语音转录,此时就需要使用 websocket 功能(可以简单理解为双发不断“交换数据”协议),使用其核心作用在在于 前端、后端、算法端进行交互,以ASR(实时语音转录为例)对于这3端功能简要概述如下:后端负责不停地搬 + 给控制信号,算法负责在连续流里找句子的起止并出字,前端则是负责不断进行渲染。对于 websocket和前面的 post 请求方式类似:发送请求–>模型处理–>返回请求。那么大致伪代码如下(开发过程中需要注意前后算法确定彼此之间传递参数):
音频处理过程主要流程:VAD(进行音频切分)–>ASR(进行音频转译)–>Punc(进行文本标点处理)
from fastapi import APIRouter, WebSocket, WebSocketDisconnect
router = APIRouter(prefix="/voice", tags=["voice-stream"])
# 请求端处理
@router.websocket("/stream/asr")
async def stream_asr(ws: WebSocket):
await ws.accept()
start = await asyncio.wait_for(ws.receive(), 60) # 持续从 ws 中接收
if ...:
# 发送错误信号
await ws.send_json({"type": "error"})
session = SessionProcess(...)
# 发送准备信号
await ws.send_json({"type": "ready"})
while True:
msg = await asyncio.wait_for(ws.receive(), 60) # 接受信息
data = msg.get("bytes")
if data is not None: # 音频帧:边收边出 partial/final
await session.feed(data)
continue
...
if t == "end":
await _send_frames(ws, await session.finish())
await ws.send_json({"type": "done"})
break
# 算法端处理
class SessionProcess:
def __init__(...):
self._pending = bytearray()
self.buf = bytearray() # 对于音频可能就需要去考虑进行缓存累加,比如说缓存 1s 音频再去进行ASR处理,对于图像可能使用队列更加方便。两种核心都是 消费-生产模型
...
async def feed(self, pcm: bytes):
"""接受数据-->缓存-->处理--->返回"""
# 对于音频可能
self.buf += pcm
self._pending += pcm
frames: List[dict] = []
while len(self._pending)...:
...
frames += await asr_process(...) # 主要返回字段 {"text":xxx}
return frames
从上面代码可以发现对于 websocket 而言主要是如下几个功能:1、接收(信息)过程:直接通过ws.accept() 接收客户端消息,ws.receive():接收消息,2、发送(信息)过程:发送和接受是相同的主要是发送2大类:文本帧以及 字节帧对于两者:
# 文本帧
{
"type": "websocket.receive",
"text": 'hello'
}
{
"type": "websocket.receive",
"text": '{"type":"start"}'
}
# 字节帧
{
"type": "websocket.receive",
"bytes": b'\x01\x02\x03\x04'
}
所以一般直接 ws.receive 而后后续直接 msg.get("text")或者 msg.get("bytes") 获取不同类型结果。
Docker
安装配置好docker之后运维国内监管可能需要去配置docker镜像
一句话介绍Docker作用:避免每次开发因为不同的开发环境问题而去抓狂。在docker中核心就是3部分组成:1、镜像(image);2、容器(container);3、dockerfile。对于这三部分实际上你可以简单的把image理解为可执行程序,container就是运行起来的进程。那么写程序需要源代码,那么“写”image就需要dockerfile,dockerfile就是image的源代码,docker就是”编译器”。因此我们只需要在dockerfile中指定需要哪些程序、依赖什么样的配置,之后把dockerfile交给“编译器”docker进行“编译”,也就是docker build命令,生成的可执行程序就是image,之后就可以运行这个image了,这就是docker run命令,image运行起来后就是docker container。
简单总结起来就是:dockerfile定义如何构建、image是构建后的模板、container是模板运行后的实例。首先我们编写 Dockerfile,用来描述项目需要什么环境、依赖以及启动方式;然后根据 Dockerfile 构建出 Image(镜像);最后通过 Image 启动 Container(容器)运行程序。Container 可以理解为一个相对独立、隔离的运行环境,因此能够避免“我电脑能跑,你电脑跑不了”的问题。
如果要去打包一个docker需要执行的处理(直接AI分析去写所有的文件即可),1、写Dockerfile(去docker里面都需要执行哪些操作直接提前安排好运行),Dockerfile核心语法就是如下几个:FROM:使用的镜像比如说用到Python/Linux/cuda等版本信息、WORKDIR:设置工作目录、COPY:复制文件、RUN:执行命令(比如说apt install以及 pip install等命令)、CMD:相当于终端执行;2、docker-compose.yml文件;3、.dockerignore。
除此之外一些docker常用的基本命令:
| docker命令 | 语法 |
|---|---|
| 查看版本 | docker --version |
| 镜像语法 | 查看镜像:docker images、下载镜像:docker pull nginx、删除镜像:docker rmi nginx 、构建镜像:docker build -t myapp .(直接在又Dockerfile文件里面去构建一个镜像) |
| 容器语法 | 启动容器:docker run nginx、查看运行的容器:docker ps、停止容器:docker stop 容器ID、删除容器:docker rm my-nginx |
| 查看日志 | docker logs my-nginx |
| 进入容器 | docker exec -it my-nginx bash(交互模式:-i、终端模式:-t) |
对于上述语法中启动容器 docker run xxx里面 xxx一般就是镜像名称,在构建镜像之后可以直接 run即可,一般而言run的参数。所以一般而言Docker启动命令如下:
# 1、首先构建docker镜像,直接基于本目录去构建
docker build -t xxx:xxx . # 其中 xxx:xxx 代表具体镜像名称 . 代表当前目录,也就是说基于当前文件夹 Dockerfile 去构建docker镜像
# 2、创建docker容器
docker run -d --name example \
--env-file .env.example \
-e PORT=59420 \
-v /data_share/model:/data_share/model \
-v /本地文件夹:/docker文件夹
-p 59420:8080 \
xxx:xxx
# example为具体容器名称 xxx:xxx 为镜像名称 -p 分别代表本地端口:docker端口,也就是说docker内部放行8080走本地59420去访问 -v 去挂载目录,一般就是项目代码/模型权重
# 3、容器使用
docker logs example # 查看日志
docker stop example # 停止容器
docker rm -f example # 停止容器
docker rmi xxx:xxx # 删除镜像
docker exec -it <容器名称或ID> /bin/bash # 进入容器
除去常用的docker语法,在使用过程中一般而言需要容器的“热重启”(本地修改–>容器自动修改)因此在启动容器时候就需要将本地文件进行挂载(使用参数 “-v” 即可),对于 Dockerfile 中 CMD 一般使用过程中我的 bash 脚本会去使用部分参数比如在使用fastapi中去使用端口等,在启动容器时候只需要 -e 脚本参数
| //: # ( DISP ==> | Ray RPC(跨机) | AC2) |
| //: # ( DISP ==> | Ray RPC(跨机) | AC3) |
| //: # ( DISP ==> | Ray RPC(跨机) | AC4) |
| //: # ( DISP ==> | Ray RPC | LLM) |
Ray
一句话介绍Ray:主要是进行分布式计算 / 并行计算的开源框架,核心目标是:让你用“写本地 Python 的方式”,轻松把程序扩展到多台机器上运行(切记如果服务不涉及到多台府服务器协同/不是高并发不一定要用Ray)。不过Ray只负责管理核心计算还是Pytorch进行。 Ray 架构简单介绍,参考官方v2架构说明7简单介绍Ray架构设计,其中Ray 的架构可以拆解为五个核心组件:
Ray 核心组件
1. Node 组件:Head Node 与 Worker Node
Ray 集群由两类节点组成:
- Head Node(头节点):集群的”大脑”。除了运行工作负载外,它还负责管理集群的全局状态(通过 GCS)、调度任务、运行 Dashboard 和 Autoscaler。它是集群中唯一知道所有节点信息的节点。
- Worker Node(工作节点):集群的”手脚”。不参与全局决策,只负责接收 Head Node 分配的任务并执行。每个 Worker Node 上运行一个 Raylet 进程,负责本地的任务调度和资源管理。
可以把 Head Node 理解为建筑工地的总指挥,Worker Node 是各个工种的施工队——总指挥分配任务,施工队埋头干活。
2. Scheduler(调度器)
Ray 采用自底向上的分布式调度策略,调度逻辑分散在两层:
- Global Scheduler(全局调度器):运行在 Head Node 的 GCS 中。它维护全局资源视图(哪个节点有空闲 GPU/CPU/内存),当本地调度器无法满足任务时接管调度。
- Local Scheduler(本地调度器,即 Raylet):每个节点一个。优先在本地满足任务请求(减少数据传输),只有本地资源不足时才把任务”上报”给全局调度器。
这种设计避免了传统中心化调度的瓶颈——大多数任务的调度决策在本地就完成了,延迟极低。
3. Object Store(分布式对象存储)
Ray 基于 Apache Arrow / Plasma 实现了内存中的分布式对象存储,是 Ray 高性能的关键:
举个直观的例子:Worker A 在节点 1 上产生了一个 10GB 的 tensor,Worker B 在同一节点上可以直接”看到”它,就像两个线程共享同一块内存一样。
- 每个节点上运行一个 Object Store 进程(
plasma_store),通过共享内存提供零拷贝的数据访问。 - 同一节点上的多个 Worker 进程可以通过共享内存直接读写同一份对象,无需序列化/反序列化。
- 跨节点的数据传输是惰性的——只有当某个节点的 Worker 真正需要某个对象时,才会从其他节点拉取。
4. Global Control Store(GCS,全局控制存储)
GCS 是 Ray 的分布式键值存储,运行在 Head Node 上,是整个系统的”中枢神经系统”:
- 存储集群元数据:节点列表、存活状态、资源总量。
- 存储系统状态:哪些 Actor 在哪个节点、函数定义、对象的位置信息(存储在哪个节点的 Object Store 上)。
- 提供 Pub/Sub 机制:当某个事件发生时(如节点故障、Actor 创建/销毁),GCS 会通知订阅者。
GCS 本身是一个 Redis-like 的 KV 存储,所有组件通过它与集群的”全局知识”交互。
5. Raylet
Raylet 是运行在每个节点上的守护进程(用 C++ 实现),是节点级的”管家”,负责三件事:
| 职责 | 说明 |
|---|---|
| 本地调度 | 从 GCS 拉取任务队列,根据本地资源状态分配给 Worker |
| 资源管理 | 跟踪本节点 CPU/GPU/内存的实时使用情况,向 GCS 汇报 |
| 对象管理 | 管理本地 Object Store 中的对象生命周期(引用计数、淘汰策略) |
Raylet 的设计理念是”让每个节点自治”——即使 Head Node 暂时不可达,Worker Node 上的 Raylet 依然能继续调度本地的任务和执行中的 Actor。简单任务介绍一下上述过程:比如说使用Ray进行贝叶斯调参过程,假设我们一块CPU假设32个核心我们并行4组参数执行,每组任务拥有5个核心,那么此时我们就有4个Worker node,Head Node内部处理过程:去控制每次贝叶斯下一次的参数(比如说RF中节点数量等)那么此时计算出4组优化参数(如n、depth等),通过GCS(比如说告诉目前迭代轮次、指标等) 将任务写入队列,Scheduler 根据资源视图把任务分配到 4 个 Worker。每个Worker内部处理过程 :各 Worker 的 Raylet 分配 5 个核,启动训练 → 结果写入本地 Object Store。 Head Node 拿到 4 个准确率 → 更新 GCS 中的历史记录 → 贝叶斯优化器计算下一轮参数 → 循环。
对于普通训练过程可能是:初始化参数–>进行参数计算得到效果–>贝叶斯优化器决定下一组参数–>循环
Ray Core
简单使用
Ray Core 是 Ray 的底层编程接口,上层的 Ray Data、Ray Train、Ray Tune 都建在它之上。它只做一件事:把”本地 Python”翻译成”集群上并行跑”。要理解它,先记住一个核心动作 .remote():凡是加了它的调用都不阻塞,立刻返回一个 ObjectRef(可以理解为”取餐号”——任务还没好,但你先拿到了凭证),真正要结果时再用 ray.get() 凭号取餐。围绕这个动作,Ray 给了三个原语,解决三个递进的问题:
| 原语 | 一句话 | 解决什么问题 | 状态 |
|---|---|---|---|
| Task | 远程函数 | 把一次性计算丢到别的核/机器上并行跑 | 无状态 |
| Actor | 远程类实例 | 让”加载一次、反复调用”的东西常驻 | 有状态 |
| Object | 远程数据引用 | 让大数据在节点间零拷贝流转,不重复传 | —— |
1、Task:把函数变成可并行的任务
最常见的需求:我有个函数要跑很多遍(不同参数),每遍互不相关,想并行。@ray.remote 就把普通函数变成”远程任务”。
import ray
@ray.remote # 装饰器:把函数注册为 Ray Task
def train_rf(n_estimators, max_depth):
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
model.fit(X_train, y_train)
return model.score(X_val, y_val)
# .remote() 发起任务:非阻塞,立刻返回 ObjectRef(取餐号)
refs = [train_rf.remote(n, d) for n, d in param_combinations]
# ray.get() 凭号取餐:阻塞,等所有结果回来
scores = ray.get(refs)
关键点:
for循环里的 4 个.remote()几乎瞬间执行完,因为它们只是”把任务提交出去”。4 个训练是在 4 个 Worker 上同时跑的,不是排队跑的。
对应到架构:@ray.remote 的函数定义被 GCS 记录 → 调用 .remote() 时 Scheduler 挑一个空闲 Worker 执行 → 返回值放进 Object Store,ray.get() 时取回。何时用:无状态的批量计算——批量调参、批量数据处理、Map 阶段。
2、Actor:把”加载一次”的东西常驻下来
Task 的问题:它是无状态的,每次调用都从零开始。如果每个任务都要先 YOLO("yolov8n.pt") 加载几百 MB 模型再推理,加载开销会把你拖死。Actor 解决这个问题——它是一个有状态、长期活着的 Worker:模型在 __init__ 里加载一次,常驻显存,之后每次 infer 直接用。
import ray
from ultralytics import YOLO
@ray.remote(num_gpus=0.25) # 声明为 Actor,并分配 1/4 张 GPU
class YOLOActor:
def __init__(self, model_path="yolov8n.pt"):
self.model = YOLO(model_path) # 只加载一次,常驻 GPU
def infer(self, image_path: str, conf: float = 0.25):
"""对图片做目标检测,返回 bbox + 类别 + 置信度。"""
results = self.model(image_path, conf=conf, verbose=False)
dets = []
if results[0].boxes is not None:
for box in results[0].boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
dets.append({
"bbox": [round(x1, 1), round(y1, 1), round(x2, 1), round(y2, 1)],
"class": results[0].names[int(box.cls[0])],
"conf": round(float(box.conf[0]), 4),
})
return dets
# 方式一
# 创建 Actor 实例:部署到某个 Worker,占用 0.25 张 GPU,模型在此刻加载
detector = YOLOActor.remote("yolov8n.pt")
# 调用方法:.remote() 仍然非阻塞,ray.get() 取结果
ref = detector.infer.remote("street.jpg", conf=0.5)
results = ray.get(ref)
# 方式二
ray.init()
model_class = {"yolo": YOLOActor}
actors = {}
for name, cls in model_class.items():
# 将所有的节点加入到cluster中
actors[name] = cls.options(name=name).remote()
model_a_ref = actors["yolo"].infer.remote("street.jpg", conf=0.5) # 传递参数给节点
print(model_a_ref, ray.get(model_a_ref)) # 获取节点结果
对于通过ray修饰的类在获取结果上先通过
Task vs Actor 的本质区别,看这张时序图(注意 __init__ 只发生一次):
脚本进程 Ray Worker 进程 (持有 GPU)
│ │
├─ detector = YOLOActor.remote(...) ──────→│ 创建 Actor,执行 __init__
│ │ YOLO(...) 加载到 GPU(仅此一次)
│ │ 模型常驻,等待调用
│ │
├─ ref_a = detector.infer.remote("a.jpg")─→│ 直接推理(不再加载模型)
├─ ref_b = detector.infer.remote("b.jpg")─→│ 排队(受 max_concurrency 限制)
│ │
├─ ray.get(ref_a) ←────────────────────────┤ 从 Object Store 取结果
└─ ray.get(ref_b) ←────────────────────────┤
对应到架构:Actor 的生命周期由 GCS 管理,所在节点的 Raylet 为它分配资源、调度它的方法调用。何时用:需要”加载一次、反复用”的有状态场景——模型推理服务、维护计数器/缓存、有内部状态的流式处理。
3、Object:让数据在集群里零拷贝流转
前两个原语传的是”任务”,这个原语传的是”数据“。问题场景:你有个 10GB 的数据集,要被 4 个 Task 共用。如果每次 .remote(dataset) 都把它序列化、复制一份传过去,4 份 40GB,内存直接爆。ray.put() 把数据放进 Object Store 一次,返回一个 ObjectRef(指针),之后所有任务传这个引用就行,同节点的 Worker 直接共享内存读,零拷贝。
data_ref = ray.put(large_dataset) # 放入 Object Store,返回引用(只存一份)
# 把"引用"传给任务,而不是数据本身
refs = [train_rf.remote(data_ref, params) for params in grid]
results = ray.get(refs) # 同节点零拷贝;跨节点才惰性拉取
其实你前面用
ray.get(refs)取 Task / Actor 的结果时,背后就是 Object Store 在工作——所有.remote()的返回值都自动存在 Object Store 里。ray.put只是让你手动把”输入数据”也放进去。
对应到架构:这就是前面 Object Store 组件讲到的——同节点共享内存零拷贝,跨节点惰性传输(谁用到才拉)。何时用:多个任务共享同一份大数据(数据集、大权重、配置),避免重复传输。
一句话总结 Ray Core:@ray.remote 把函数变 Task、把类变 Actor;ray.put/get 让数据通过 ObjectRef 在集群里透明流转。三者都靠 .remote() 异步发起、ray.get() 同步取回。理解了这三者,就理解了 Ray 的编程基础。除此之外,实际使用还绕不开两个配套能力:
1、资源分配,在 @ray.remote 装饰器里直接声明资源占用,如 @ray.remote(num_gpus=0.5, num_cpus=2)。注意 num_gpus=0.5 是软配额——Ray 只负责”按比例调度”,不强制隔离显存,靠你自己保证同卡上多个 Actor 显存加起来不超。支持的参数配置
2、并发控制,Actor 默认串行执行方法(一次一个),用 @ray.remote(max_concurrency=N) 可让单个 Actor 同时处理 N 个请求——配合上面的软配额,同一张卡上多个服务就能真正并发吃满 GPU。
参考
https://docs.python.org/zh-cn/3/howto/a-conceptual-overview-of-asyncio.html#a-conceptual-overview-of-asyncio ↩
https://www.anyscale.com/blog/continuous-batching-llm-inference ↩
https://docs.nvidia.com/deploy/mps/latest/quick-start.html ↩
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/latest/index.html ↩