Qwen多模态系列模型
QwenVL
在QwenVL1中在论文里面作者提到的其模型的整个训练过程如下: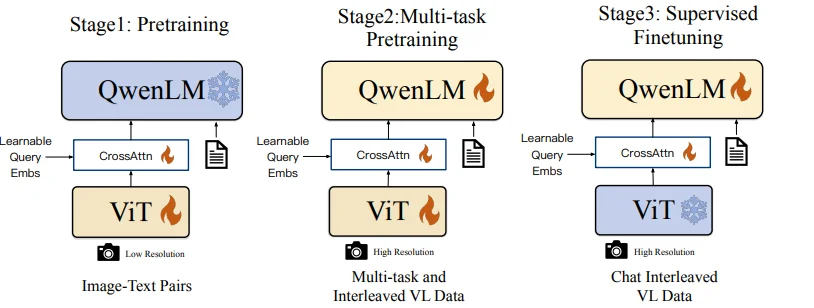
仅从提供的不同阶段还是很容易发现QwenVL还是是采用和BLIP相似的使用 learned-query来对齐模态信息
语言模型使用(7.7B):Qwen-7B
视觉编码器(1.9B):Vit-bigG
融合器(0.08B):Learnable Query
不过论文里面对于模型细节介绍不是很多,从代码角度出发窥其模型结构:
模型视觉编码器:视觉编码器使用的是ViT架构(Vision Transformer),ViT的网络设置和初始化参数使用了OpenCLIP预训练好的ViT-bigG模型。具体的代码处理过程(代码),其中模型输出维度变化过程:1x3x448x448–>1x1664x32x32(首先卷积处理)–>1x1024x1664(拉平交换维度)
特征融合器:上述ViT处理后,对于$448\times 448$分辨率的图像,生成一个 [1024, 1664]的序列,也就是向量维度为1664的长度为1024的序列。为了压缩视觉token的输入长度,Qwen-VL引入了一个Adapter来压缩图像特征。这个Adaper就是一个随机初始化的单层Cross-Attention模块。该模块使用一组可学习的query向量,将来自ViT的图像特征作为Key向量。通过Cross-Attention操作后将视觉特征序列压缩到固定的256长度(也就是将视觉特征压缩到 256 1644)
此外,考虑到位置信息对于精细图像理解的重要性,Qwen-VL将二维绝对位置编码(三角位置编码)整合到Cross-Attention的 $q,k$中,以减少压缩过程中可能丢失的位置细节。随后将长度为256的压缩图像特征序列输入到大型语言模型中。
QwenVL-2
对于QwenVL-22其模型的基本结构如下: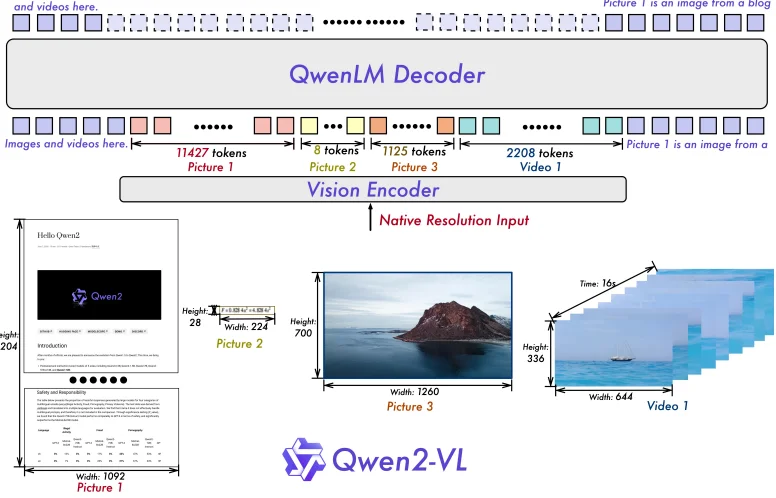
1、使用动态分辨率(也就是说输入图像不需要再去改变图像尺寸到一个固定值),于此同时为了减少 visual-token数量,将2x2的的相邻的token进行拼接到一个token而后通过MLP层进行处理。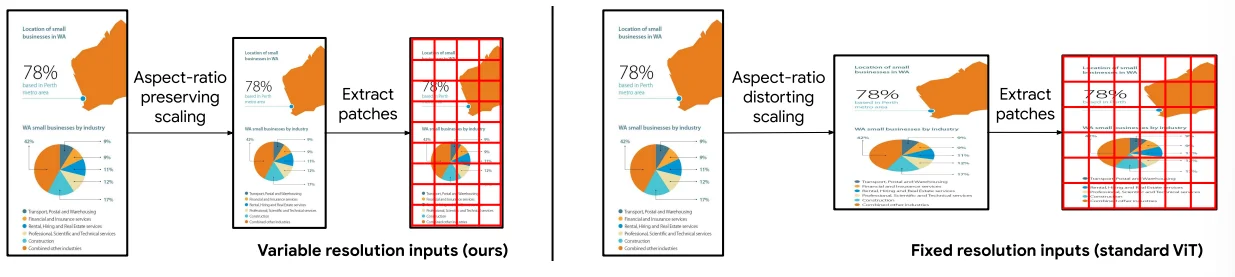
动态分辨率处理如上,通过指定[mix_pixels, max_pixels]范围然后将图像保持原始的纵横比去缩减图像到上面的范围中(处理过程,首先计算原始图像的像素数量,而后判断和上面指标的范围,如果超出范围就去计算需要修改的比例,在将整个比例去处理到分辨率上)
在通过使用动态分辨率处理图像之后会在单一图片增加时间维度也就是将:CHW–>TCHW(这点是为了和视频处理过程进行对齐),在源码中T选择数值为2也就是将图片“复制一次”,而后对帧序列进行Patchification操作
def _preprocess():
......
channel = patches.shape[1]
grid_t = patches.shape[0] // self.temporal_patch_size
grid_h, grid_w = resized_height // self.patch_size, resized_width // self.patch_size
patches = patches.reshape(
grid_t, # 0
self.temporal_patch_size, channel, # 1 2
grid_h // self.merge_size, # 3
self.merge_size, self.patch_size, # 4 5
grid_w // self.merge_size, # 6
self.merge_size, self.patch_size, # 7 8
) # self.merge_size=2 self.patch_size=14 self.temporal_patch_size=2
### 将2x2的邻域Patch放到一起,方便后续做领域的Patch过Projector层做聚合压缩
patches = patches.transpose(0, 3, 6, 4, 7, 2, 1, 5, 8)
### Patch序列化,并保留Patch位置信息(时间,高,宽)
flatten_patches = patches.reshape(
grid_t * grid_h * grid_w, channel * self.temporal_patch_size * self.patch_size * self.patch_size
)
上面过程也就是进行所谓的“2x2的相邻token拼接”,最后得到[grid_t * grid_h * grid_w, channel * temporal_patch_size(2) * patch_size(14) * patch_size(14)](其中grid_h=resized_height // self.patch_size(14))
2、多模态的旋转位置编码(M-RoPE),也就是将原来位置编码所携带的信息处理为:时序(temporal)、高度(height)、宽度(width)。比如下图中对于文本处理直接初始化为:$(i,i,i)$。但是对于图片而言就是:$(i,x,y)$ 其中 $i$ 是恒定的,而对于视频就会将 $i$ 换成视频中图像的顺序
总结处理过程:动态分辨率处理–>复制时间维度–>将序列切割为patch。这样一来就会直接将图像处理为:[grid_t * grid_h * grid_w, channel * temporal_patch_size(2) * patch_size(14) * patch_size(14)](其中grid_h=resized_height // self.patch_size(14))除此之外而后去计算 3d-RoPE最后通过一层线性层处理就得到最后的视觉token。
QwenVL-2.5
在QwenVL2.5中3模型具体的代码处理过程参考Blog4具体模型结构: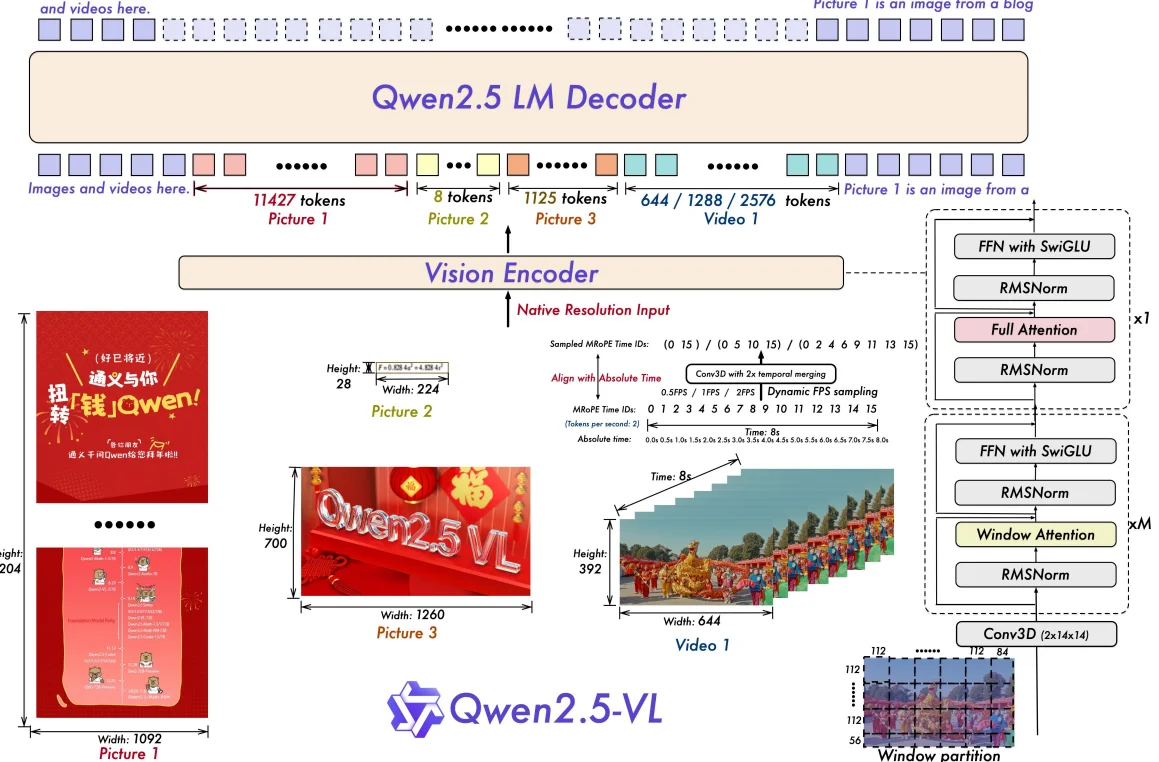
在图像处理过程上和QwenVL2差异不大都是直接:动态分辨率处理–>复制时间维度–>将序列切割为patch,对比两个模型差异: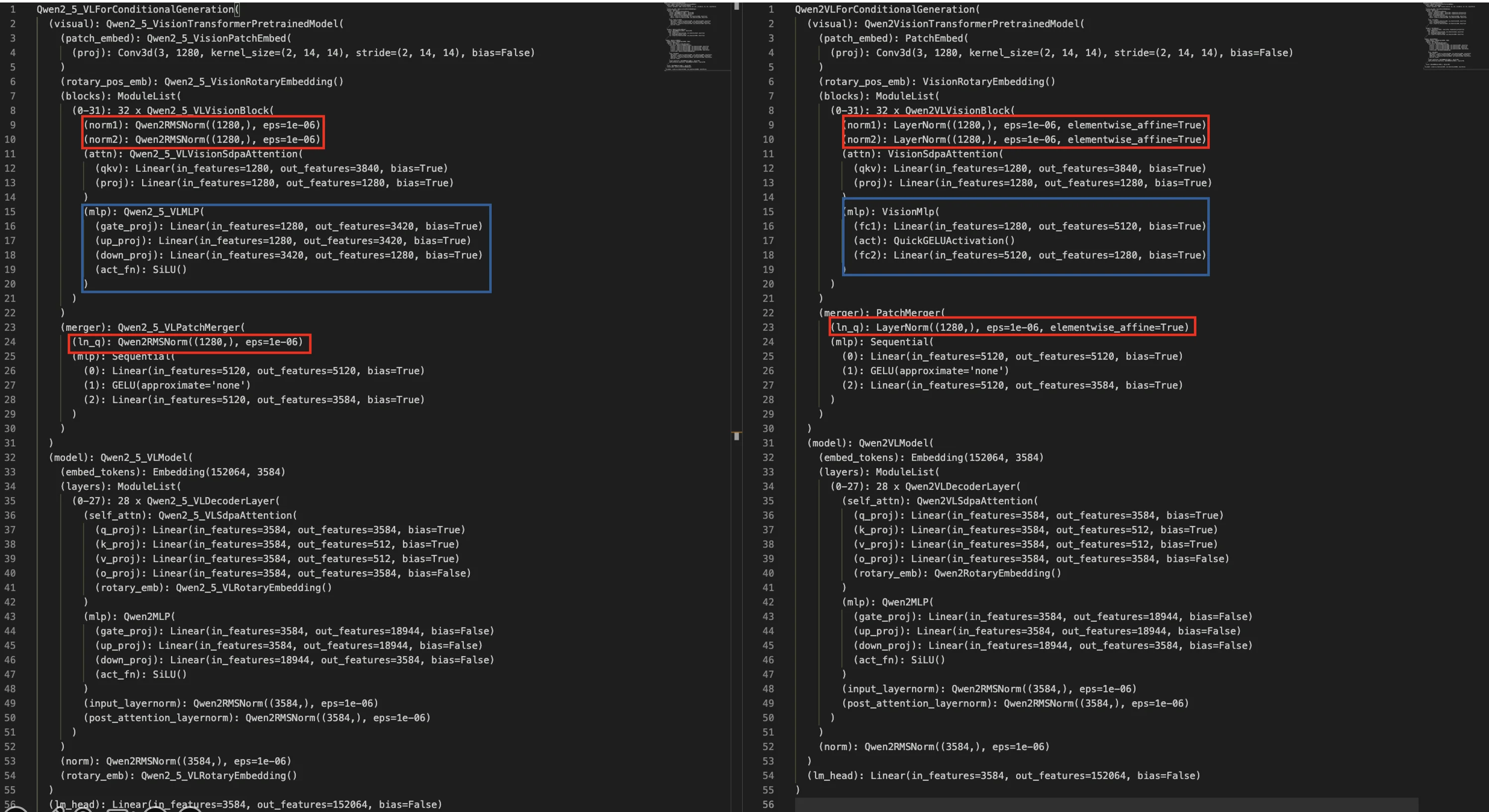
1、采用 RMSNorm 替换了所有 LayerNorm;2、ViT中每一个VisionBlock中的MLP换成了SwiGLU 结构。只从模型结构上差异不到,在QwenVL2.5中主要进行改动:1、在视觉编码过程中使用window-attention(对应上述结构中的Qwen2_5_VLVisionAttention)对于具体的划分window方法(代码):根据输入的图像大小 (gird_t, grid_h, grid_w)去得到窗口索引 (window_index) 和 累积序列长度 (cu_window_seqlens)。具体例子如下:
# 数据数据特征
[ [ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35] ]
# 保证可以被window_size划分需要进行填充
[ [ 0, 1, 2, 3, 4, 5, X, X],
[ 6, 7, 8, 9, 10, 11, X, X],
[12, 13, 14, 15, 16, 17, X, X],
[18, 19, 20, 21, 22, 23, X, X],
[24, 25, 26, 27, 28, 29, X, X],
[30, 31, 32, 33, 34, 35, X, X],
[ X, X, X, X, X, X, X, X],
[ X, X, X, X, X, X, X, X] ]
# 而后直接更具window大小得到每个需要计算注意力的window
# window-0
[ 0, 1, 2, 3]
[ 6, 7, 8, 9]
[12, 13, 14, 15]
[18, 19, 20, 21]
# 展平重新排列得到:
# window-0
[0, 1, 2, 3, 6, 7, 8, 9, 12, 13, 14, 15, 18, 19, 20, 21]
# window-1
[4, 5, 10, 11, 16, 17, 22, 23]
# 计算累计长度
seqlens = (index_padded != -100).sum([2, 3]) # 计算有效长度:window-0:16 window-1:8.....
cu_seqlens_tmp = seqlens.cumsum(0) * 4 + cu_window_seqlens[-1]
cu_window_seqlens.extend(cu_seqlens_tmp.tolist())
# [0, 64, 96, 128, 144]
# 得到最后返回结果window_index, cu_window_seqlens
在得到window_index和cu_window_seqlens之后就是计算注意力过程
for i in range(1, len(cu_seqlens)):
attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = 0
q = q.transpose(0, 1)
k = k.transpose(0, 1)
v = v.transpose(0, 1)
attn_weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.head_dim)
attn_weights = attn_weights + attention_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
QwenVL-3
在官方Blog5的介绍中
对于模型架构的更新简单总结为:1、MRoPE-Interleave: 改进位置编码,采用时间(t)、高度(h)、宽度(w)交错分布形式,提升对长视频的理解能力。2、DeepStack 技术: 融合 ViT 多层次特征,将视觉特征注入 LLM 的多层中,实现更精细化的视觉理解和图文对齐精度。3、文本时间戳对齐机制 (T-RoPE 升级): 采用“时间戳-视频帧”交错输入形式,实现帧级别时间信息与视觉内容的细粒度对齐,提升视频事件定位精度。整体模型结构在区别上一代QwenVL-2.5改进点在于:patch_embed的patch_size变大了(14->16),embed使用的三维卷积里加了bias,ViT的隐层维度hiddeen_dim从1280->1152,而后使用DeepStack、MRoPE-Interleave。
- DeepStack 技术原理
从最上面的模型结构图中可以发现DeepStack就是将视觉视觉编码器特征融入到LLM Block的每一层中,参考论文中的结构图6:
之所以要使用该技术是为了解决:计算与内存开销过高:传统LMMs将所有视觉visual tokens拼接成一维序列输入到语言模型的第一层,导致需要处理的输入序列长度显著增加,尤其在处理高分辨率图像或多帧视频时,计算和内存成本急剧上升。细粒度视觉信息丢失:现有方法通过压缩视觉Token(如空间池化、感知器重采样等)来平衡计算开销与信息保留,但会牺牲高分辨率图像中的细节信息。视觉与语言交互效率不足:现有方法仅通过第一层Transformer处理所有视觉Token,未能充分利用语言模型深层结构的层次化特征提取能力。
源码结构
值得注意的是在输入数据预处理阶段QwenVL-3和2.5的处理是相同的通过smart_resize去修改分辨率
class Qwen3VLModel(Qwen3VLPreTrainedModel):
...
def __iniit__(...):
super().__init__(config)
self.visual = Qwen3VLVisionModel._from_config(config.vision_config)
self.language_model = Qwen3VLTextModel._from_config(config.text_config)
self.rope_deltas = None # cache rope_deltas here
self.post_init()
def forward(...):
...
# 图像处理过程
if pixel_values is not None:
image_embeds, deepstack_image_embeds = self.get_image_features(pixel_values, image_grid_thw)
image_embeds = torch.cat(image_embeds, dim=0).to(inputs_embeds.device, inputs_embeds.dtype)
image_mask, _ = self.get_placeholder_mask(
input_ids, inputs_embeds=inputs_embeds, image_features=image_embeds
)
inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)
...
outputs = self.language_model(...,inputs_embeds=inputs_embeds,...)
get_image_features处理过程:通过Qwen视觉编码其处理并且获取特定层视觉编码特征
通过视觉编码处理得到image_embeds和 deepstack_image_embeds而后再去对 image_embeds进行裁剪,裁剪的逻辑为:split_sizes = (image_grid_thw.prod(-1) // self.visual.spatial_merge_size**2).tolist();image_embeds = torch.split(image_embeds, split_sizes) 回到self.visual中模型具体处理过程如下(代码):
# https://github.com/huggingface/transformers/blob/0419ff881d7bb503f4fc0f0a7a5aac3d012c9b91/src/transformers/models/qwen3_vl/modeling_qwen3_vl.py#L701
class Qwen3VLVisionModel(Qwen3VLPreTrainedModel):
def __init__(...):
...
self.blocks = nn.ModuleList([Qwen3VLVisionBlock(config) for _ in range(config.depth)])
self.merger = Qwen3VLVisionPatchMerger(...)
self.deepstack_visual_indexes = config.deepstack_visual_indexes
self.deepstack_merger_list = nn.ModuleList(
[
Qwen3VLVisionPatchMerger(
config=config,
use_postshuffle_norm=True,
)
for _ in range(len(config.deepstack_visual_indexes))
]
)
def forward(self, hidden_states: torch.Tensor, grid_thw: torch.Tensor, **kwargs):
... # 对图像数据通过 patch_embed 进行处理而后补充位置编码
# Vit处理
deepstack_feature_lists = []
for layer_num, blk in enumerate(self.blocks):
hidden_states = blk(...)
if layer_num in self.deepstack_visual_indexes:
deepstack_feature = self.deepstack_merger_list[self.deepstack_visual_indexes.index(layer_num)](hidden_states)
deepstack_feature_lists.append(deepstack_feature)
hidden_states = self.merger(hidden_states) # 直接通过两层fc进行处理
return hidden_states, deepstack_feature_lists
patch_embed就是直接使用3维卷积(bias为True):Conv3d(3, 1152, kernel_size=(2, 16, 16), stride=(2, 16, 16))(维度上对应:(grid_t*grid_h*grid_w, hiddend_size)),对于上述DStack过程中也比较好理解直接从需要处理的每层(通过Qwen3VLVisionBlock总共由27层叠加)中挑选出对应的处理后的特征,直接挑选[8, 16, 24]层处理后的特征。
在 ViT 模型的预训练阶段,通常使用固定的输入分辨率(例如 224×224),并将其划分为固定数量的 patch(例如 14×14,共 196 个 patch)。这意味着模型内部的 pos_embed 是一个固定长度的可学习参数矩阵,模型在训练过程中已经隐式地学习到了这些位置编码之间的空间关系。当推理阶段输入的分辨率发生变化时,如果直接重新计算或生成新的位置编码,就会破坏模型在预训练阶段学到的空间语义信息,从而导致性能下降。因此,QwenVL-3 等模型的做法是:固定一套在预训练阶段学习到的位置编码,在输入新的分辨率时,不重新生成编码,而是通过 双线性插值 将原始位置编码映射到新的空间尺度上,从而在保持预训练空间结构的前提下,适配不同输入尺寸。换句话说,新的 patch 位置不再重新计算 embedding,而是通过插值在原有位置编码上“找到”其对应的空间位置。
- llm处理过程:直接将视觉token位置上补充我的DeepStack特征
# https://github.com/huggingface/transformers/blob/0419ff881d7bb503f4fc0f0a7a5aac3d012c9b91/src/transformers/models/qwen3_vl/modeling_qwen3_vl.py#L760
class Qwen3VLTextModel(Qwen3VLPreTrainedModel):
def __init__(self, config: Qwen3VLTextConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[Qwen3VLTextDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = Qwen3VLTextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.rotary_emb = Qwen3VLTextRotaryEmbedding(config=config)
self.gradient_checkpointing = False
def forward(...,input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,...
visual_pos_masks: Optional[torch.Tensor] = None,
deepstack_visual_embeds: Optional[list[torch.Tensor]] = None,
):
...
for layer_idx, decoder_layer in enumerate(self.layers):
layer_outputs = decoder_layer(...) # 模型解码输出
hidden_states = layer_outputs
if deepstack_visual_embeds is not None and layer_idx in range(len(deepstack_visual_embeds)):
hidden_states = self._deepstack_process(
hidden_states,
visual_pos_masks,
deepstack_visual_embeds[layer_idx],
)
hidden_states = self.norm(hidden_states)
...
def _deepstack_process(
self, hidden_states: torch.Tensor, visual_pos_masks: torch.Tensor, visual_embeds: torch.Tensor
):
visual_pos_masks = visual_pos_masks.to(hidden_states.device) # 形状 batch_size, seqlen
visual_embeds = visual_embeds.to(hidden_states.device, hidden_states.dtype)
local_this = hidden_states[visual_pos_masks, :].clone() + visual_embeds
hidden_states[visual_pos_masks, :] = local_this
return hidden_states
其实从上面代码中很容易发现在DeepStack中QwenVL-3处理方式很简单直接选出所有视觉token位置而后将视觉特征进行补充,其中visual_pos_masks的形状是batch_size, seqlen
Qwen-3.5
简单总结模型主要亮点在于:1、使用linear-attention+full+attention的混合,其中整体的混合比例3:1(3层linear attention后叠加1层full attention)比如说
2、除此之外引入门控注意力计算(Gate-Attention7)主要过程式在计算QKV三部分的注意力之后引入Gate机制。在代码中的具体实现过程为代码为(图片来源知乎):
对于上述过程中的QKV和常规的Attention中计算没差异,关键在于其引入了z、b、a这三组变量,其中b、a主要是用在Gate计算中而z则是在最后计算完attention之后再去self.norm(core_attn_out, z),在计算门控过程中代码过程如下
core_attn_out = torch.zeros(batch_size, num_heads, sequence_length, v_head_dim).to(value)
last_recurrent_state = (
torch.zeros(batch_size, num_heads, k_head_dim, v_head_dim).to(value)
if initial_state is None
else initial_state.to(value)
)
# q_t: (B, H, d_k)
# g_t: (B, H, 1, 1)
# beta_t: (B, H, 1)
for i in range(sequence_length):
q_t = query[:, :, i]
k_t = key[:, :, i]
v_t = value[:, :, i]
g_t = g[:, :, i].exp().unsqueeze(-1).unsqueeze(-1)
beta_t = beta[:, :, i].unsqueeze(-1)
last_recurrent_state = last_recurrent_state * g_t
kv_mem = (last_recurrent_state * k_t.unsqueeze(-1)).sum(dim=-2)
delta = (v_t - kv_mem) * beta_t
last_recurrent_state = last_recurrent_state + k_t.unsqueeze(-1) * delta.unsqueeze(-2)
core_attn_out[:, :, i] = (last_recurrent_state * q_t.unsqueeze(-1)).sum(dim=-2)
上述代码整个计算对应下面过程:$S_{t}=\alpha_{t} S_{t-1}+\beta_{t}\left(v_{t}-\alpha_{t} S_{t-1} k_{t}\right) k_{t}^{\top}$ 计算公式中 $\alpha_t$ 对应代码中的 g_t而 $\beta_t$就对应beta_t。通过这部分计算可以实现注意力计算的复杂度降低为 $O(T · d_k · d_v)$ 而对于上述公式中 $\alpha_t$主要是遗忘系数用来控制历史保留和检索衰减,$\beta_t$学习率控制新信息的写入强度,内部的 $v_{t}-\alpha_{t} S_{t-1} k_{t}$主要是用来预测残差只更新”记错的部分”,而非全部覆盖。
对于上述之所以这么计算简单理解如下:首先在最开始的Attention计算中是这样的:$O_t=\text{Softmax}(Q_tK_{1:t}^T)V_{1:t}=\sum_1^t \text{softmax}(Q_tK_i^T)V_i$ 也就是说在生成过程中每进入一个新的词($Q_t$)都需要去和前面所有的KV都进行计算,如果直接去掉内部的 $\text{softmax}$8那么就可以得到:$O_t≈\sum_1^t(Q_tK_i^T)V_i$ 此时这个等式可以满足交换运算顺序可以得到 $O_t=Q_t^T\sum_1^t K_iV_i^T$ 对于这个公式内部的 $\sum_1^t K_iV_i^T=S_{t-1}+K_tV_t^T$ 那么最后注意力计算过程(最朴素的线性注意力计算过程)为:
\(O_t=Q_t(S_{t-1}+K_tV_t^T))=Q_tS_{t-1}+Q_tK_tV_t^T\)
但是这个计算过程存在小问题:所有历史$S_{t-1}$都是平等重要,并且随着你推理长度变长新的信息就被淹没了,那么就可以直接 一次带遗忘 + 误差修正的外积更新,比如说对于最上面的公式可以直接写成:$\alpha_t(S_{t-1}-\beta_t K_tK_t^T)S_{t-1}+\beta_tV_tK_t^T$ 首先我的 $\alpha_t$ 就对应遗忘机制(对于我的$S_{t-1}$ 需要保存多少)而内部的就是一个误差更新机制(我的$t$对于历史状态有多少的影响)对于$\beta$也可以理解为新信息写入强度,最后回到代码里面这个 $S_{t-1}$就是我们缓存的KV-Cache。
简单解释一下里面 $\text{softmax}$ 作用:都知道计算 $QK^T$ 过程中我们相当于得到了token之间 “相似度”而后将整个相似度加权到 $V$上,而$\text{softmax}$在其中的作用就是去把原始相似度分数变成概率分布并且放大显著差异
总结
从QwenVL到QwenVL2.5视觉编码器处理过程:
QwenVL:将图像转化为固定的分辨率而后将输入到Vit-bigG进行处理得到视觉特征之后再去使用类似Q-former处理过程(QwenVL中使用的是一个随机初始化的单层Cross-Attention模块)使用learned-query(压缩到固定的256长度的token)将视觉token进行压缩而后输入到LLM中。
QwenVL2:首先使用动态分辨率(将图像除以固定的factor而后保持横纵比将其缩减到 [mix_pixels, max_pixels]中)去处理图像而后将其输入到视觉编码器中,而后将2x2的的相邻的token进行拼接(也就是将图像补充一个时间帧得到TCHW,而后再去在THW三个维度划分得到不同的patch:grid_t,grid_h,grid_w)到一个token而后通过MLP层进行处理。
QwenVL2.5:整体框架上和QwenVL2差异不大,区别在于使用了window-attention(主要是对数据进行切块而后在块内做注意力计算)以及2D-RoPE
QwenVL3:改进点在于使用DeepStack技术将Vit提取得到的视觉特征注入LLM Decoder的特定位置层中,而不是最开始只在输入层注入视觉信息
QwenVL3.5:改进点在于使用线性注意力机制$\alpha_t(S_{t-1}-\beta_t K_tK_t^T)S_{t-1}+\beta_tV_tK_t^T$主要参数 $\alpha$ 主要是控制历史信息重要性、$\beta$主要是控制当前信息重要性、内部计算 $KK^T$主要是进行方向引导