扩散模型生成加速策略
Diffusion推理加速的方案,主要包括Cache、量化、分布式推理、采样器优化和蒸馏等。下面内容主要是去对Cache、计算加速框架以及量化技术进行介绍
SD模型加速方式:https://github.com/xlite-dev/Awesome-DiT-Inference?tab=readme-ov-file#Quantization
不过值得注意的是对于下面内容,首先介绍加速框架(这部分内容主要是介绍进行加速的一些小trick,主要是直接通过api去加速)、cache以及量化一般就会涉及到一些算法的基本原理。所有的测试代码:df_acceralate.ipynb
一般加速框架以及显存优化措施
下面介绍的
flash-attn、torch.compile属于通用的加速策略(llm、扩散模型都可使用)
这部分内容的话比较杂(直接总结huggingface内容),1、直接使用attn计算加速后端,比如说一般就是直接使用比如说flash_attn进行attention计算加速,比如说:
pipeline.transformer.set_attention_backend("_flash_3_hub") # 启用flash attn计算加速
pipeline.transformer.reset_attention_backend() # 关闭flash attn计算加速
不过值得注意的是_flash_3_hub 只支持非hopper架构,因此可以直接就使用set_attention_backend("flash")。2、直接使用torch.compile进行加速(对于 compile 原理解释: pytorch使用-1:🔥Pytorch使用-1:Pytorch计算图概念),不过值得注意的是在开始使用过程中会比较慢,因为在执行时,它会将模型编译为优化的内核,所以相对会比较慢,但是如果对编译后模型进行批量测试在时间上就会有所提升比如说在代码df_acceralate.ipynb中测试结果使用compile在z-image上生成5张图片耗时:86.49s(平均生图时间4s)不使用compile:29.92(平均生图时间5s);3、使用torch.channels_last去优化数据结构(torch文档):最主要的一点是通过channel_last让 GPU 在计算卷积 / attention 时,内存访问更连续,比如说一般数据的输入是NCHW那么在内存访问中格式是:N0C0H0W0, N0C0H0W1, ..., N0C0H1W0, ...这个里面通道C变化最慢,使用channel_list数据格式变为NHWC在内存中访问顺序是:N0H0W0C0, N0H0W0C1, N0H0W0C2, ...值得注意的是两部分数据在shape上是一致的只是strid不一致。使用方式也比较简单:
# 修改模型
model = model.to(memory_format=torch.channels_last)
# 修改输入
input = input.to(memory_format=torch.channels_last)
output = model(input)
...
pipeline.unet.to(memory_format=torch.channels_last)
1、xFormers加速
在SD模型中对于xformers基本使用方式如下所示:
import torch
from diffusers import StableDiffusionXLPipeline
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
# 使用xformer加速
pipeline.enable_xformers_memory_efficient_attention()
# 关闭xformer加速
pipeline.disable_xformers_memory_efficient_attention()
xformers作用在于加速attention计算并降低显存,除此之外还提供了多种注意力实现方式,如casual attention等。根据官方文档中的描述,对于对于xformers.ops.memory_efficient_attention在使用上参数主要是:1、输入数据也就是QKV的格式上必须满足为:[B, M, H, K]分别表示的是其中B 为batch size, N为序列长度, num_heads为多头注意力头的个数, dim_head则为每个头对应的embeding size;2、attn_bias实际上充当为在使用mask attention时的mask;3、p也就是dropout对应值;4、op为Tuple,用于指定优化self-attention计算所采用的算子。基本使用方式如下:
import xformers.ops as xops
y = xops.memory_efficient_attention(q, k, v)
y = xops.memory_efficient_attention(q, k, v, p=0.2) # 使用dropout
y = xops.memory_efficient_attention(
q, k, v,
attn_bias=xops.LowerTriangularMask()
)# 使用casual 注意力
值得着重了解的就是其中attn_bias参数,简单直观的理解:用于控制注意力可见性和结构的统一接口,既可以表示 mask,也可以表示稀疏/局部/因果等高级注意力模式,并且以高性能方式融入 attention 内核。比如说:
1、xops.LowerTriangularMask():常规的causal注意力也就是下三角mask
2、xops.LocalAttentionFromBottomRightMask:局部注意力,每个token只能看最近的window_size个token
2、显存优化
对于模型的显存过大可以考虑根据自身的设备进行分配,比如说将模型卸载到CPU或者将VAE等放到其它显卡上,在diffusers就提供了这些方法(这块内容直接问AI进行总结):
1、CPU卸载
它启用了一种极致级别的逐层(leaf-level / sequential)CPU offloading机制,核心思路是:把模型的计算图中最底层的参数(leaf modules,即最细粒度的子模块、层或权重块)默认放在 CPU 内存里存储。在前向传播(forward pass)过程中,只在真正需要计算某个具体层的时候,才把那一小块参数临时从 CPU 拷贝(onload)到 GPU。计算完这层之后,立刻把这块参数再 offload 回 CPU,释放 GPU 显存。然后再加载下一层,以此类推,一层一层顺序执行(sequential)。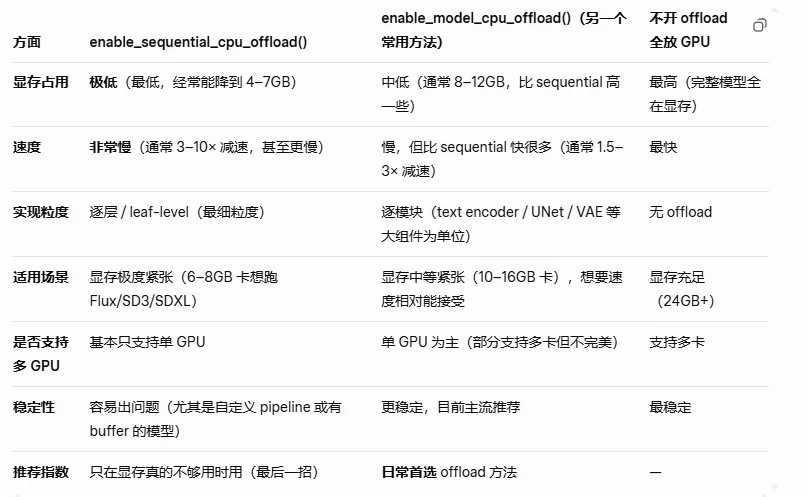
2、设备分配
这部分主要是将生成模型中不同模型结构如VAE、CLIP去分配到其它显卡上:
import torch
from diffusers import AutoModel, StableDiffusionXLPipeline
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
device_map="balanced" # 使用balance就可以实现不同设备分配
)
print(pipeline.hf_device_map)
{'unet': 1, 'vae': 1, 'safety_checker': 0, 'text_encoder': 0}
亦或者直接自己定分配:
import torch
from diffusers import AutoModel
device_map = {
'pos_embed': 0, 'time_text_embed': 0, 'context_embedder': 0, 'x_embedder': 0, 'transformer_blocks': 0, 'single_transformer_blocks.0': 0, 'single_transformer_blocks.1': 0, 'single_transformer_blocks.2': 0, 'single_transformer_blocks.3': 0, 'single_transformer_blocks.4': 0, 'single_transformer_blocks.5': 0, 'single_transformer_blocks.6': 0, 'single_transformer_blocks.7': 0, 'single_transformer_blocks.8': 0, 'single_transformer_blocks.9': 0, 'single_transformer_blocks.10': 1, 'single_transformer_blocks.11': 1, 'single_transformer_blocks.12': 1, 'single_transformer_blocks.13': 1, 'single_transformer_blocks.14': 1, 'single_transformer_blocks.15': 1, 'single_transformer_blocks.16': 1, 'single_transformer_blocks.17': 1, 'single_transformer_blocks.18': 1, 'single_transformer_blocks.19': 1, 'single_transformer_blocks.20': 1, 'single_transformer_blocks.21': 'cpu', 'single_transformer_blocks.22': 'cpu', 'single_transformer_blocks.23': 'cpu', 'single_transformer_blocks.24': 'cpu', 'single_transformer_blocks.25': 'cpu', 'single_transformer_blocks.26': 'cpu', 'single_transformer_blocks.27': 'cpu', 'single_transformer_blocks.28': 'cpu', 'single_transformer_blocks.29': 'cpu', 'single_transformer_blocks.30': 'cpu', 'single_transformer_blocks.31': 'cpu', 'single_transformer_blocks.32': 'cpu', 'single_transformer_blocks.33': 'cpu', 'single_transformer_blocks.34': 'cpu', 'single_transformer_blocks.35': 'cpu', 'single_transformer_blocks.36': 'cpu', 'single_transformer_blocks.37': 'cpu', 'norm_out': 'cpu', 'proj_out': 'cpu'
}
transformer = AutoModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="transformer",
device_map=device_map,
torch_dtype=torch.bfloat16
)
cache策略概述
cache指的是:缓存通过存储和重用不同层(例如注意力层和前馈层)的中间输出来加速推理,而不是在每个推理步骤执行整个计算。它以更多内存为代价显着提高了生成速度,并且不需要额外的训练。主要详细介绍两种:1、DeepCache;2、FORA。对于更加多的cache策略可以看知乎,推荐直接使用CacheDit来进行加速。
DeepCache策略
Paper:https://arxiv.org/pdf/2312.00858
Code:https://link.zhihu.com/?target=https%3A//github.com/horseee/DeepCache
主要针对UNet架构的Diffusion模型进行推理加速。DeepCache 是一种Training-free的扩散模型加速算法,核心思想是利用扩散模型序列去噪步骤中固有的时间冗余来减少计算开销。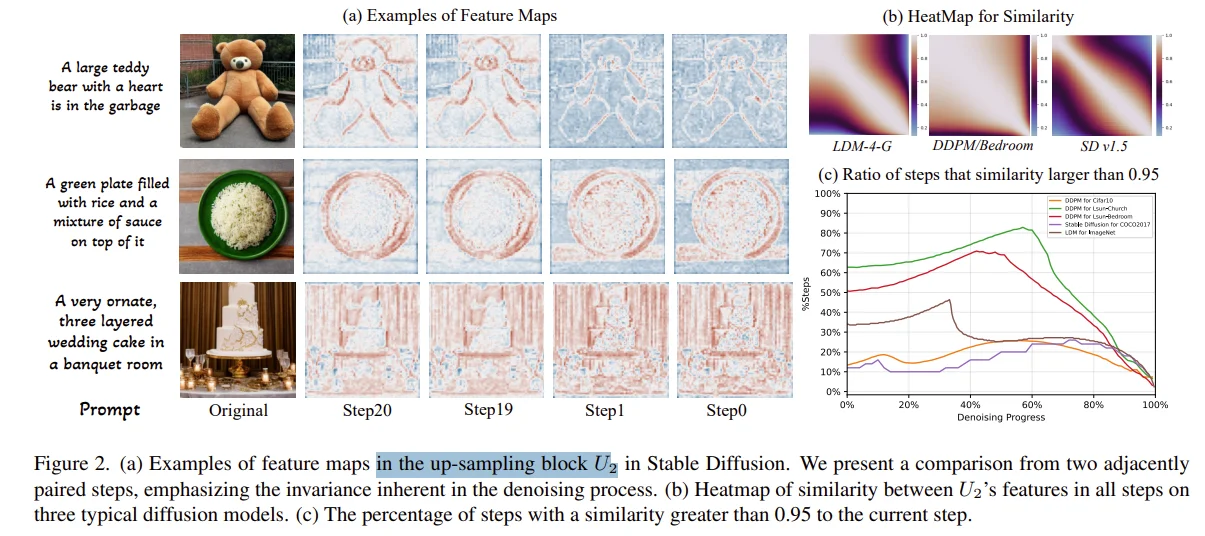
基于 U-Net 结构特性,发现相邻去噪步骤的高层特征具有显著时间一致性(Adjacent steps in the denoising process exhibit significant temporal similarity in high-level features.),比如说上图中作者在测试上采用block $U_2$的特征和其它所有的采样步之间相似性计算(图b),因此缓存这些高层特征并仅以低成本更新低层特征,从而避免重复计算。具体方法为: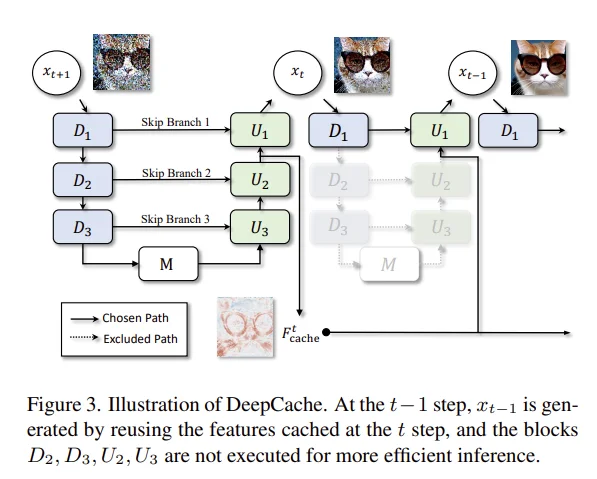
比如说在官方的使用中有参数:helper.set_params(cache_interval=3,cache_branch_id=0,)表示是每3个时间步进行一次完成forward然后刷新cache,而其中参数cache_branch_id值得是一般而言在UNet中会定义branch 0 → early / down blocks等就是选择哪些层的输出。具体过程如下:t=1进行计算缓存,t=2,3都直接使用缓存,t=4完整计算得到缓存。
FORA
Paper: https://arxiv.org/pdf/2407.01425
Code: https://github.com/prathebaselva/FORA
主要是争对Dit架构的Diffusion模型进行推理加速。利用 Diffusion Transformer 扩散过程的重复特性实现了可用于DiT的Training-free的Cache加速算法。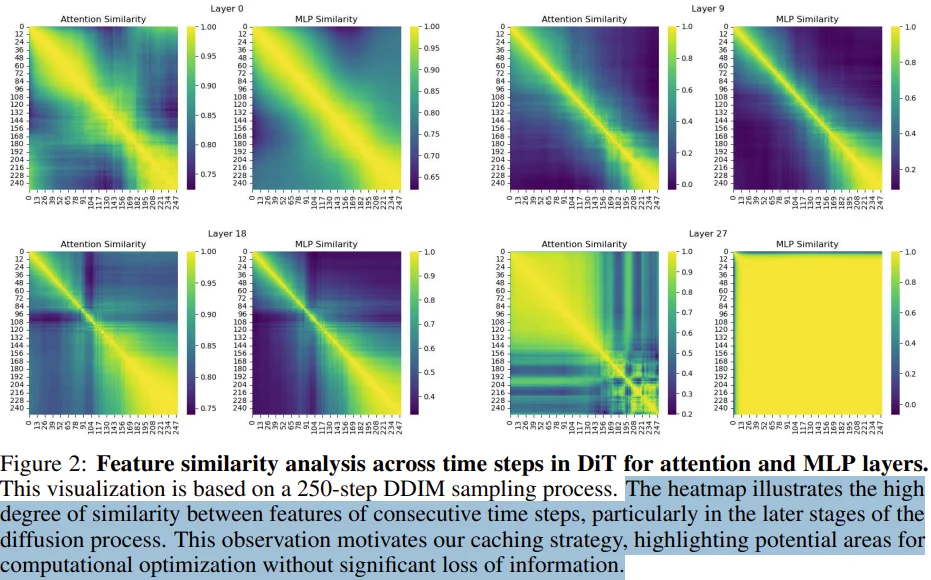
FORA的核心在于发现Dit在去噪过程中,相邻时间步的Attn和MLP层特征存在显著重复性(如上图所示:在layer0、9、18、27这些层以及250步采样中,随后采样步约往后特征之间相似性也就越高。)。通过Caching特征,FORA 将这些重复计算的中间特征保存并在后续时间步直接复用,避免逐步重新计算。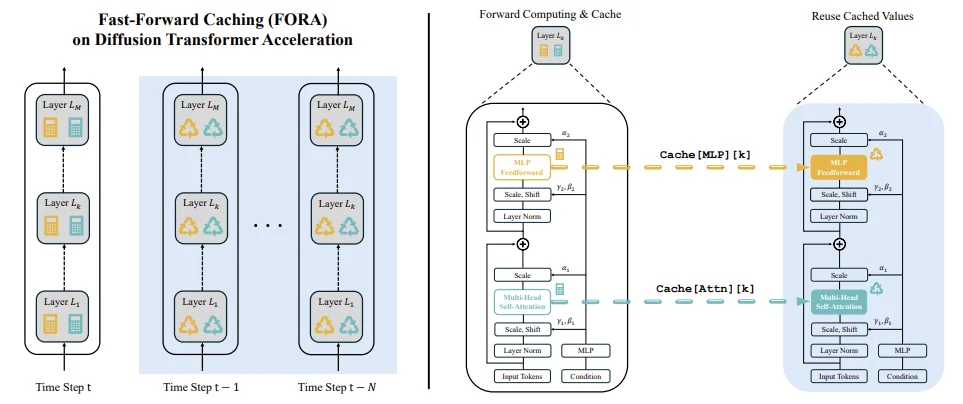
具体而言,模型以固定间隔 N 重新计算并缓存特征:当时间步 t 满足 t mod N=0 时,更新所有层的缓存;在后续 N-1 步中,直接检索cached的 Attn 和 MLP 特征,跳过重复计算。这种策略利用了 DiT 架构在邻近时间时间步的特征相似性,在不修改DiT模型结构的前提下实现加速。例如,在 250 步 DDIM 采样中,当 N=3 时,模型仅需在第 3、6、9… 步重新计算特征,其余步骤复用Cache,使计算量减少约 2/3。实验表明,FORA对后期去噪阶段的特征相似性利用更为高效,此时特征变化缓慢,缓存复用的性价比最高。
FBCache
项目地址:https://github.com/chengzeyi/ParaAttention/blob/main/doc/fastest_flux.md
通过缓存变换器模型中变换器块的输出,并在下一步推理中重新使用它们,可以降低计算成本,加快推理速度。然而,很难决定何时重新使用缓存以确保生成图像的质量。最近,TeaCache 提出,可以使用时间步嵌入来近似模型输出之间的差异。AdaCache 也表明,在多个图像和视频 DiT 基线中,缓存可以在不牺牲生成质量的情况下显著提高推理速度。不过,TeaCache 仍然有点复杂,因为它需要重新缩放策略来确保缓存的准确性。在 ParaAttention 中,发现可以直接使用第一个transformer输出的残差来近似模型输出之间的差异。当差值足够小时,我们可以重复使用之前推理步骤的残差,这意味着我们实际上跳过了去噪步骤。我们的实验证明了这一方法的有效性,我们可以在 FLUX.1-dev 推理上实现高达 1.5 倍的速度,而且质量非常好1。
简单来说就是上面提到的DeepCache/FORA在使用上太粗糙直接通过固定时间步去cache缓存这样忽视输出差异的非均匀性,因此后续的TeaCache发现模型输入与输出的强相关性,通过Timestep Emebdding(输入)来估计输出差异。而后FBCache又做了新的改进: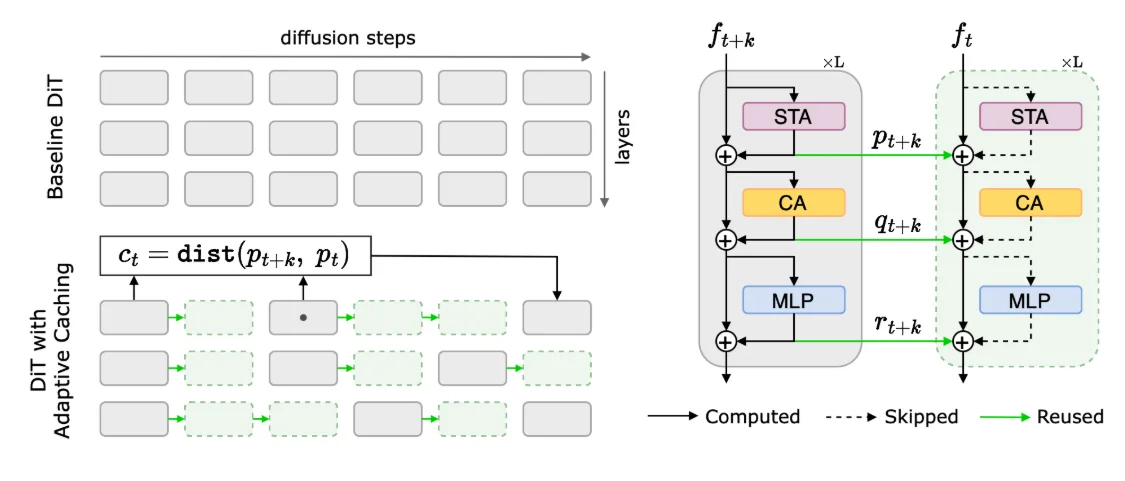
利用residual cache实现了一个基于First Block L1误差的Cache方案,误差小于指定阈值,就跳过当前步计算,复用residual cache,对当前步的输出进行估计。
CacheDit
cache-dit这个框架主要是适用于Dit结构的扩散模型使用,其具体模型框架如下: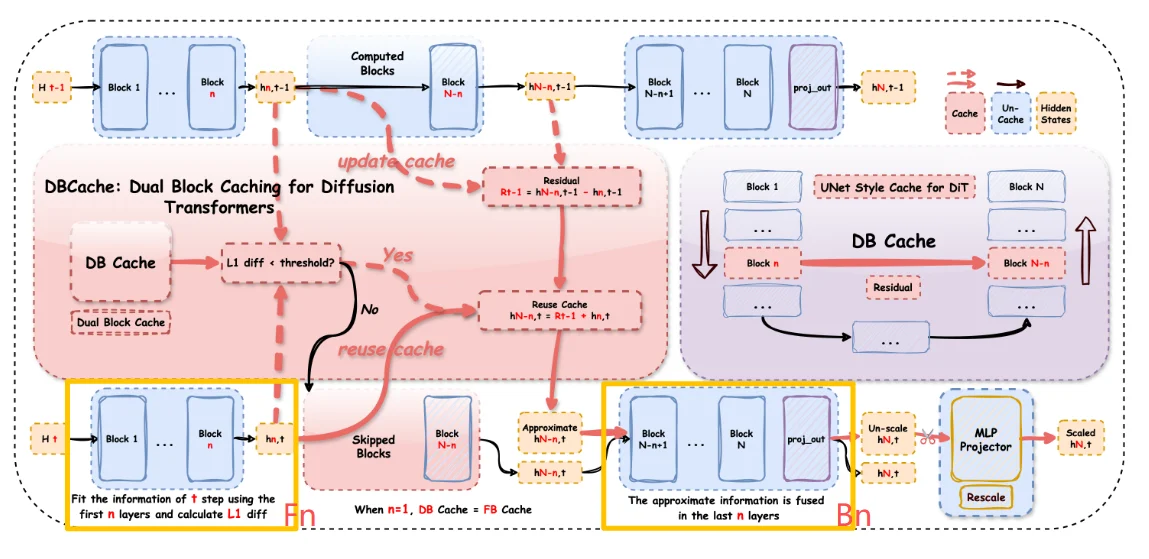
对于上述框架首先了解CacheDit中几个概念:1、Fn:表示需要计算前n层transformer block在时间步t计算得到结果;2、Bn:表示进一步的融合后n层transformer block的信息去强化预测准确性。其中n=1时候就是FBCache。
因此对于CacheDit具体过程为:在t-1步时候,前n块block去计算他们的结果得到输出结果hidden state并且写入缓存中$C_{t-1}$,而后后几层进行完整结算。在t步时候,前n块block不完整计算,而是直接复用/近似 t-1 步的缓存$C_{t-1}$得到近似的结果,计算近似结果和缓存结果中差异(L1 范数),如果差异小于阈值直接复用缓存输入到后续的块中计算,反之就重新计算这n块结果。
其中具体使用如下:df_acceralate.ipynb
简单总结上面过程就是,通过在前几个block(或第一个block)计算一个probe残差,然后与上一步缓存的残差做L1(或相对L1)差异比较,来决定当前步是否可以复用/跳过后续block的完整计算,从而实现加速。
扩散模型生成加速总结
本文主要是介绍一些在SD模型中加快生图的策略,1、直接使用加速框架进行优化,比如说指定attention计算后端方式、通过torch.compile进行编译、使用torch.channels_last去优化内存访问方式等;2、cache策略,发现在生成过程中在某些层/时间布之间图像的特征比较相似,因此就可以考虑将这些计算结果进行缓存在后续n步中直接加载缓存好的特征来实现生成加速,主要介绍框架是cache-dit;3、量化技术概述。最后简单对比一下生成加速时间
测试模型为
Tongyi-MAI/Z-Image-Turbo测试prompt:超写实亚洲中年男性,年龄约45-55岁。面容坚毅、憔悴,带有生活阅历的痕迹(如眼角的细纹)。他穿着质感柔软的深灰色高领毛衣,外搭一件经典的卡其色风衣,站在寒风中周围是高楼大厦
从测试结果上图像的差异还是不大,时间的话从5.97–>5.48(不一定严谨!)还是有效的
| 正常生图 | +使用channel+ flash_attn | +使用cachedit |
|---|---|---|
 |  |  |
5.97 | 5.67 | 5.48 |
通用加速策略
指的是在扩散模型、LLM中都可以使用道德加速策略,因为在扩散模型生成加速中介绍到了使用 flash-attn 以及 torch.compile 这两部分也属于通用的加速策略因为在扩散模型中介绍了下面不重复介绍。
基于量化加速策略
量化技术是一种模型压缩的常见方法,将模型权重从高精度(如FP16或FP32)量化为低比特位(如INT8、INT4)去实现降低显存+生成加速。量化过程的基本范式,量化过程:$Q=\frac{W}{S}$ 其中 $S$ 表示scale,反量化过程:$\hat{w}=QS$,因此对于量化只需要保存:1、量化后权重;2、scale值(不同量化模型计算方式不同)。比如说(对称量化过程)对于:1.21, -1.13, 0.22, 0.83, 2.11, -1.53, 0.79, -0.54, 0.84其中最大值为2.11那么可以计算出缩放系数为:$\frac{2.11}{127}=0.01661417$(127代表int8数值范围-127,127)那么可以对数据缩放(量化)得到:72, -69, 13, 49, 127, -93, 47, -33, 50反量化可以得到:1.19622024,....(直接乘scale即可)具体计算数字之间差异,都是存在误差的。
常见的量化策略可以分为PTQ和QAT两大类。量化感知训练(QAT):在模型训练过程中进行量化,一般效果会更好一些,但需要额外训练数据和大量计算资源比如说qlora(对模型权重NF4冻结,前向传播过程将NF4权重反量化到BF16计算完毕后丢弃,而Lora则是使用BF16进行训练)。后量化(PTQ):在模型训练完成后,对模型进行量化,无需重新训练。对于线性量化下,浮点数与定点数之间的转换公式如下:$Q=\frac{R}{S}+Z;R=(Q-Z)*S$,其中R 表示量化前的浮点数、Q 表示量化后的定点数、S(Scale)表示缩放因子的数值、Z(Zero)表示零点的数值。除此之外
比如说在LLM中常用的两种后量化技术(具体介绍:模型量化操作————GPTQ和AWQ量化):1、GPTQ量化技术:通过量化——补偿——量化迭代方法,首先量化$W_{:,j}$,而后去计算误差并且补充到 $W_{:,j:(i+B)}$而后进行迭代实现所有参数的量化;2、AWQ量化技术:模型计算过程中只有关键参数起作用因此对于关键参数保持原来的精度(FP16),对其他权重进行低比特量化,但是这样不同进度参数会导致硬件问题,因此在AWQ中对所有权重均进行低比特量化,但是,在量化时,对于显著权重乘以较大的scale,相当于降低其量化误差;同时,对于非显著权重,乘以较小的scale,相当于给予更少的关注。
补充一个小知识,一般量化看到比较多就是W4A4这个一般指的就是权重和激活的4bit量化,其中权重一般就是对应该层的模型权重,激活就是对应该层的输入
还会听到几个概念:1、非对称量化:是一种用于将浮点数转换为整数表示的量化方法。与对称量化不同的是,这种方法在数据具有偏移(即非对称分布)时更有效,因为它可以减少量化误差。非对称量化会分别找出浮点数的最小值和最大值,分别量化到目标整数范围的最小值和最大值,充分利用量化后的整数范围。这可以使用一个缩放因子(scale)和偏移量(zero-point)来实现2。
对于非对称量化在量化过程中首先计算量化值: scale 简单计算过程为:$\text{scale}=\frac{x_{\max}- x_{\min}}{q_{\max}- q_{\min}}$ 而后去计算零点(zero_point):$\text{zero_point}=\text{round}(q_{\min}-\frac{x_{\min}}{\text{scale}})$,在计算得到两部分量化值之后直接计算:$\text{quant_value}= \text{round}(\frac{fp16_value}{\text{scale}}+zero_point)$,返量化 就直接对上量化公式返计算即可。
2、对称量化:对称量化的核心思想是将浮点数量化为整数,且量化后的分布是关于零对称的,对称量化过程中零点呗固定一次只需要去计算缩放因子(scale):$\text{scale}=\frac{\max(\vert x_{\min} \vert, \vert x_{\max} \vert) }{(q_{\max}-q_{\min})/2}$
bitsandbytes 量化
通过使用 bitsandbytes量化 来实现8-bit(int8)或者4-bit(int4、Qlora中一般就会使用)量化,不过区别上面提到的AWQ以及GPTQ量化,bitsandbytes不需要对模型进行训练(AWQ、GPTQ可能需要输入数据然后计算误差进行量化),前者需要通过数据来保证量化精度(量化过程是离线、一次性过程),后者量化过程是即时的可逆的。其技术原理如下(以对称量化过程为例):$w≈s q$ 其中w表示原始的FP16权重,q代表int4/int8权重,s缩放因子,其量化过程为对每一个block权重计算:$\max(\text{abs}(w))$ 而后去计算scale:$s=\frac{amx(| w|)}{2^{b-1}-1}$ 而后代入公式就可以得到量化后权重,不过值得注意的是,在使用 Bitsandbytes 进行量化过程中对于上述提到参数计算过程:将权重 tensor 按固定块大小分割(默认 block_size=64 或 128 元素一块),每个块独立计算量化参数,在推理过程中进行:反量化 + 矩阵乘法融合在一个 CUDA kernel 中完成:$Y=X(sq)$。因此对于其使用也很简单,比如说在代码中:cache_acceralate.py
# 在ZImagePipeline中参数为:
class ZImagePipeline(DiffusionPipeline, ZImageLoraLoaderMixin, FromSingleFileMixin):
def __init__(,..,vae, text_encoder, tokenizr, transformer):
...
# 因此可以直接对里面的text_encoder使用量化处理
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
quantization_config = DiffusersBitsAndBytesConfig(
load_in_4bit=True,# 在模型加载阶段,将权重以 4-bit 量化形式加载
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,# 指定 反量化后参与计算的 dtype
bnb_4bit_use_double_quant=True,#启用 Double Quantization(双重量化),也就是对block的scale在进行一次量化
llm_int8_skip_modules=["transformer_blocks.0.img_mod"],# 指定 不参与 bitsandbytes 量化的模块
)
transformer = AutoModel.from_pretrained(
model_name,
cache_dir=cache_dir,
subfolder="transformer",
quantization_config=quantization_config,
torch_dtype=torch.bfloat16,
device_map="auto",
mirror='https://hf-mirror.com'
)
对你的model_name里面的transformer进行量化处理,除此之外还有使用例子就是进行优化器量化,比如说
# 和使用adamw方式一样,使用qlora使用一般带上这个优化器
import bitsandbytes as bnb
optimizer_class = bnb.optim.AdamW8bit
量化支持,在bitsandbytes量化中主要支持两种量化精度:int4(主要是用来qlora训练)和int8(主要是用来推理)对于两种量化方式代码使用上:
from transformers import BitsAndBytesConfig
# 8 bit 量化
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
# 4 bit 量化
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # 4bit 量化数据类型
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True
)
torchao 量化
上述过程中提到的bitsandbytes量化,在pytorch中支持原生的量化过程tochao(支持llm、扩散模型,并且在使用上区别 bitsandbytes 更加精细)在使用上也比较简单,只需要对上面 Bitsandbytes 量化代码中将 quantization_config 改成torchao所对应的量化即可,比如说:
from transformers import TorchAoConfig
from torchao.quantization import Float8DynamicActivationFloat8WeightConfig, quantize_
quant_type = Float8DynamicActivationFloat8WeightConfig(activation_dtype=torch.float8_e4m3fn,weight_dtype=torch.float8_e4m3fn)
quantization_config = TorchAoConfig(quant_type= quant_type,)
model = AutoModel.from_pretrained(...,quantization_config=quantization_config)
# 除此之外对于自己的模型量化直接使用:
quantize_(model, Float8DynamicActivationFloat8WeightConfig(granularity=PerTensor()))
然后将 from_pretrained 里面的 quantization_config 修改即可,在 torchao 中支持的量化方式有:

而对于 TorchAO 的量化核心基于仿射量化和 分组/通道级粒度(值得是在量化过程中对于 “数据选择”决定“多少个权重/激活值共享同一个缩放因子”的粗细程度 比如说 bitsandbytes 量化过程中直接是选择 block_size 而在 torchao 中支持 block_size/granularity=PerTensor()/granularity=PerRow()),底层依赖自定义内核(CUDA/XPU/CPU)与 inductor 编译器融合。除去上述量化方式 torchao 支持QAT(量化感知训练),根据官方描述:

TorchAO的QAT支持包含两个独立步骤:prepare 和 converted。准备步骤“假”是在训练过程中量化激活和/或权重,这意味着高精度值(例如bf16)会映射到对应的量化值,但实际上不会将其投射到目标的低精度d类型(例如int4)。训练后应用的转换步骤,将模型中的“假”量化操作替换为执行dtype铸造的“真实”量化。比如说下面代码:
from torchao.quantization import quantize_
from torchao.quantization.qat import QATConfig, IntxFakeQuantizeConfig
class SimpleModule(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 128),
nn.Linear(128, output_dim)
)
def forward(self, x):
return self.fc(x)
activation_config = IntxFakeQuantizeConfig(torch.int8, "per_token", is_symmetric=False,)
weight_config = IntxFakeQuantizeConfig(torch.int4, group_size=32, is_symmetric=True,)
qat_config = QATConfig(activation_config=activation_config,weight_config=weight_config,step="prepare",)
quantize_(simple_model, qat_config)
...
base_config = Int4WeightOnlyConfig(group_size=32)
quantize_(compile_simple_model, QATConfig(base_config, step="convert"))
我的模型权重变化过程如下:
# 最开始模型层为
(0): Linear(in_features=32, out_features=1024, bias=True)
# prepare 处理得到模型为
(0): FakeQuantizedLinear(
in_features=32, out_features=1024, bias=True
(activation_fake_quantizer): FakeQuantizer(IntxFakeQuantizeConfig(dtype=torch.int8, granularity=PerToken(), mapping_type=<MappingType.ASYMMETRIC: 3>, scale_precision=torch.float32, zero_point_precision=torch.int32, zero_point_domain=<ZeroPointDomain.INT: 1>, is_dynamic=True, range_learning=False, eps=None))
(weight_fake_quantizer): FakeQuantizer(IntxFakeQuantizeConfig(dtype=torch.int4, granularity=PerGroup(group_size=32), mapping_type=<MappingType.SYMMETRIC: 1>, scale_precision=torch.float32, zero_point_precision=torch.int32, zero_point_domain=<ZeroPointDomain.INT: 1>, is_dynamic=True, range_learning=False, eps=None))
)
# convert 处理得到模型为
(0): Linear(in_features=32, out_features=1024, bias=True, weight=Int4Tensor(shape=torch.Size([1024, 32]), block_size=[1, 32], device=cuda:0, activation_dtype=torch.bfloat16))
从上面模型变化过程可以看到,在 prepare 阶段,会将模型进行fake包裹,而后通过训练得到量化的模型权重,再通过 convert 处理,将模型中的权重和激活值都进行了量化
GGUF
HF文档:https://huggingface.co/docs/hub/en/gguf
https://unsloth.ai/docs/basics/inference-and-deployment/saving-to-gguf
GGUF格式是用于存储大型模型预训练结果的,相较于Hugging Face和torch的bin文件,它采用了紧凑的二进制编码格式、优化的数据结构以及内存映射等技术,提供了更高效的数据存储和访问方式。GGUF 本身支持多种量化级别(Q2_K ~ Q8_0、IQ2 ~ IQ4 等),这些量化方式属于后训练量化(PTQ),和bitsandbytes 4bit 一样,都是在预训练模型上直接执行量化(不需要重新训练)。在GGUF中可以实现量化方式有两类:
| 传统Q系列(按照权重逐层量化) | K-Quant系列(通过 block-wise + scale 优化) |
|---|---|
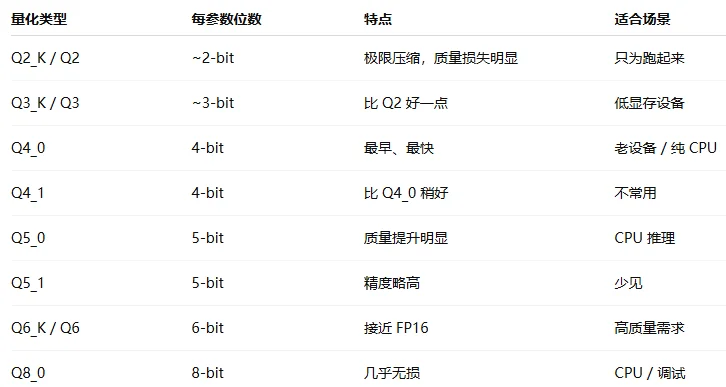 | 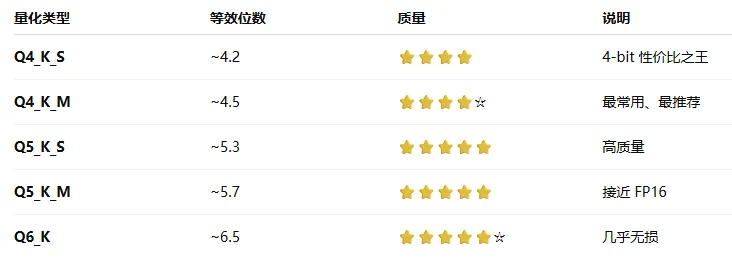 |
其中传统Q系列主要是一整块权重共享一个 scale(缩放因子),每个权重用低 bit 整数表示,容易受到极端值的影响。 K-Quant系列一个 block 内,再分“子块”,每个子块有自己的 scale,其中S代表子块少、scale少;M代表子块多、scale多。
SVDQuant量化
在扩散模型中,权重(Weights)和激活(Activations)往往包含大量异常值(极端大或小的值),这些值在低位量化(如4-bit INT4)时会引起严重误差,导致生成的图像失真或噪声增多。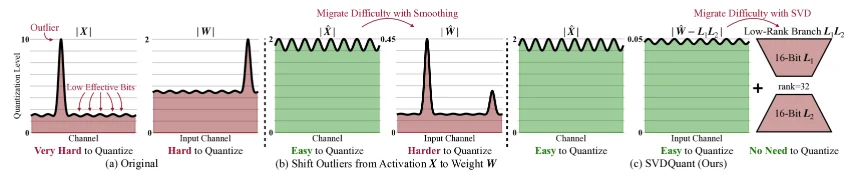
a:权重和激活值中都存在异常值,b:将激活值的异常值移动到权重中,c:将权重进行分解低秩的$L_1L_2$以及残差
其中对于b过程就是常见的SmoothQuant3量化过程
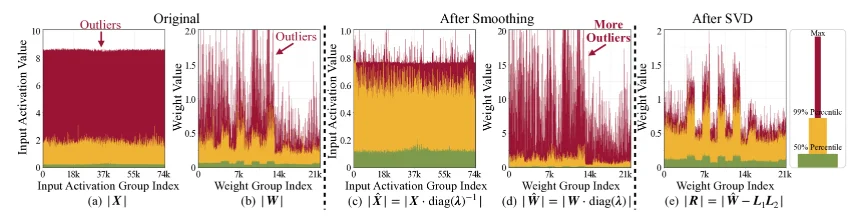
因此对于SVDQuant过程描述如下,对于权重和激活值:$\mathbf{W}$ 以及 $\mathbf{X}$,在最初这两部分值都是存在大量异常值,因此首先通过平滑操作(主要是让减少异常值让量化不会造成太大误差)将激活$\mathbf{X}$中的异常值迁移到权重 $\mathbf{X}$中得到更新后权重 $\hat{\mathbf{W}}$,这部分数据表述为:$\hat{\mathbf{W}}=\mathbf{W}\odot S$其中S是平滑因子,用于转移异常(⊙表示逐元素乘法)。这部分操作主要是因为:将异常值集中到权重侧,因为权重是静态的,更容易后续处理。激活侧的异常值减少后,量化难度降低。
而后,进行SVD分解与低秩吸收,对更新后权重进行奇异值分解:$ \hat{𝑾} = 𝑼 \Sigma 𝑽^T $, 其中𝑼和𝑽是正交矩阵,$\Sigma$是奇异值对角矩阵。保留前k个最大奇异值(低秩r,通常r « min(m,n),其中m,n是权重矩阵维度),形成低秩近似:$ 𝑳_1 𝑳_2 = 𝑼[:,:r] \cdot \Sigma[:r,:r] \cdot 𝑽^T[:r,:] $。然后,计算残差:$ 𝑹 = \hat{𝑾} - 𝑳_1 𝑳_2$,其中只对残差$𝑹$进行量化($Q(𝑹)=\text{round}(\frac{𝑹}{S_𝑹})S_𝑹$,其中$S_𝑹$为缩放因子)处理。低秩分支$ 𝑳_1 𝑳_2 $使用高精度(16-bit float)运行,专门“吸收”异常值和主要信息,而残差𝑹中的异常值和幅度显著减少,只需量化到4-bit。量化误差界限分析(从论文中):量化误差上界可通过F范数和奇异值控制,证明低秩吸收后残差的量化难度降低(误差 ≤ $ \frac{\sqrt{\log(\text{size}(𝑹)\pi)}}{q_{\max}} \mathbb{E}[|𝑹|_F] $,其中q_max是量化最大值),最后的整体近似计算:
\[\hat{\mathbf{X}}\hat{\mathbf{W}}=\hat{\mathbf{X}}(R+L_1L_2)≈\hat{\mathbf{X}}(L_1L_2)+Q(\hat{\mathbf{X}})Q(R)\]对于低秩分支 $L_1 L_2$可以无损的去拼接其它lora,因为输入 $\hat{X}$ 被平滑了因此直接量化误差不大
第一项是16-bit低秩分解,第二项为4-bit残差分支。简而言之上述过程为:首先利用平滑因子 $S$ 将激活值的离群值转移至权重 $\hat{W}$ 中;随后对 $\hat{W}$ 执行奇异值分解(SVD),提取承载异常特征的低秩分支 $L_1 L_2$;最后计算并量化残差矩阵 $R = \hat{W} - L_1 L_2$(因为提取低秩矩阵之后权重就相对平滑,那么对残差量化误差就比较小)其中,残差矩阵为INT4类型,低秩矩阵$L_1 L_2$为FP16。在推理时,权重 $\hat{W}$ 就可以直接变成 $\hat{W} =R+ L_1 L_2$
这里简单介绍一下如何使用SVDQuant量化后模型,一般而言不会去主动通过SVDQuant去量化模型(比如说量化Flux)会直接去加载量化后的模型,可以去huggingface-nunchakus里面找量化后的模型,对于comfyui使用可以直接nunchakus的comfyui去选择自己模型即可,如果纯代码使用可以
import torch
from diffusers import FluxPipeline
from nunchaku import NunchakuFluxTransformer2dModel
from nunchaku.lora.flux.compose import compose_lora
from nunchaku.utils import get_precision
precision = get_precision() # auto-detect your precision is 'int4' or 'fp4' based on your GPU
transformer = NunchakuFluxTransformer2dModel.from_pretrained(
f"nunchaku-tech/nunchaku-flux.1-dev/svdq-{precision}_r32-flux.1-dev.safetensors"
)
pipeline = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev", transformer=transformer, torch_dtype=torch.bfloat16
).to("cuda")
### LoRA Related Code ###
composed_lora = compose_lora(
[
("aleksa-codes/flux-ghibsky-illustration/lora.safetensors", 1),
("alimama-creative/FLUX.1-Turbo-Alpha/diffusion_pytorch_model.safetensors", 1),
]
) # set your lora strengths here when using composed lora
transformer.update_lora_params(composed_lora)
### End of LoRA Related Code ###
image = pipeline(
"GHIBSKY style, cozy mountain cabin covered in snow, with smoke curling from the chimney and a warm, inviting light spilling through the windows", # noqa: E501
num_inference_steps=8,
guidance_scale=3.5,
).images[0]
image.save(f"flux.1-dev-turbo-ghibsky-{precision}.png")
整个过程中还是比较简单的,只不过值得注意的是,假如我的模型是int4量化后的权重,对于量化后的模型权重不能进行lora训练(精度丢失严重)那么直接对fp16的模型进行加载(如果显存不够,from_pretrained过程中可以使用BitsAndBytesConfig进行量化)而后通过Qlora进行微调这样得到的 LoRA 权重是全精度(通常 float16)的,不是量化过的。在comfyui中可以直接加载这个lora权重(将lora放到models/loras/中然后使用Nunchaku Flux LoRA Loader进行加载即可)。但是对于其它权重需要进行量化将其转化为nunchakus可以使用权重:
python -m nunchaku.lora.flux.convert \
--lora-path xx.safetensor \
--base-model xxx.safetensors \
--output-dir ./tmp/ \
--lora-name xx
上面几个参数分别表示lora、模型权重。
对于上述过程简单总结如下:首先在量化过程中激活值以及权重都存在异常值,这个异常值会导致后续量化后模型效果较差,因此首先是将激活值的异常值移动到权重中,而后将得到权重$\hat{W}$进行分解低秩的$L_1L_2$进而可以计算残差$R$,因此对于模型输出过程:$Y=XW=\hat{X}\hat{W}=\hat{X}(L_1L_2+Q(\hat{W}-L_1L_2))$其中$\hat{X}$表示平滑后的激活值,$L_1L_2$表示16-bit的分解矩阵,$Q(\hat{W}-L_1L_2)$表示4-bit低精度值
使用vllm
在对llm进行推理加速过程中比较常见的就是直接使用vllm进行推理加速,简单介绍一下vllm使用方式,分为两种:1、在线推理(而后本地可以直接通过类似Openai调用方式使用);2、离线推理(一般在模型训练比如说GRPOTrainer过程中就会使用去生成)。对于两种方式的使用代码如下:
# 在线推理
"""
启动服务
HF_ENDPOINT=https://hf-mirror.com HF_HUB_CACHE=/root/autodl-tmp/.cache vllm serve Qwen/Qwen3-0.6B --host 0.0.0.0 --port 8001 --gpu-memory-utilization 0.5 --max-model-len 16384 --max-num-seqs 256 --trust-remote-code --served-model-name qwen3-0.6B
1、Qwen/Qwen3-0.6B 可以直接改为自己的模型文件夹
"""
llm = OpenAI(base_url="http://127.0.0.1:8001/v1", api_key="EMPTY")
completion = llm.chat.completions.create(...) # 得到输出
# 离线推理
from vllm import LLM, SamplingParams
llm = LLM(model=model_name_path,...)
sampling_params = SamplingParams(...)
outputs = llm.generate([prompt], sampling_params)
vllm不仅仅对llm可以起作用,在diffuseion model中也可以起作用,可以直接使用 vllm-omni4进行扩散模型加速推理其内部逻辑为:

在对比omni和diffusers在生成图像效果如下,测试代码:
测试参数为(具体设备为
vGPU-32G):Klein4B、超写实亚洲中年男性,年龄约45-55岁。面容坚毅、憔悴,带有生活阅历的痕迹(如眼角的细纹)。他穿着质感柔软的深灰色高领毛衣,外搭一件经典的卡其色风衣,站在寒风中周围是高楼大厦、random_seed=416,直接运行10次测试平均省图时间
| 生成方式 | 正常生图 | 时间 | cache_dit+ compile | 时间 |
|---|---|---|---|---|
diffusers |  | 2.478 | | 2.101 |
vllm-omni |  | 2.368 |  | 2.143 |