DeepSeek系列
DeepSeek v3.1
DeepSeek v3.11(简称DS)各类技术细节,对于DS在模型结构上和之前迭代版本的 DS-2无太大区别,还是使用混合专家模型,只是补充一个辅助损失去平衡不同专家之间的不均衡问题。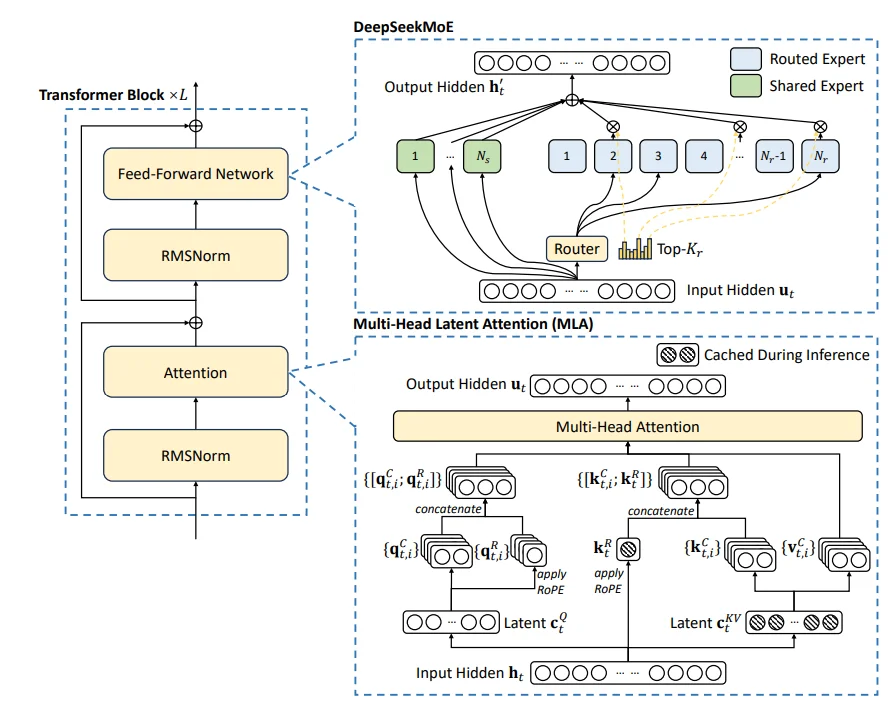
在结构上DS主要的创新点在于:1、Multi-Head Latent Attention;2、DeepSeekMoE。前者为优化 KV-cache 操作,通过一个低秩的$c_r^{KV}$代替原本占用较高的QV的值(首先通过降维方式降低原本维度,这样一来在显存占用上就会降低,而后通过升维方式,恢复到原本的维度),后者为混合专家模型,不过区别于常用的MoE方法,在DS中将专家模型分为两类:1、Routed Expert;2、Shared Expert,前者直接将隐藏层的输入进行传入,后者则是通过门控网络筛选而后隐藏层的输入进行传入。
除此之外,在DS中使用Multi-Token Prediction(MTP)技术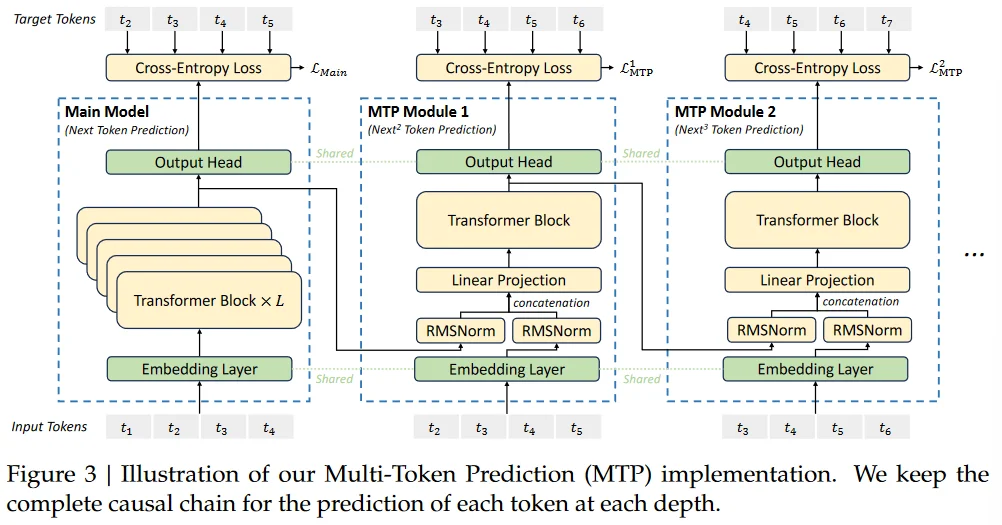
在DS中一个很耀眼的功能就是:DeepSeek-R1(一种思维链技术:CoT:Chain of Thought,在GPT-o1中也使用到这种技术)结合论文2中对 CoT技术的描述,可以简单的理解为:让LLM可以自主去思考问题,相较之直接让GPT输出答案,区别在于还要他给出推理过程,比如说在DeepSeek中对于思维链的prompt:
直接让模型去输出think内容,一般而言如果要训练一个具有思维链功能的模型可以简单按照如下过程进行处理:
# 数据集简单类型
{
"instruction": "请一步一步思考并解答以下问题。",
"input": "小明有5个苹果,给了小红3个,还剩多少?",
"output": "<think>第一步:...\n第二步:...\n第三步:...</think>答案:2个"
}
# 微调模型过程中 prompt
你是一个严谨的推理助手,回答任何问题前必须先在 <think> 标签内进行完整逐步思考,再给出最终答案。
通过上面简单过程去“强迫”模型去输出思考过程而不是直接就给出答案。除此之外在DS-R1中模型的整体训练过程使用Group Relative Policy Optimization(GRPO)策略进行优化
对于上述优化过程理解:比如说对于一个数学问题:$8+5=?$,这就是上面公式中所提到的question $q$,按照上面的描述,将会生成一系列的输出:${o_1,…,o_G}$
Step-1:生成若干的回答。${o_1,…,o_G}$
Step-2:对于生成的回答进行评分。${r_1,…,r_G}$,而后计算$A_i=\frac{r_i- \text{mean}({r_1,…,r_G})}{\text{std}({r_,…,r_G})}$
Step-3:使用裁剪更新策略:$\text{clip}(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}(o_i|q)}},1-\epsilon,\epsilon)$比如说:如果新策略开始给o1分配过高的概率,裁剪机制确保不会过度强调这个响应。这种方式保证了即使在像推理这样复杂的任务中,策略优化也能保持稳定和可靠。通过clip函数将内部值限定在$(1-\epsilon, 1+\epsilon)$之间
Step-4:通过KL散度(用来度量两个概率分布相似度的指标)惩罚偏差
DeepSeek v3.2

论文中核心点就是Native Sparse Attention,在上一代的MLA中通过对KV-cache进行压缩(降维压缩升维还原)能够有效的节省KV-cache的缓存大小,但是计算复杂度上还是 $O(L^2)$因此在 v3.2中提出的Native Sparse Attention核心点就是去缩小计算的复杂度为 $O(LK)$,其核心计算过程如下:Native Sparse Attention主要是在MLA的基础上补充了一个 lighting indexer主要过程如下
\(I_{t,s} = \sum_{j=1}^{H^I} w_{t,j}^I \cdot \text{ReLU} \left( \mathbf{q}_{t,j}^I \cdot \mathbf{k}_s^I \right)\)
表示在完成 Q-K 点积之后,用于预测哪些 token 在当前上下文中最为重要。具体实现上,在每个注意力层前会增加一个轻量级索引头,该索引头使用低精度(FP8)计算当前 Query 与所有历史 Key 的粗略相似度分数。随后,从这些分数中选出 top-k 个最相关的历史位置,仅将这 k 个 Key/Value 输入后续的正式注意力计算。通过这种方式,可以显著降低注意力计算的 FLOPs 与内存占用,同时保持长序列的关键依赖关系。在代码实现过程整体的部分和MLA相似关键在于 Indexer 过程
qr = self.q_norm(self.wq_a(x))
q = self.wq_b(qr)
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
...
if mask is not None: # 训练阶段
q = torch.cat([q_nope, q_pe], dim=-1)
kv = self.wkv_b(kv)
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
scores = torch.einsum("bshd,bthd->bsht", q, k).mul_(self.softmax_scale)
# indexer
topk_indices = self.indexer(x, qr, start_pos, freqs_cis, mask)
index_mask = torch.full((bsz, seqlen, seqlen), float("-inf"), device=x.device).scatter_(-1, topk_indices, 0)
index_mask += mask
scores += index_mask.unsqueeze(2)
scores = scores.softmax(dim=-1)
x = torch.einsum("bsht,bthd->bshd", scores, v)
else: # 模型推理阶段
if self.dequant_wkv_b is None and self.wkv_b.scale is not None:
self.dequant_wkv_b = weight_dequant(self.wkv_b.weight, self.wkv_b.scale)
wkv_b = self.wkv_b.weight if self.dequant_wkv_b is None else self.dequant_wkv_b
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
# indexer
topk_indices = self.indexer(x, qr, start_pos, freqs_cis, mask)
index_mask = torch.full((bsz, 1, end_pos), float("-inf"), device=x.device).scatter_(-1, topk_indices, 0)
scores += index_mask.unsqueeze(2)
scores = scores.softmax(dim=-1)
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
在训练过程中:对于里面的 self.indexer(x, qr, start_pos, freqs_cis, mask) 输入的分别是原始的输入x以及通过压缩后的q,具体处理过程中,对于压缩后的q以及原始的输入x进行矩阵计算–>拆分(一部分去计算RoPE)–>两部分进行拼接分别得到Q、K的值对于这两部分的值,而后再去计算 Fast Walsh–Hadamard transform转换(让数值分布均匀),再去将q、k的值转换到fp8再去计算 index_score = fp8_index(q_fp8.contiguous(), weights, self.k_cache[:bsz, :end_pos].contiguous(), self.k_scale_cache[:bsz, :end_pos].contiguous()) 在得到index_score之后直接获取每一个token的重要性再去将其融入到最后的socre中即可。
在回过头去看模型解码过程中这个注意力方式是如何节约计算量的:传统的KV-cache操作中缓存大小是 $O(LHD)$ (分别表示序列长度、注意力头数、每个头维度) 通过MLA压缩得到 $O(LC)$ 在传统的QK计算中复杂度是 $O(L^2D)$ 使用MLA后计算量是 $O(L^2C)$,通过idnexer去选取top-k又可以降低到 $O(LkC)$。这是因为indexer 可以快速预测每个 query 对哪些历史 token 最感兴趣,只需要对这 k 个 token 进行正式的 Q-K 点积和 V 聚合,而不必对所有 L 个历史 token 计算,从而将 $O(L^2)$ 的复杂度降低到 $O(Lk)$。 在代码实现中,为了兼容 dense attention,通常会使用 mask 将非 top-k 的 token 对应的 score 设置为 $-\infty$。
很多人可能和我有一个疑问,你计算QK值而后通过topk获取需要关注的token而后将这个token作为一个mask叠加在score上,这一套下来计算量似乎和原始的没有差异?其实关键点就在这个mask上,我将socre通过mask(比如就是一个上三角矩阵)处理之后只有一半的socre了,那么这一半的socre就可以直接通过写算子去优化计算复杂度!!比如说可以直接测试
F.scaled_dot_product_attention(q, k, v, is_causal=False)低于 is_causal 参数分别设置True/False去对比计算时间。
DeepSeek OCR
DeepSeek OCRv1
DeepSeek OCR3主要内容就是尝试使用视觉的方式去压缩长文本上下文,按照论文里面的描述就是:$f_{dec}:R^{n\times d_{latent}}\rightarrow R^{N\times d_{text}}, \hat{X}=f_{dec}(X)$
前面部分代表压缩的视觉tokens后面代表重构的文本表述。其实从上面公式就可以了解在DeepSeek OCR中做的就是:对于原始文本输入需要较长的tokens数量(比如说1w个字),但是如果这1w个文本都在图片上可能就是512个tokens。
但是作者只是在OCR邻域做测试,正如论文里面说的: It is reasonable to conjecture that LLMs, through specialized pretraining optimization, would demonstrate more natural integration of such capabilities.
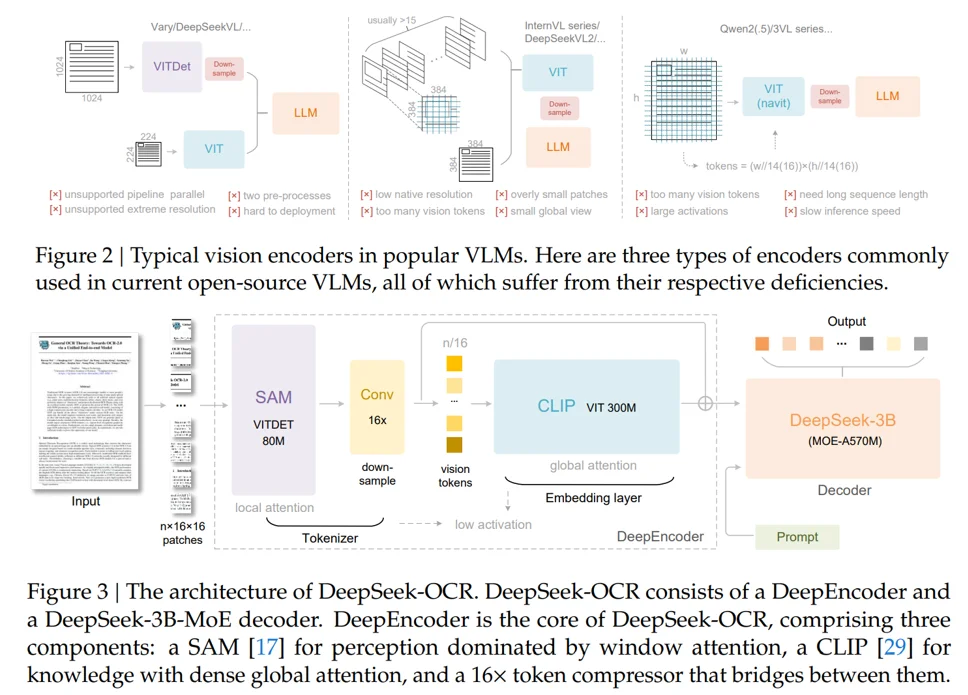
对于传统多模态中的视觉结构:第一种使用多个视觉编码器进行编码处理,第二种:将图片切割为不同的patch而后进行处理,第三种:使用动态分辨率而后将图片去切割为不同patch进行编码。论文中使用的模型结构(为了实现:1、处理高分辨率;2、高分辨率小低激活;3、较少的视觉tokens;4、支持多分辨率输入;5、计算参数少)为:SAM-base(patch-size:16)+Conv(2层,kernel_size=3,strid=2, paddingg=1去对视觉token进行16倍下采样)+CLIP-large(去掉patch-embedding因为我的输入就是patch了),那么对于1024x1024首先划分为1024/16 × 1024/16 = 4096个patch token,在对4096个token进行压缩,数量变为4096/16 = 256。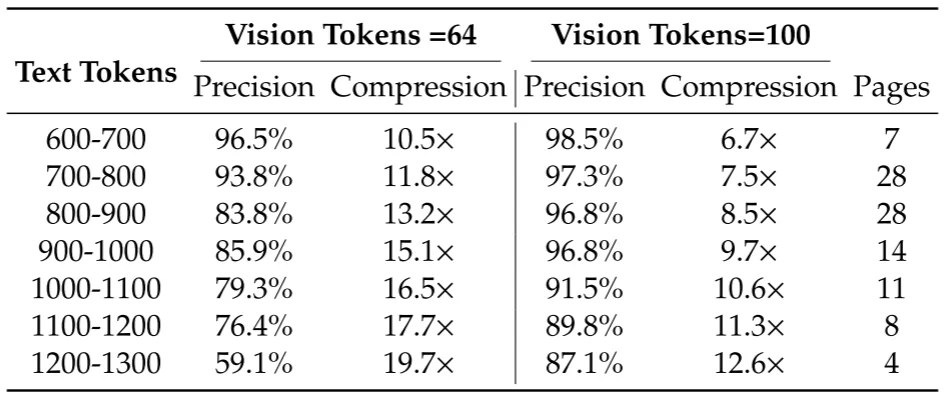
在许多论文里面也用到了压缩技术(截至到:2025.10.23部分论文),比如说Glyph(Zhipu-清华)4和另外一篇论文5
对于这些内容核心的思路都是将文本转化为image来进行压缩tokens比如在论文[^11]中直接将text转化为latex格式的图片而后通过模型进行处理。