模型微调过程中当有多卡时候就离不开进行分布式训练,本文主要介绍几种常见的分布式训练方式以及其基本原理:
分布式训练实现
各类分布式训练方式实现。
常见的分布式训练
1、数据并行(DP)
DP流程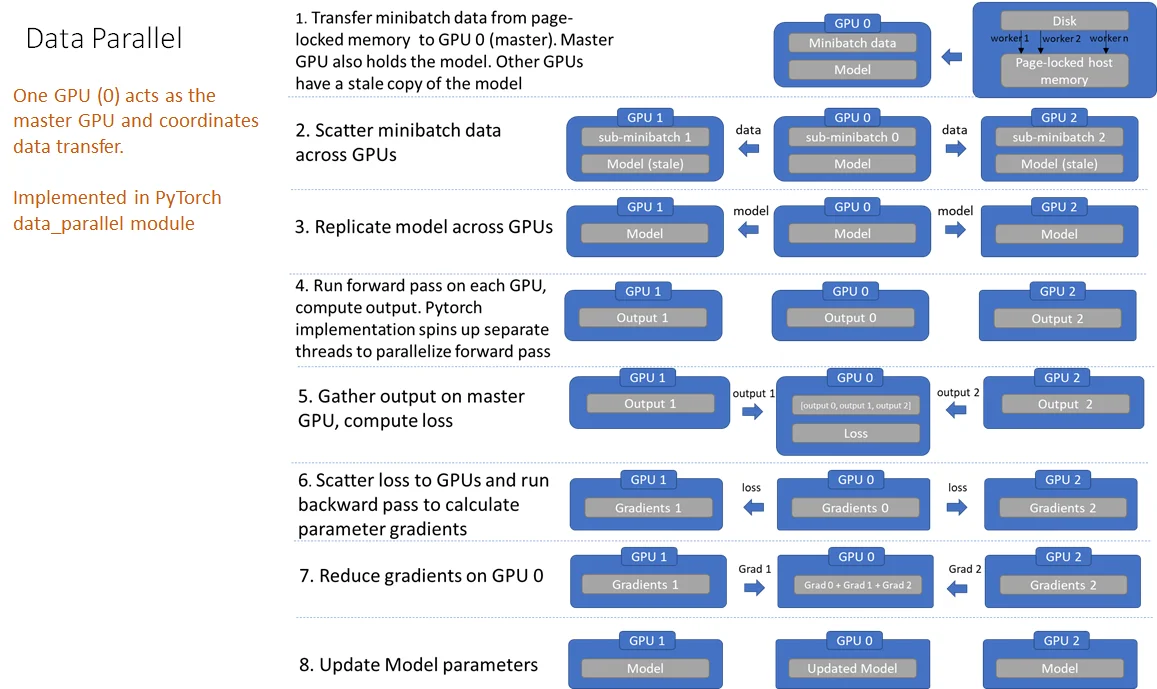
缺点也是显而易见:
- 1、数据副本会冗余(因为要把数据先复制,然后进行分布);
- 2、前向传递前在 GPU 上复制模型(由于模型参数是在主 GPU 上更新的,因此必须在每次前向传递开始时重新同步模型);
- 3、GPU 利用率不均衡(损失计算在主 GPU 上进行,在主 GPU 上进行梯度降低和参数更新
DDP流程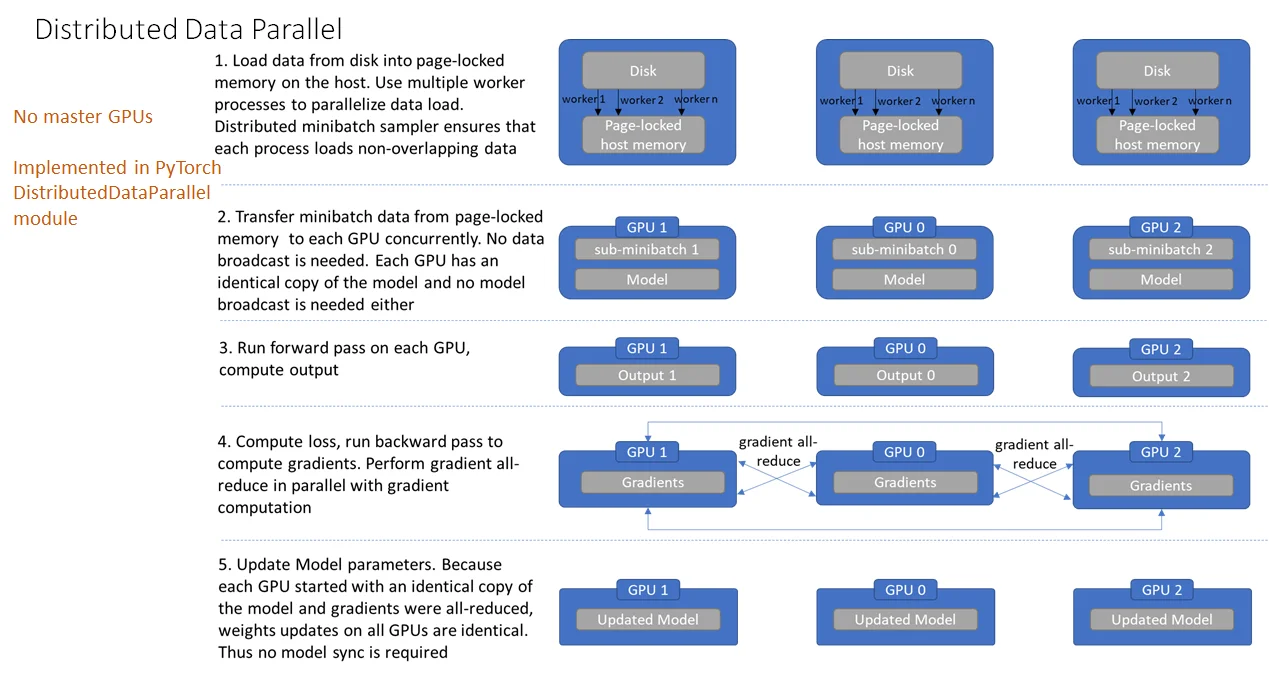
对比
DP和DDP1
1、DP是一种集中-分发机制(优化器/梯度计算都是再master进程上处理好之后,然后分发到不同的进程中)
2、DDP是一种独立-运行机制(每个进程都有自己的优化器,并且在计算梯度过程中:各进程需要将梯度进行汇总规约到主进程,主进程用梯度来更新模型权重,然后其broadcast模型到所有进程(其他GPU)进行下一步训练)
整体流程:
1、加载模型阶段。每个GPU都拥有模型的一个副本,所以不需要拷贝模型。rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的模型都拥有一样的初始化值。
2、加载数据阶段。DDP 不需要广播数据,而是使用多进程并行加载数据。在 host 之上,每个 worker进程都会把自己负责的数据从硬盘加载到 ` page-locked memory。DistributedSampler 保证每个进程加载到的数据是彼此不重叠的。 **3、前向传播阶段**。在每个GPU之上运行前向传播,计算输出。每个GPU都执行同样的训练,所以不需要有主 GPU。 **4、计算损失**。在每个GPU之上计算损失。 **5、反向传播阶段**。运行后向传播来计算梯度,在计算梯度同时也对梯度执行 all-reduce`操作。
由于数据实在不同设备上,但是是一个模型,对于梯度的计算可以:直接将不同设备之间梯度相互传播(每个设备的数据是不一样的,但是模型是相同的,这样计算梯度会不同),然后计算平均(
alll-reduce计算方法)
6、更新模型参数阶段。因为每个GPU都从完全相同的模型开始训练,并且梯度被 all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,也就不需要模型同步了。注意,在每次迭代中,模型中的 Buffers 需要从rank为0的进程广播到进程组的其它进程上
2、张量并行(TP)
张量并行目的是模型参数矩阵太大,需要将他们拆分到不同设备。张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)(权重矩阵按行分割)与列并行(Column Parallelism)(权重矩阵按列分割)。假设计算过程为:$y=Ax$ 其中 $A$ 为权重
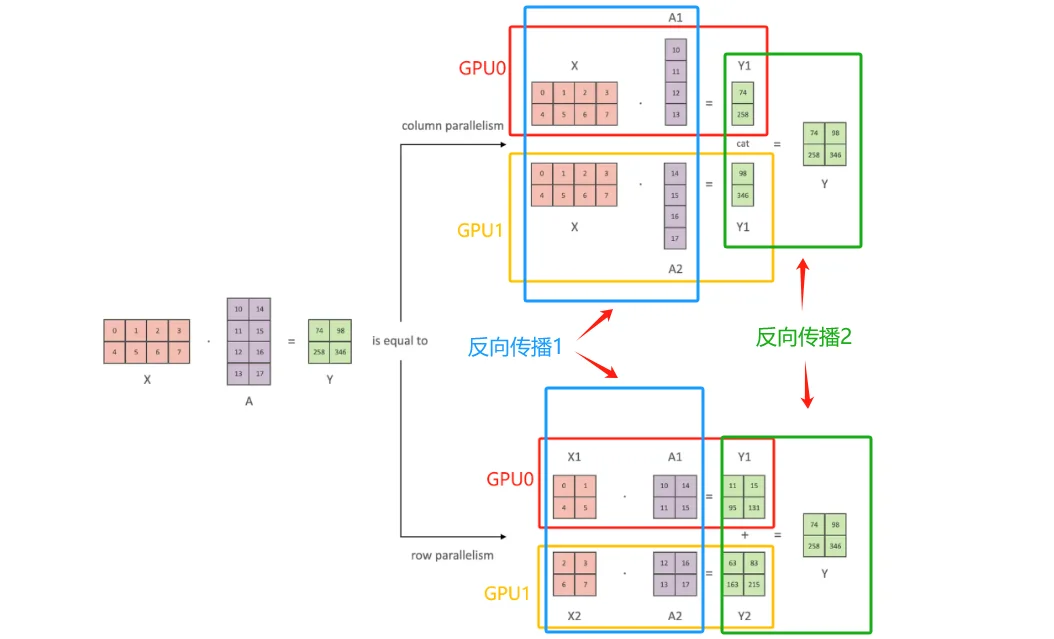
列并行操作:对我的权重矩阵按列进行切分而后分配到不同设备上
观察上面图像上半部分,forward部分容易理解,对于backward部分理解:第一部分计算(反向传播-1):得到两个新的Y1和Y2然后将他们进行拼接,计算梯度可以直接 $\frac{\partial L}{\partial Y_1} \frac{\partial L}{\partial Y_2}$ 得到梯度,第二部分计算(反向传播-2):由于x是完整的因此可以直接:
$\frac{\partial L}{\partial X}=\frac{\partial L}{\partial X}|{A_1}+\frac{\partial L}{\partial X}|{A_2}$
行并行操作:将输入x以及权重矩阵都按行进行切分分配到不同设备上
观察上面图像上半部分,forward分别对输入x以及参数A进行才分然后计算,对于backward理解:第一部分(反向传播-2):因为得到的Y是由两部分Y1和Y2直接相加得到结果,因此:$\frac{\partial L}{\partial Y_1}= \frac{\partial L}{\partial Y}$,第二部分(反向传播-1):$\frac{\partial L}{\partial X}=[\frac{\partial L}{\partial X_1}+\frac{\partial L}{\partial X_2}]$
对于 列并行操作由于x是完整的只需要通过 all-reduce操作(将不同设别的梯度信息“汇总”起来)。行并行操作:由于x都被拆分了,因此需要通过 all-gather(将不同GPU梯度聚合而后广播)
all-reduce、all-gather等见:All-Gather, All-Reduce, reduce-scatter什么意思?
3、流水线并行(PP)
当模型变得过大以至于单个设备无法容纳其任何一层,或者需要以不同方式重叠计算和通信时,流水线并行提供了一种替代的扩展策略。不同于复制整个模型或拆分单个层的方法,流水线并行将模型本身按顺序分配到多个设备上。每个设备或设备组都成为流水线中的一个“阶段”,负责运行模型层的一个子集。其内部并行的机制,如一个在四个GPU上运行的四层模型:
GPU 0 (阶段 0): 运行第 1 层。
GPU 1 (阶段 1): 运行第 2 层。
GPU 2 (阶段 2): 运行第 3 层。
GPU 3 (阶段 3): 运行第 4 层并计算损失。
输入数据进入第一阶段(GPU 0)。处理后,输出激活被发送到第二阶段(GPU 1)。这会一直持续,直到最后阶段计算出输出和损失。随后,梯度以相反的顺序反向流经流水线。GPU 3 计算第 4 层的梯度,并将第 3 层输出的梯度发回给 GPU 2,然后 GPU 2 计算第 3 层的梯度并将其发回给 GPU 1,依此类推,直到梯度到达第一阶段。在这个过程中会存在 “流水线气泡问题”:当阶段 1 处理第一个数据批次时,阶段 0 处于空闲状态,等待下一个批次。类似地,当阶段 2 处理时,阶段 0 和 1 处于空闲状态(假设只有一个批次流过)(backwards同理),常见两种处理方式:
3.1 GPipe实现流水线并行
GPipe23 将一个小批量(mini-batch)分割成多个微批量(micro-batch),使设备尽可能并行工作。其核心原理就是当每个分区处理完一个微型批次后,可以将输出扔给下一个分区,并立即开始处理下一个微型批次。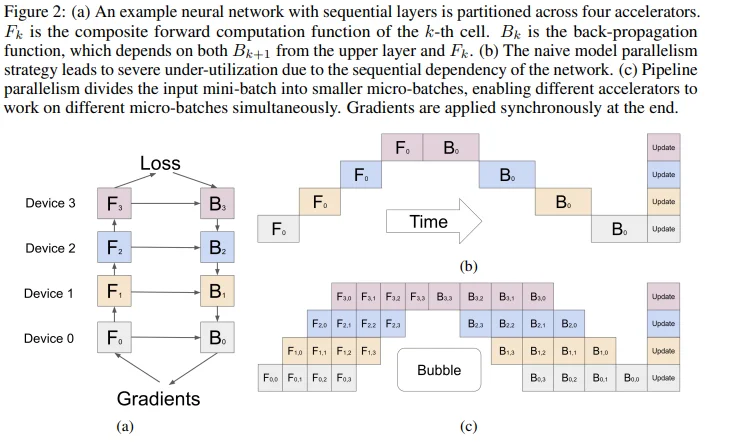
上图中b、c分别表示为 模型并行和 流水线并行都会有一个“拆分”的处理(模型并行和流水线并行都会对模型进行拆分,但模型并行主要关注模型的计算任务如何分布到不同设备,而流水线并行还结合了微批次化的数据处理,用于提升并行效率。),对比b-c很容易发现使用模型并行会有一个问题:设备闲置问题,只用第一层处理完之后才会进入到下一层,因此 流水线并行做的就是:在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练。
对比数据并行4
micro-batch 跟数据并行有高度的相似性:
1、数据并行是空间上的,数据被拆分成多个 tensor,同时喂给多个设备并行计算,然后将梯度累加在一起更新。
2、micro-batch 是时间上的数据并行,数据被拆分成多个 tensor,这些 tensor 按照时序依次进入同一个设备串行计算,然后将梯度累加在一起更新。
那么就会有存在一个问题:因为数据/模型被拆分,那么如何去处理梯度?对于上述两种方式,我们假设数据数量:10,然后设备个数:5,同时假设我们也将模型分布到这5个设备上,那么在 forawrd 阶段处理过程为:
数据并行:每个设备会处理2个数据(10/5)
流水线并行:因为模型分布在不同设备上(假设:$ld_1, ld_2, ld_3, ld_4, ld_5$),会有一个操作:将数据在拆分为不同 micro-batch(这里假设为5,得到:$md_1,md_2,md_3,md_4,md_5 $),这样一来随着前向传播:$t_0$ 时:$ld_1$ 处理 $md_1$;$t_1$ 时:$(ld_1, md_2), (ld_2, md_1)$( 值得注意的是 此处的md_1是由 ld_1处理完md_1得到结果,更加准确描述是:$(ld_2, ld_1(md_1))$)。
同理在 backward 阶段处理过程(对于 数据并行直接依次计算梯度即可 )为:在 forward 结束之后此时 流水线并行 中对于设备 ld_5 在 $t_9$: $ld_5$ 接收 Loss 传回的 $md_5$ 的梯度。它利用之前存的 $md_5$ 前向输入,重算一遍,算出 $W$ 的梯度。$t_{10}$: $ld_5$ 接收 Loss 传回的 $md_4$ 的梯度,重复上述动作。
如下图Gpipe中的forward 以及 backward 过程:
数据被切分成小的micro-batch,forward过程中一次将数据进行输入处理,在backward过程中则是依次将计算得到的梯度返回给上一层设备
不过值得注意的是,在Gpipe中存在 激活缓存机制:如果将每一个 micro-batch 计算结果都进行缓存会导致显存随 micro-batch 进行线性增长,因此在 forward 阶段丢弃中间保留边界,显存中只会保留 $md_i$ 的输入,在 backward阶段:即时计算,因为需要计算梯度那么直接将初始输入拿出来在计算 forward过程(也就是所谓的 gradient-checkpoint)。 以及 梯度累计机制:因为梯度更新必须是完整的一个batc处理之后才会进行(而我的数据都被拆分成小的micro-batch),因此在数据 $md_5 \rightarrow md_1$ 的过程中,激活缓存机制会不断的将梯度进行累积直到所有的数据处理完毕再进行参数更新。
gradient-checkpoint过程:
比如说:$x \xrightarrow{x_1} a_1 \xrightarrow{x_2} a_2 \xrightarrow{x_3} a_3 \xrightarrow{x_4} a_4$ 那么计算loss: $loss=(a_4- y)^2$朴素方法:$\frac{dloss}{dw_1}=\frac{dloss}{da_4} \times \frac{da_4}{da_3} \times \frac{da_3}{da_2} \times \frac{da_2}{da_1} \times \frac{da_1}{dw_1}$。前向过程需要计算并存储 $a_1, a_2, a_3, a_4$,反向时再调用这些激活值计算梯度。
梯度检查点:只存少量检查点,反向时若需要某个激活值但没有存储,则从最近的检查点重新计算前向。例如只保存 $a_1$ 和 $a_4$:
前向:正常计算 $a_1 \to a_2 \to a_3 \to a_4$,但只保存 $a_1$ 和 $a_4$,丢弃 $a_2, a_3$。
反向:
1、从 $a_4$ 开始反向,需要 $a_3$:从最近的检查点 $a_1$ 重新计算 $a_1 \to a_2 \to a_3$,得到 $a_3$ 后计算 $\frac{dloss}{dw_4}$ 和 $\frac{dloss}{da_3}$,然后丢弃 $a_2, a_3$。2、继续反向,需要 $a_2$:再次从 $a_1$ 重新计算 $a_1 \to a_2$,得到 $a_2$ 后计算 $\frac{dloss}{dw_3}$ 和 $\frac{dloss}{da_2}$,丢弃 $a_2$。
3、反向到 $a_1$:$a_1$ 已保存,直接使用计算 $\frac{dloss}{dw_2}$。
4、最后计算 $\frac{dloss}{dw_1}$ 使用输入 $x$。
效果:内存从存储 4 个激活值减少到 2 个,代价是增加了额外的重计算(本例中 $a_1 \to a_2 \to a_3$ 被计算了多次)。
梯度检查点(gradient checkpointing) 的工作原理是从计算图中省略一些激活值(由前向传播产生,其中这里的”一些“是指可以只省略模型中的部分激活值,折中时间和空间,陈天奇在它的论文使用了如下动图的方法,即前向传播的时候存一个节点释放一个节点,空的那个等需要用的时候再backword的时候重新计算)。这减少了计算图使用的内存,降低了总体内存压力(并允许在处理过程中使用更大的批次大小)。
简单使用:
from torchgpipe import GPipe
model = nn.Sequential(a, b, c, d)
model = GPipe(model, balance=[2, 2], chunks=8)
# 1st partition: nn.Sequential(a, b) on cuda:0
# 2nd partition: nn.Sequential(c, d) on cuda:1
for input in data_loader:
output = model(input)
对于 Gpipe 后续一个简单优化:因为梯度必须等所有 forward 处理完才会进行 backward 处理效率太低除此之外因为需要缓存 m 份 activation导致内存增加。原因是每个microbatch前向计算的中间结果activation都要被其后向计算所使用,所以需要在内存中缓存。,可以让模型交替执行 forward 和 backward(也就是 1F1B策略)
3.2 PipeDream 实现流水线并行

在论文5中提出在权重更新过程中存在问题:
1、同一个minibatch的前向传播和后向传播使用的参数不一致:比如在 Machine1上输入数据5时,用的是数据1的更新后参数,依次类推到数据5梯度更新时用的是1、2、3、4这4组数据梯度,这就导致 minibatch 5 的前向计算和后向计算时候,使用的参数不一致。即,第一行 Machine 1,蓝色 5 号 和 绿色 5 号 计算时候,必须都使用 绿色 1 号之后更新的参数。
2、同一个数据在不同Machine上做同样操作(同样做前向操作,或者同样做后向传播)使用的参数版本不一致。如对于 数据 5 在 machine 1 上的前向计算部分(蓝色5),他的前向逻辑在 数据1 的后向计算以后执行。但是 数据 5 在 machine 2 上的前向计算部分(蓝色5),是在 “数据 1, 数据 2” 的后向计算结束后才执行。这就导致了 数据 5 在两个stage上前向计算使用的参数版本不一致。
对于上述问题,其提出Weight stashing、Vertical Sync策略解决这个问题。Weight stashing过程如下:
PipeDream核心在于:同一个 micro-batch 的 forward 和 backward 使用同一份权重

以 数据5 为例:在forward中对于 Worker1 使用的是 数据1 更新后的权重,那么在 backward 中就需要去对 数据1 更新后权重进行 backward,因此在Worker1中为了保证上述原理,就需要去缓存1-4的数据的权重(因为数据5 backward 之前还进行其他3组数据)也就是 $W_1^{(1)},…,W_1^{(4)}$,那么类似的对于Worker2就需要去缓存2-4的数据的权重依次类推。数据5 的 backward 必须使用它 forward 时对应的权重版本也就是将 $W_1^{(1)}$ 拿出来(如 数据5 在worker1 forward中计算是:$o = W_1\times \text{Data}_5$ 那么 backward 时需要将 $W_1^{(1)}$ 拿出来)
Vertical Sync过程如下6:
每个进入管道的 数据 都与其进入流水线输入阶段时候的最新权重版本相联系。当小批次在流水线前向传播阶段前进时候,这个版本信息随着激活值和梯度一起流动。比如说上图中,强制所有worker在计算 minibatch 5 的时候都用本worker做 minibatch 1 反向传播之后的参数,具体来说就是:对于 worker 2,使用本阶段绿色1(1反向传播之后,更新的本阶段权重)来做 5 的前向传播。但是,这样同步会导致很多计算浪费无用。比如5更新时用的1的权重,但2/3/4后向传播的权重都白白计算了,所以默认不使用Vertical Sync。这样虽然每层不完全一致,但是由于weight stashing的存在,所有的参数都是有效的。
4、专家并行
状态切分优化显存
以上述DDP训练过程为例,为了更大限度的榨干设备显存(让其可以接受更加大的数据输入,而在模型训练过程中以Adam优化器为例在显存占用上:模型参数、优化器状态、梯度这三个是显存占用大头,那么为了优化就需要对其进行切分,每台设备只保存部分信息),就可以考虑使用 DeepSpeed 以及 toch原生的 FSDP2方式去对模型/梯度/优化器状态的分布式分片,除此之外对于更加大的模型可能就会考虑直接使用 混合并行(多种分布式训练叠加)
DeepSpeed
简单回顾一下DeepSpeed中基本原理,在 DeepSpeed中指出模型训练过程中显存占用上主要分为如下3块(假设模型的参数为 $\Phi$,使用混合精度训练,对于参数以及梯度会用fp16而对于adam优化器则是fp32):1、模型参数( $2\Phi$);2、梯度( $2\Phi$);3、优化器状态( $4+4+4\Phi$)
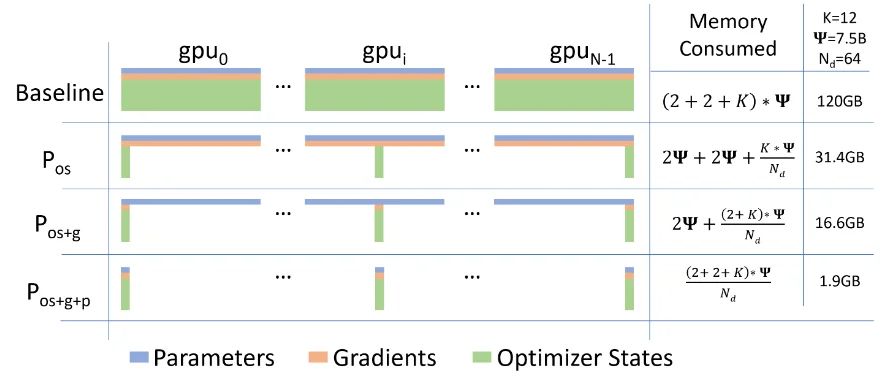
其中有3中不同的切分处理方式(上图从左到右), Zero-1直接去对优化器进行切分每个设备只保留部分;Zero-2:额外去对梯度进行切分;Zero-3:额外去对模型参数进行切分。除此之外还会涉及到不同设备之间的同步方式:All-reduce(聚合所有结果,然后计算平均比如DDP中就是使用All-reduce)、reduce-scatter、All-Gather(收集每张卡状态然后广播所有设备)。简单使用DeepSpeed进行分布式训练:
import deepspeed
...
deepspeed_config = {
"train_batch_size": 128,
"optimizer": {
"type": "Adam",
"params": {"lr": 1e-3}
},
"fp16": {
"enabled": True
},
"zero_optimization": {
"stage": 2
},
"gradient_accumulation_steps": 1,
"steps_per_print": 50
}
model = ...
model, optimizer, _, _ = deepspeed.initialize(
model=model,
config=deepspeed_config,
model_parameters=filter(lambda p: p.requires_grad, model.parameters())
)
for epoch in range(5):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(model.device), target.to(model.device)
outputs = model(data)
loss = ...
model.backward(loss)
model.step()
使用deepspeed十分简单,只需要提前配置好deepspeed的参数,而后将其通过deepspeed初始化处理(模型、优化器等),而后后续训练就和普通训练过程差异不大,model.backward(loss) 和 model.step() 已经自动管理了梯度清零,所以传统训练里必须用的 optimizer.zero_grad() 不需要显式调用。
FSDP
其在基本思想上和DeepSpeed相似都是选择去对3部分进行切分,可以简单理解为:PyTorch 原生的 ZeRO-3 实现,通过在前反向计算时临时 All-Gather 完整参数、计算后立即释放的方式,将参数、梯度、优化器状态均匀分片到所有 GPU 上,使显存占用从 O(N) 降至 O(1/N)。 简单使用FSDP进行分布式训练:
from torch.distributed.fsdp import (
FullyShardedDataParallel as FSDP,
ShardingStrategy,
StateDictType,
)
from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
apply_activation_checkpointing,
)
import torch.distributed as dist
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
model = ...
auto_wrap_policy = size_based_auto_wrap_policy # 基于参数数量的自动包装
model = FSDP(
model,
sharding_strategy=ShardingStrategy.FULL_SHARD, # ZeRO-3 行为
auto_wrap_policy=auto_wrap_policy,
use_orig_params=True, # 允许直接使用原始参数名
)
for epoch in range(5):
sampler.set_epoch(epoch)
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(data)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()