本文主要介绍Ai-toolkit框架去对扩散模型进行微调操作
Ai-toolkit
Ai-toolkit安装介绍
环境准备
在autodl上的服务器进行的操作(GPU:VGPU-32G,CUDA Version: 13.0 )
# 首先安装基本环境
source /etc/network_turbo # autodl 上执行该命令进行代理
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
conda create -n ai-toolkit python=3.12
conda activate ai-toolkit
pip3 install --no-cache-dir torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu126
pip3 install -r requirements.txt
# 安装 npm
curl -fsSL https://deb.nodesource.com/setup_lts.x | bash -
apt update
apt install -y nodejs
# 安装完毕之后直接测试,如果显示版本那么表示安装成功
node -v # v24.13.0
npm -v # 11.6.2
npm config set registry https://registry.npmmirror.com # 换npm源
# 由于启动了代理可以先使用下面代码之后再去执行 run 程序
npm config set strict-ssl false
export NODE_TLS_REJECT_UNAUTHORIZED=0
export HF_ENDPOINT=https://hf-mirror.com
# 建议取修改hf模型下载路径
vim ~/.bashrc
export HF_HOME="/path/to/you/dir" # 替换为你想更改的目标路径
source ~/.bashrc
cd ai-toolkit/ui
export HF_ENDPOINT=https://hf-mirror.com
npm run build_and_start
上面运行代码运行之后出现: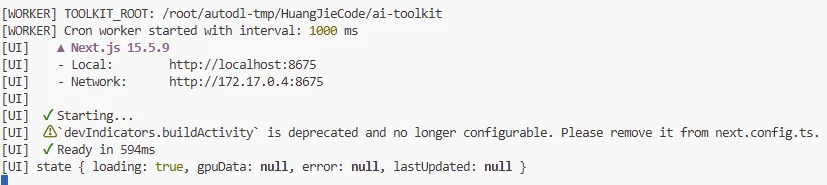
可以直接访问上面地址进入 ai-toolkit
界面简单介绍
首先取配置自己hf token
配置完毕之后可以直接上传数据集/直接在本地数据集,不过数据集需要在路径:xxx/ai-toolkit/datasets(对应上面图像中的路径) 中除此之外还需要注意数据集的格式问题,以文生图任务为例,我的数据集必须满足:1、图像必须是:.jpg, .jpeg, .png;2、文本:txt。除此之外图片文本之间必须匹配:1.png 1.txt…..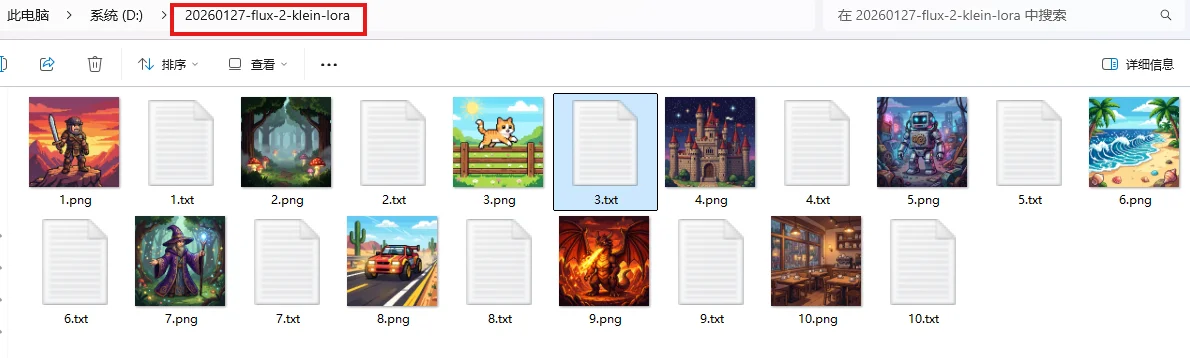
可以直接将上面文件夹上传到xxx/ai-toolkit/datasets中

对于训练界面参数介绍: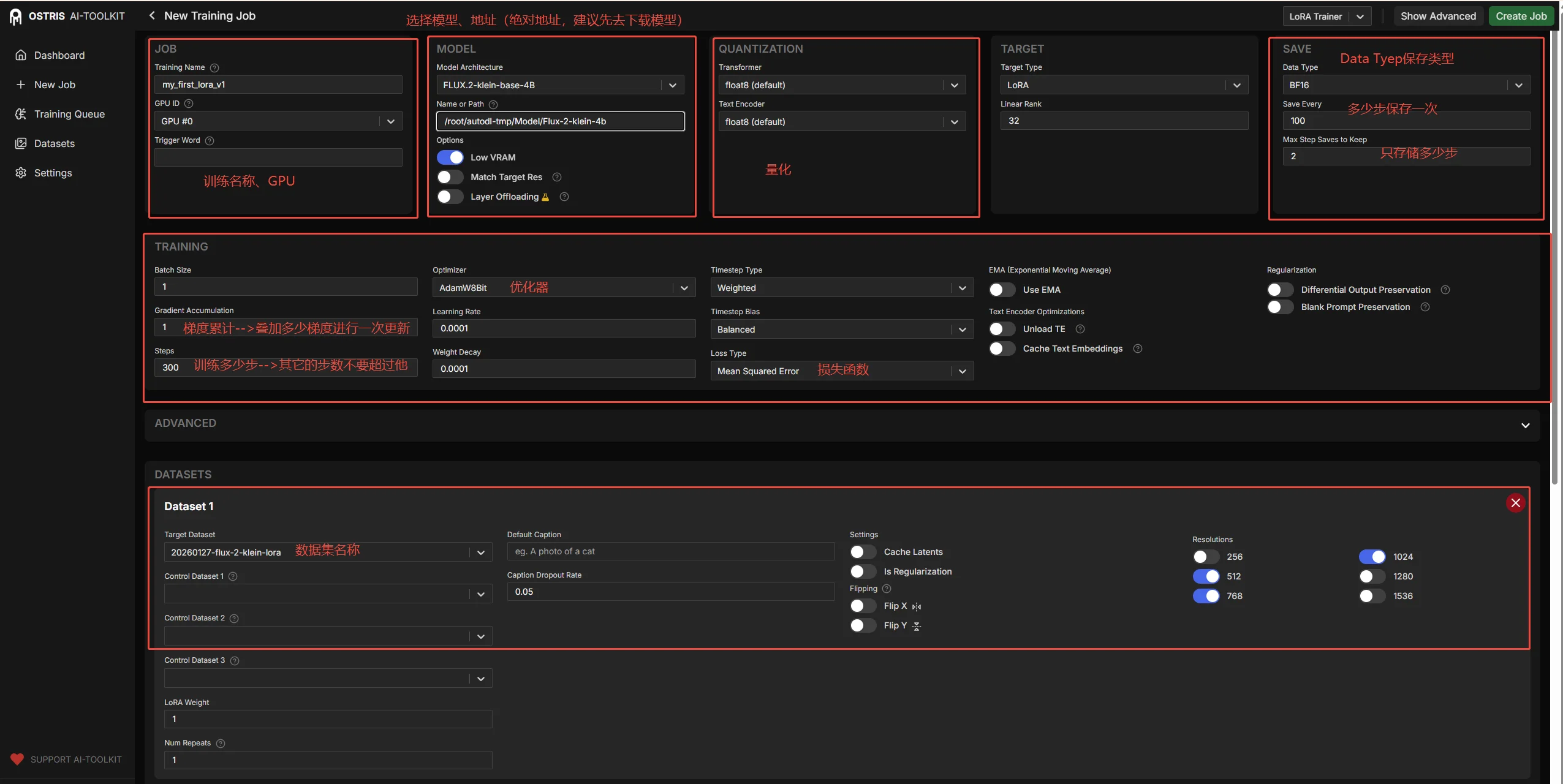
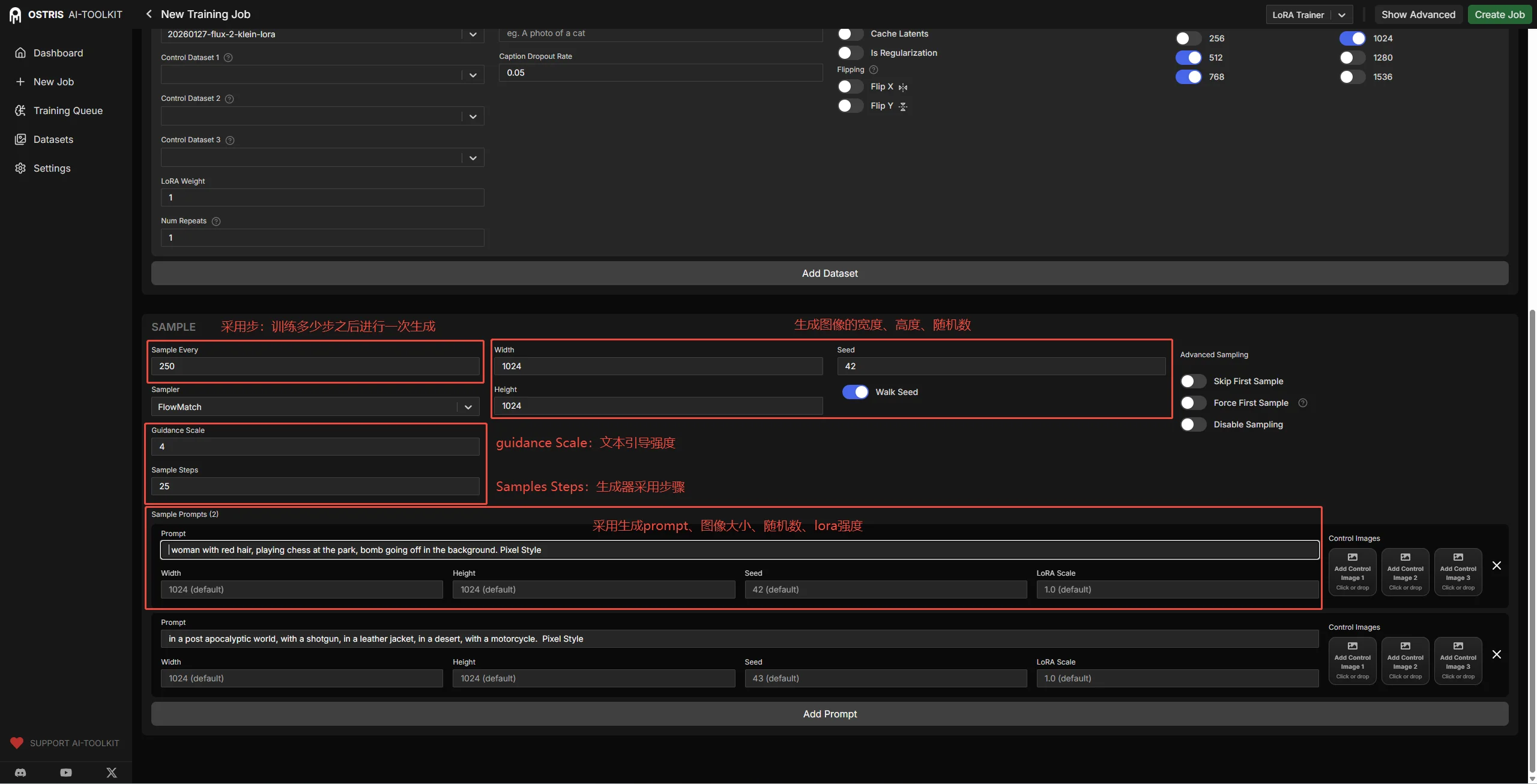
1、模型路径尽量不要去修改就用默认的,如果要去修改可以参考:reddit上的方法
2、如果报错是和模型下载相关(如CAS报错、hf_transfer报错),可以直接重启任务就行(去Training Quene找到任务然后重新启动即可)
模型训练处理
Ai-toolkit模型微调
对于文生图/图生图微调训练很简单只需要将上面的数据进行修改即可,而后点击开始训练即可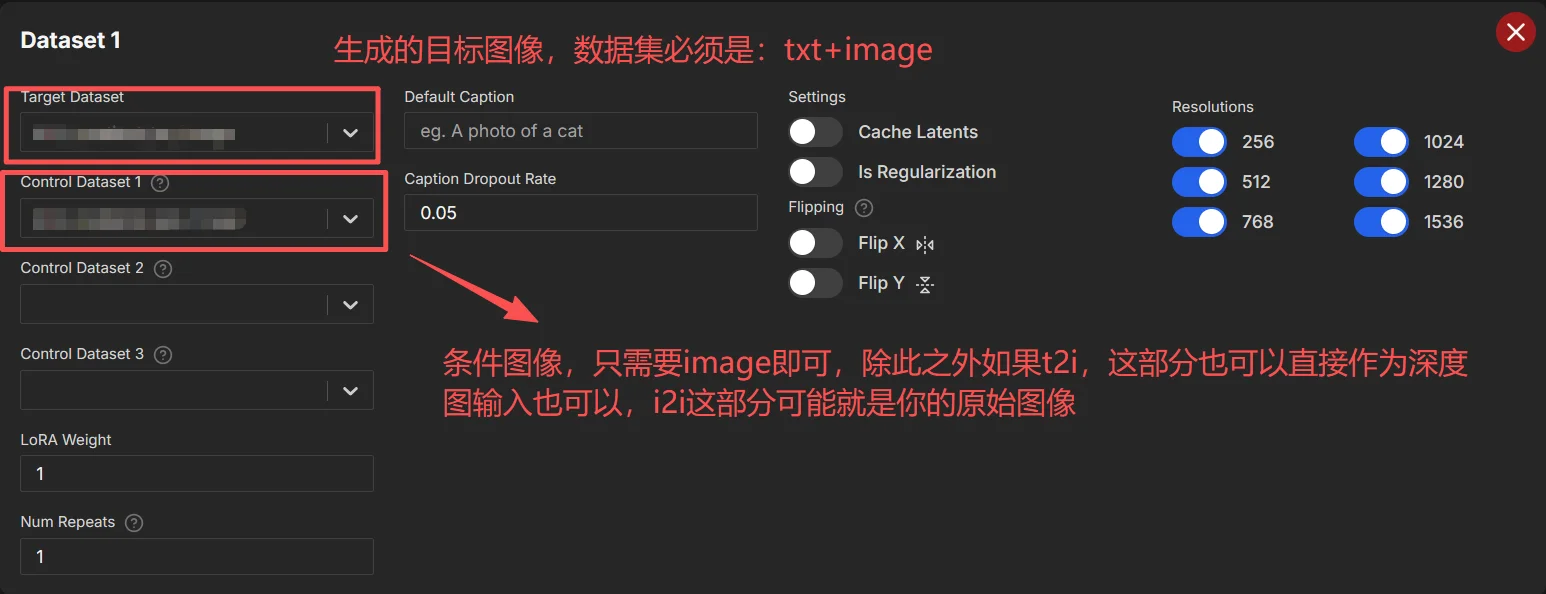
值得注意的是,如果模型还需要去继续训练,比如说我在第一批数据得到一个lora但是又有另外一批数据需要继续去训练,在前端是不支持的,需要重新去建立一个训练任务(可以直接复制第一批数据的yaml文件)而后将其中的数据以及命名都改掉,修改yaml中的name: Flux-Klein-AID-Inpatient-2000-9B,而后将上一批数据中训练得到的最好的lora复制到新的文件夹中,而后启动训练即可(python run.py output/tmp/config.yaml)这个过程会在终端出现
#### IMPORTANT RESUMING FROM /root/autodl-tmp/xxx/ai-toolkit/output/xxx/xxx.safetensors ####
Loading from /root/autodl-tmp/xxx/ai-toolkit/output/xxx/xxx.safetensors
说明模型重新去加载了lora,具体代码在jobs/process/BaseSDTrainProcess.py中的函数get_latest_save_path就是去加载最新得到权重进行继续训练。
if latest_save_path is not None:
print_acc(f"#### IMPORTANT RESUMING FROM {latest_save_path} ####")
model_config_to_load.name_or_path = latest_save_path
self.load_training_state_from_metadata(latest_save_path)
Ai-toolkit代码分析
在Ai-toolkit中模型微调整个流程如下:Googledrive-Drawio。对于上述流程图中只介绍了对于模型、数据都是如何处理的,对于具体如何处理没有介绍,这里简单做一些介绍数据以及模型处理过程进行初步介绍,对于数据处理过程:
对于dataset构建过程:
class AiToolkitDataset(LatentCachingMixin, ControlCachingMixin, CLIPCachingMixin, TextEmbeddingCachingMixin, BucketsMixin, CaptionMixin, Dataset):
def __init__(self, ...):
...
self.file_list: List['FileItemDTO'] = []
# 其中 self.dataset_path 对应我的 yaml 文件中的 folder_path
if os.path.isdir(self.dataset_path):
extensions = image_extensions
if self.is_video:
extensions = video_extensions
file_list = [os.path.join(root, file) for root, _, files in os.walk(self.dataset_path) for file in files if file.lower().endswith(tuple(extensions))]
else:
with open(self.dataset_path, 'r') as f:
self.caption_dict = json.load(f)
# keys are file paths
file_list = list(self.caption_dict.keys())
# 而后去对数据进行重复采样
...
for file in tqdm(file_list):
try:
file_item = FileItemDTO(
sd=self.sd,
path=file,
dataset_config=dataset_config,
dataloader_transforms=self.transform,
size_database=self.size_database,
dataset_root=dataset_folder,
encode_control_in_text_embeddings=self.sd.encode_control_in_text_embeddings if self.sd else False,
text_embedding_space_version=self.sd.model_config.arch if self.sd else "sd1",
te_padding_side=self.sd.te_padding_side if self.sd else "right",
latent_space_version=latent_space_version,
)
self.file_list.append(file_item)
def __len__(self):
if self.dataset_config.buckets:
return len(self.batch_indices)
return len(self.file_list)
def __getitem__(self, item):
if self.dataset_config.buckets:
if len(self.batch_indices) - 1 < item:
idx_list = self.batch_indices[item]
return [self._get_single_item(idx) for idx in idx_list]
else:
return self._get_single_item(item)
对于上面的FileItemDTO其实就是对于上面流程图中比如说LatentCachingFileItemDTOMixin这些父类都是定义了一些基础数据处理,比如说prompt、图像进行tensor转换等。对于loader过程,在ai-toolkit中会将数据都封装为:DataLoaderBatchDTO(toolkit/data_transfer_object/data_loader.py)对于里面定义了很多属性值需要关注的就是如下几个(batch = next(iter(data_loader))):1、batch.tensor:对于目标图的tensor尺寸大小;2、batch.control_tensor:对应条件图的tensor尺寸大小;3、batch.get_caption_list():获取整个batch中所有的提示词。在得到完整的laoder数据集之后就是直接进行模型训练。对于训练过程整体代码如下:
class BaseSDTrainProcess(BaseTrainProcess):
...
# 预先定义好整个训练过程就和hf中trainer中一样
class SDTrainer(BaseSDTrainProcess):
# 具体训练过程就和DPOTrainer一样都是继承一个小的trainer
...
def __init__(...):
...
def hook_train_loop(self, batch: Union[DataLoaderBatchDTO, List[DataLoaderBatchDTO]]):
# 模型计算loss/梯度更新
for batch in batch_list:
...
loss = self.train_single_accumulation(batch) # 去vae等编码而后计算loss
...
if total_loss is None:
total_loss = loss
else:
total_loss += loss
...
if not self.is_grad_accumulation_step:
# 梯度累计
...
self.accelerator.clip_grad_norm_(...)
...
with self.timer('optimizer_step'):
self.optimizer.step()
self.optimizer.zero_grad(set_to_none=True)
...
with self.timer('scheduler_step'):
self.lr_scheduler.step()
loss_dict = OrderedDict({'loss': (total_loss / len(batch_list)).item()})
self.end_of_training_loop()
return loss_dict
对于训练过程中,主要是self.train_single_accumulation(batch)在这个函数中对于输入的batch会进行vae、text_encoder等进行编码然后计算loss整个过程如下:
def train_single_accumulation(self, batch: DataLoaderBatchDTO):
with torch.no_grad():
....
noisy_latents, noise, timesteps, conditioned_prompts, imgs = self.process_general_training_batch(batch)
if self.train_config.do_cfg or self.train_config.do_random_cfg:
# 如果要做文本的 cfg,如果有negative那么就使用否则直接用 '' 空字符串代替
....
if self.adapter and isinstance(self.adapter, CustomAdapter):
# 如果有 adapter 那么就用adapter去处理 conditioned_prompts
conditioned_prompts = self.adapter.condition_prompt(conditioned_prompts)
...
if self.train_config.short_and_long_captions_encoder_split and self.sd.is_xl:
# 如果是 sdxl 模型会对prompt进行切断然后长/短分别交给不同编码器
...
if self.train_config.single_item_batching:
# 单样本逐个批处理模式,主要是为了处理显存不够情况,那么将数据进行按 bs进行chunk到list中
batch_size = noisy_latents.shape[0]
noisy_latents_list = torch.chunk(noisy_latents, batch_size, dim=0)
...
else:
noisy_latents_list = [noisy_latents]
...
# 一次读取数据开始训练
for noisy_latents, noise,... in zip(noisy_latents_list, noise_list, ...):
with (network):
# 专门处理“图像适配器”(adapter)的条件嵌入编码和注入,让模型在当前 batch 的去噪预测中能利用额外的图像条件(如 IP-Adapter 风格的 CLIP Vision 图像提示,或自定义的图像参考)。
# TODO: 详细去了解一下如何使用 adapter 在ai-toolkit中
with self.timer('encode_prompt'):
prompt_kwargs = {}
if self.sd.encode_control_in_text_embeddings and batch.control_tensor is not None:
prompt_kwargs['control_images'] = batch.control_tensor.to(...)
if self.train_config.unload_text_encoder or self.is_caching_text_embeddings:
# 这部分参数在前端中就有选择
# 如果卸载text_encoder 以及缓存text_embedding的时候需要处理
...
elif grad_on_text_encoder:
# 训练 text_encoder
...
# TODO: 详细去了解一下如何使用 adapter 在ai-toolkit中
if self.train_config.timestep_type == 'next_sample':
# 获取 预测的noise
...
if batch.unconditional_latents is not None or self.do_guided_loss:
# 用差分引导损失(让 LoRA 专注“变化部分”,防过拟合/出血)
...
elif self.train_config.loss_type == 'mean_flow':
# 用 flow-matching 专属的平均流损失
...
...
self.accelerator.backward(loss)
return loss.detach()
数据后处理过程:对于process_general_training_batch过程需要去看BaseSDTrainProcess(jobs/process/BaseSDTrainProcess.py)代码对于这个过程简单总结如下:
1、prepare_prompt:对 prompts 进行系统性扩展和条件化处理,确保模型在不同配置(短/长 caption、refiner、embedding、trigger、prompt saturation)下,得到正确且一致的输入文本
2、prepare_latents:直接获取batch.tensor进行vae编码
3、prepare_scheduler:直接处理好调度器,比如说调度此要采样多少步,默认是num_train_timesteps=1000
4、prepare_timesteps_indices:选择时间步,比如说参数next_sample以及one_steps前面代表去随机选择(0,num_train_timesteps-2)或者直接就是一步(类似flow-matching)以及content_or_style参数主要是3个值:content:选择靠前的时间步(学习图像结构特征)、style:选择靠后的时间步(学习图像纹理)、balanced(默认):选择中段时间步,之所以这样是因为df解噪声过程直接从1-1000越往后模型越体现的是细节内容
5、convert_timestep_indices_to_timesteps:将时间步添加到调度器中,self.sd.noise_scheduler.timesteps[timestep_indices.long()]
6、prepare_noise: 生成噪声
7、make_noisy_latents:将得到的noise添加到latents中。
通过上面过程最后返回:noisy_latents, noise, timesteps, conditioned_prompts, imgs,这样一来标准的输入数据格式就准备好了。
ai-toolkit 训练参数
值得注意的是除去ai-toolkit中前端默认参数还可以直接自定义参数(较多参数都在ai-toolkit/toolkit/config_modules.py文件中给了默认参数):
model模块参数(直接去BaseSDTrainProcess.py看参数)
assistant_lora_path:str: lora模型路径(建议直接使用 hf地址)
train模块参数(直接去BaseSDTrainProcess.py看参数)
| 参数名称 | 参数描述 | 注意事项 |
|---|---|---|
xformers:bool | 是否启动xformer,直接去vae以及unet中启动xformer加速计算 | 注意模型是不是支持xformer,代码位置 |
attention_backendattention_backend:str | 后端attention计算方式,也是对vae/unet进行,比如说flash等 | |
decorator_config | 这部分参数配置和 train 中配置参数写的方式是一样的 |
decorator模块参数(暂时只支持 flux 模型)(默认没有,参数方法和 train 中使用方法相同)
num_tokens:int 文本嵌入修饰器/适配器,专门用于在扩散模型的文本条件输入上额外拼接几个可学习的 token
adaptert2i模块参数(默认没有,参数方法和 train 中使用方法相同)
对于这个模块参数可以参考配置。主要作用是实现图像到图像(image-to-image)条件适配器,主要功能是,让模型“看见”参考图像,然后根据文本提示 + 参考图像 来生成变体(variation)、风格迁移、细节保持等。
adapter:
train: false # adapter是否参与训练
type: "ip_adapter" # 支持:"t2i", "control_net", "clip", "ip" 也支持直接自定义
name_or_path: "h94/IP-Adapter" # 上面4种参数直接会从 hf 上进行加载,对于自定义的值就回去加载custom
weight_name: "ip-adapter_sd15.safetensors"
scale: 0.8 # 强度缩放(可选,默认 1.0)
test_img_path:
- "path/to/your/image.png"
- "path/to/your/image2.png"
排错处理
- 1、加载数据过程中出现数据形状不匹配问题

对于上面截图报错在测试Klein9B模型过程中出现,主要是在测试batch_size>1就容易发生,可以直接将所有的数据都固定到相同形状可以解决
- 2、进程一直被
killed
在运行代码(直接使用python run.py ...)有些适合就会在终端直接被killed(ai-toolkit默认的 torch=2.7可能版本不太合适)切换为 torch=2.10的版本 pip3 install --no-cache-dir torch==2.10.0 torchvision==0.25.0 torchaudio==2.10.0 --index-url https://download.pytorch.org/whl/cu126
- 3、hf_transfer/CAS 错误
An error occurred while downloading using
hf_transfer. Consider disabling HF_HUB_ENABLE_HF_TRANSFER for better error handling.
启动命令前使用
export HF_HUB_ENABLE_HF_TRANSFER=0 # 处理hf_transfer报错
export HF_HUB_DISABLE_XET=1 # 处理CAS报错
- 4、端口占用错误
[UI] next start --port 8675 restarted
[UI] ⨯ Failed to start server
[UI] Error: listen EADDRINUSE: address already in use :::8675
[UI] at <unknown> (Error: listen EADDRINUSE: address already in use :::8675)
[UI] at new Promise (<anonymous>) {
[UI] code: 'EADDRINUSE',
[UI] errno: -98,
[UI] syscall: 'listen',
[UI] address: '::',
[UI] port: 8675
[UI] }
[UI] next start --port 8675 exited with code 1
保持npm运行另起终端
sudo apt install net-tools
sudo netstat -tunlp | grep ':8675'
kill -9 470457