各类LLM模型技术汇总
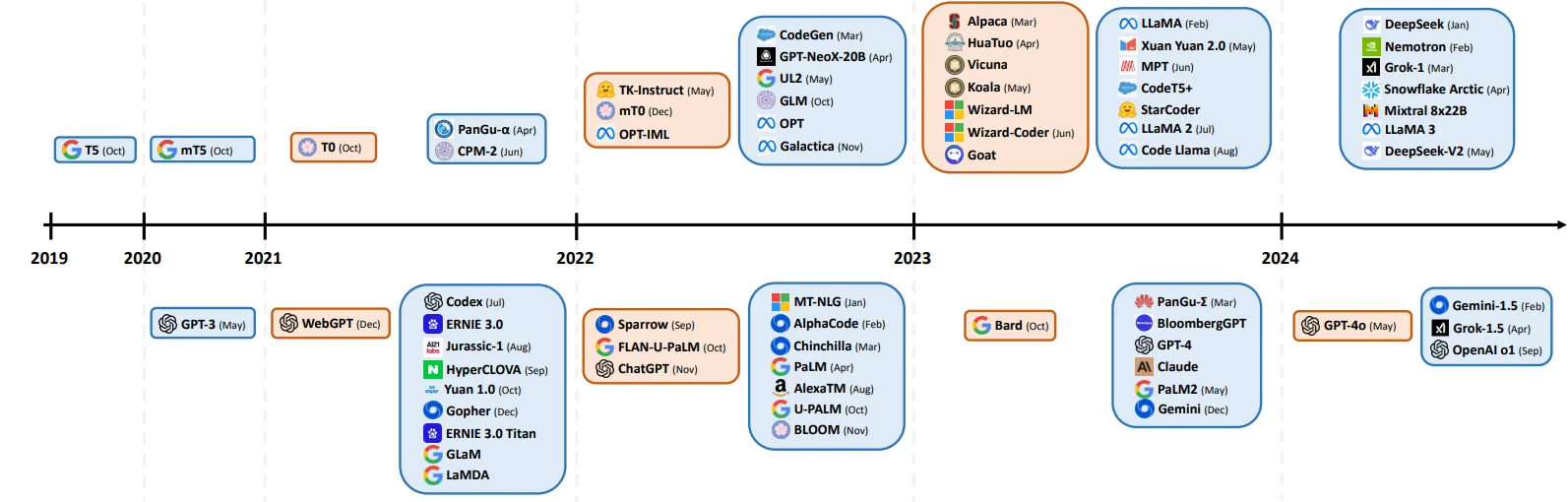
只去对比整体1框架,对所采用的激活函数,归一化处理,位置编码等参考:
1、位置编码:https://www.big-yellow-j.top/posts/2025/02/03/pos-embedding.html
2、归一化处理:https://www.big-yellow-j.top/posts/2025/01/05/dl-norm.html
3、分布式训练:https://www.big-yellow-j.top/posts/2025/01/03/DistributeTraining.html
GPT系列
1.GPT v1
对于大部分的深度学习任务,需要大量的标记数据(labeled data),但是如果使用大量的标记数据就会导致一个问题:构建得到的模型缺少适用性(可以理解为模型的泛化性能可能不佳)。那么就尝试使用非标记的数据(unlabelled data)但是这样一来又会有一个新的问题:时间消费大(time-consuming and expensive)。所以目前学者提出:使用预训练的词嵌入来提高任务性能。使用 未标注的文本信息(word-level information from unlabelled text)可能会:1、不清楚那种优化目标(optimization objective)在学习对迁移有用的文本表示时最有效;2、如何将这些学习到的表征有效的迁移到目标任务(target task)中。
作者提出:1、无监督的预训练(unsupervised pre-training);2、监督的微调(supervised fine-tuning)
1、Unsupervised pre-training
给定一些列的的无标签的 token:$U={u_1,…,u_n}$,构建自回归的模型:
其中 $\theta$为模型的参数。作者在模型中使用 Transforme作为 decoder,在最后的模型上作者构建得到为:
\[h_0= UW_e+W_p \\ h_l = transformer\_block(h_{l-1})\forall i \in [1,n]\\ P(u)=softmax(h_nW_e^T)\]其中$n$代表神经网路层的数目,$W_e$代表 token embedding matrix,$W_p$代表 position embedding matrix。对于无监督下的预训练:通过构建的数据集,去对模型的参数进行训练,得到模型的参数。
2、Supervised fine-tunning
作者在此部分提到:通过第一步得到的模型参数去对监督任务进行训练(采用的模型结构是没有变化的)。给定标签数据集$C$,给定输入:${x^1,…,x^m }$以及其标签$y$。将数据投入到预训练得到的模型参数里面得到:$h_l^m$,然后添加一个线性输出层(参数为:$W_y$)去对$y$进行预测。
对于上述两部分步骤直观上理解:人首先从外界获取大量信息:网络,书本等,把这些信息了解之后,然后去写作文或者去回答问题。
模型结构:
2.GPT v2
GPT v2区别前一个模型,区别在于将layer-norm 位置替换到每一个残差连接块的里面,也就是说在数据输入到 Multi-Head-Attention 以及 Feed-Forward 之前提前通过一层标准化处理。
3.GPT v3
GLM系列
GLM v1
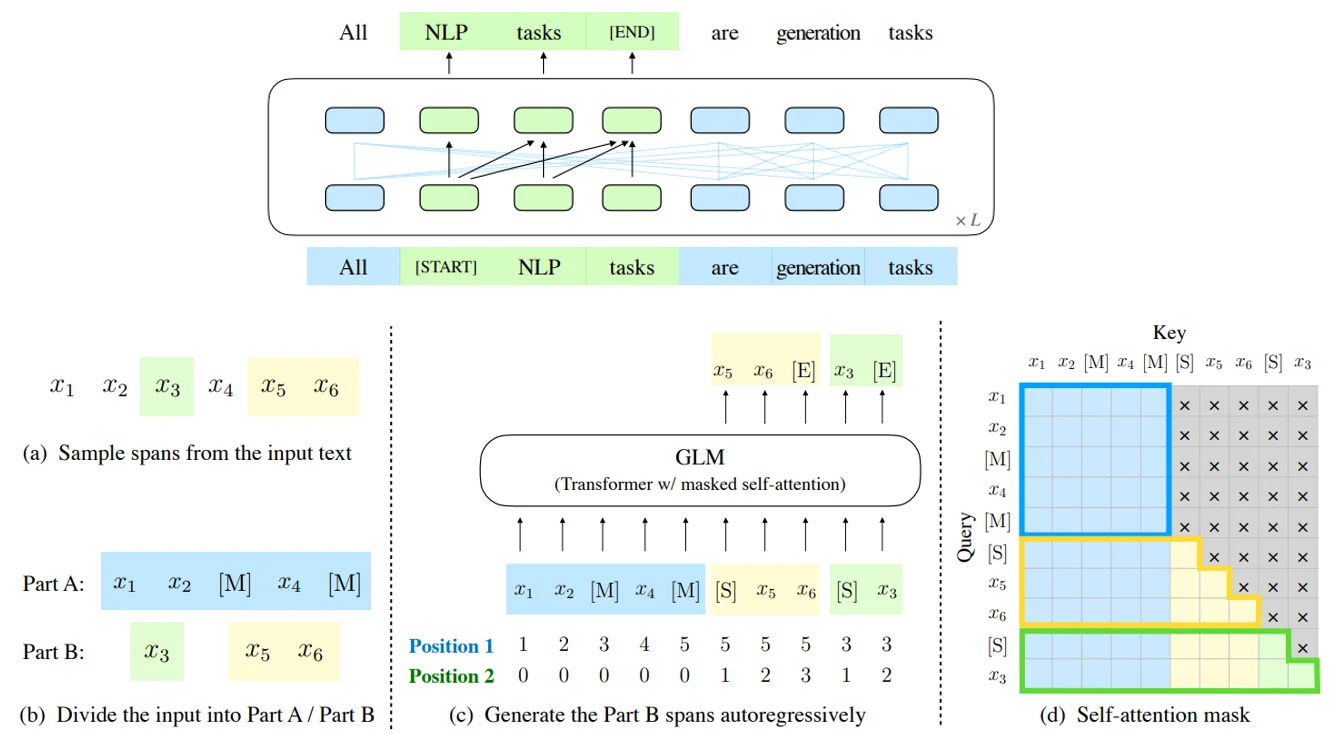
训练过程任务大致如上描述2,用更加数学的描述是从输入文本$x=[x_1,…,x_n]$中随机采样多个文本片段${s_1,…,s_m}$ 对于每个片段都对应$x$ 中一系列的连续文本,对于采样的文本片段通过[MASK]进行标记这样一来我的输入就变为了 $x_{corrupt}$而后模型就通过自回归的方式去文本中预测缺失的词,这意味着在预测一个片段中的缺失词时,模型以自回归的方式从损坏的文本和之前预测的片段。为了充分捕捉不同片段之间的相互依赖关系,通过随机打乱片段的顺序,类似于排列语言模型,对应上面图中的b、c。除此之外模型还有的改进如下:
1、二维位置编码:第一个位置id用来标记Part A中的位置,第二个位置id用来表示跨度内部的相对位置。这两个位置id会通过embedding表被投影为两个向量,最终都会被加入到输入token的embedding表达中
Qwen模型系列
以Qwen23为例用经过修改的 Transformer 架构,并采用了最近流行的大型语言模型(LLAMA)的训练方法,Qwen对架构的修改包括:
1、Embedding and output projection。根据初步实验结果,Qwen选择了非约束的嵌入方法,而不是将输入Embedding和输出projection的权重绑定在一起。为了在内存成本上取得更好的性能,Qwen做出了这个决定。
2、Positional embedding。Qwen选择Rotary Positional Embedding(RoPE,旋转位置编码)作为首选选项,以将位置信息纳入Qwen的模型中。RoPE已被广泛采用,并已在当今大型语言模型中取得了成功,尤其是PaLM和LLAMA。特别是,Qwen选择使用FP32精度来计算逆频率矩阵,而不是BF16或FP16,以便优先考虑模型性能并实现更高的准确性。
3、Bias。对于大多数层,Qwen遵循陈卓辉等人的做法删除偏差,但对于注意力中的QKV层添加了偏差,以增强模型的外推能力。
4、Pre-Norm& RMSNorm。在Transformer模型中,预归一化是最常用的方法,它已被证明比后归一化更能提高训练稳定性。此外,Qwen用RMSNorm取代了传统层归一化技术。这一改变带来了相同的表现水平,同时也提高了效率。
5、Activation function。Qwen选择了SwiGLU作为激活函数,它是Swish和门控线性单元的组合。Qwen的初始实验证明,基于GLU的激活函数通常优于其他基准选项,如GeLU。与以往研究常见的做法一样,Qwen将前馈网络(FFN)的维度从Hidden size的四倍减少到三分之八的Hidden size。
QWenLMHeadModel(
(transformer): QWenModel(
(wte): Embedding(151936, 4096)
(drop): Dropout(p=0.0, inplace=False)
(rotary_emb): RotaryEmbedding()
(h): ModuleList(
(0-31): 32 x QWenBlock(
(ln_1): RMSNorm()
(attn): QWenAttention(
(c_attn): Linear(in_features=4096, out_features=12288, bias=True)
(c_proj): Linear(in_features=4096, out_features=4096, bias=False)
(attn_dropout): Dropout(p=0.0, inplace=False)
)
(ln_2): RMSNorm()
(mlp): QWenMLP(
(w1): Linear(in_features=4096, out_features=11008, bias=False)
(w2): Linear(in_features=4096, out_features=11008, bias=False)
(c_proj): Linear(in_features=11008, out_features=4096, bias=False)
)
)
)
(ln_f): RMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=151936, bias=False)
)
DeepSeek系列
主要介绍DeepSeek v34(简称DS)各类技术细节,对于DS在模型结构上和之前迭代版本的 DS-2无太大区别,还是使用混合专家模型,只是补充一个辅助损失去平衡不同专家之间的不均衡问题。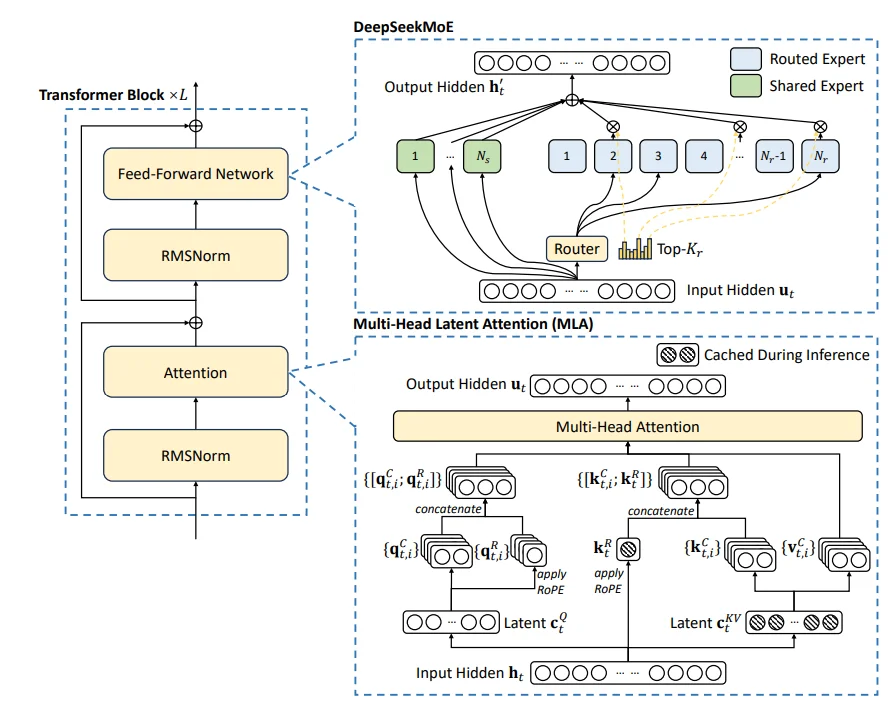
左侧结构和 GPT-2结构类似
在结构上DS主要的创新点在于:1、Multi-Head Latent Attention;2、DeepSeekMoE。前者为优化 KV-cache 操作,通过一个低秩的$c_r^{KV}$代替原本占用较高的QV的值(首先通过降维方式降低原本维度,这样一来在显存占用上就会降低,而后通过升维方式,恢复到原本的维度),后者为混合专家模型,不过区别于常用的MoE方法,在DS中将专家模型分为两类:1、Routed Expert;2、Shared Expert,前者直接将隐藏层的输入进行传入,后者则是通过门控网络筛选而后隐藏层的输入进行传入。
除此之外,在DS中使用Multi-Token Prediction(MTP5)技术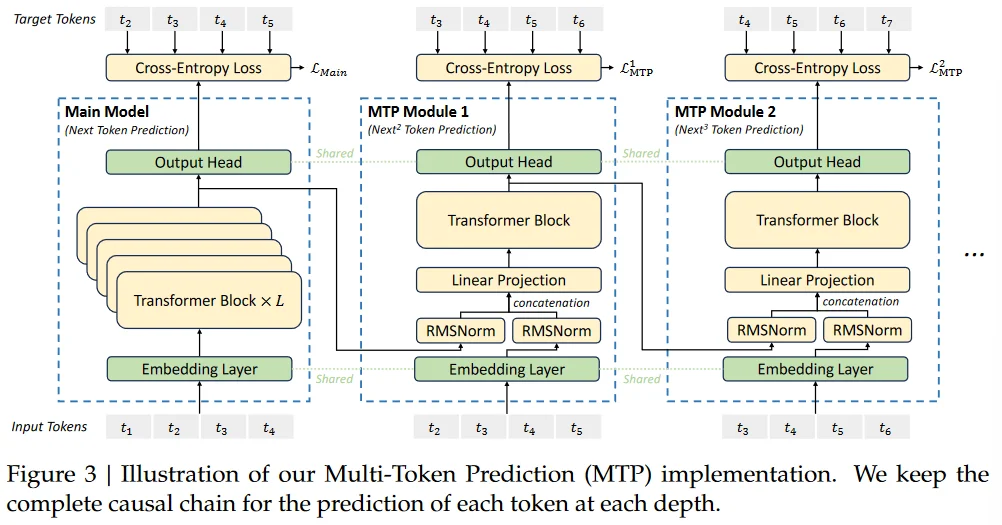
在DS中一个很耀眼的功能就是:DeepSeek-R1(一种思维链技术:CoT:Chain of Thought,在GPT-o1中也使用到这种技术)结合论文6中对 CoT技术的描述,可以简单的理解为:让LLM可以自主去思考问题,比如在论文6中对 CoT技术的描述。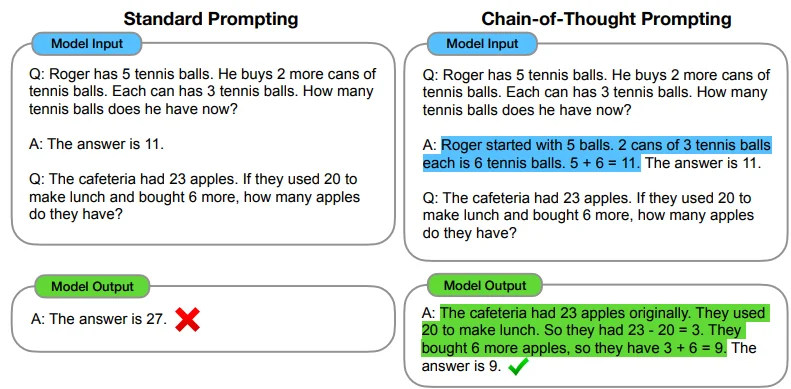
相较之直接让GPT输出答案,区别在于还要他给出推理过程。结合在DS-R14中的描述对于 DS-R1整体过程理解如下: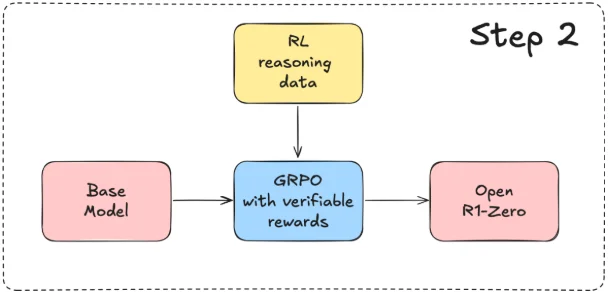
非常明显的一个强化学习过程,在论文里面提到的使用 Group Relative Policy Optimization(GRPO)7策略进行优化
在 DS-R1中作者提到的使用的模板
对于上述优化过程理解:比如说对于一个数学问题:$8+5=?$,这就是上面公式中所提到的question $q$,按照上面的描述,将会生成一系列的输出:${o_1,…,o_G}$
Step-1:生成若干的回答。${o_1,…,o_G}$
Step-2:对于生成的回答进行评分。${r_1,…,r_G}$,而后计算$A_i=\frac{r_i- \text{mean}({r_1,…,r_G})}{\text{std}({r_,…,r_G})}$
Step-3:使用裁剪更新策略:$\text{clip}(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}(o_i|q)}},1-\epsilon,\epsilon)$比如说:如果新策略开始给o1分配过高的概率,裁剪机制确保不会过度强调这个响应。这种方式保证了即使在像推理这样复杂的任务中,策略优化也能保持稳定和可靠。通过clip函数将内部值限定在$(1-\epsilon, 1+\epsilon)$之间
Step-4:通过KL散度(用来度量两个概率分布相似度的指标)惩罚偏差
PPO和 GRPO
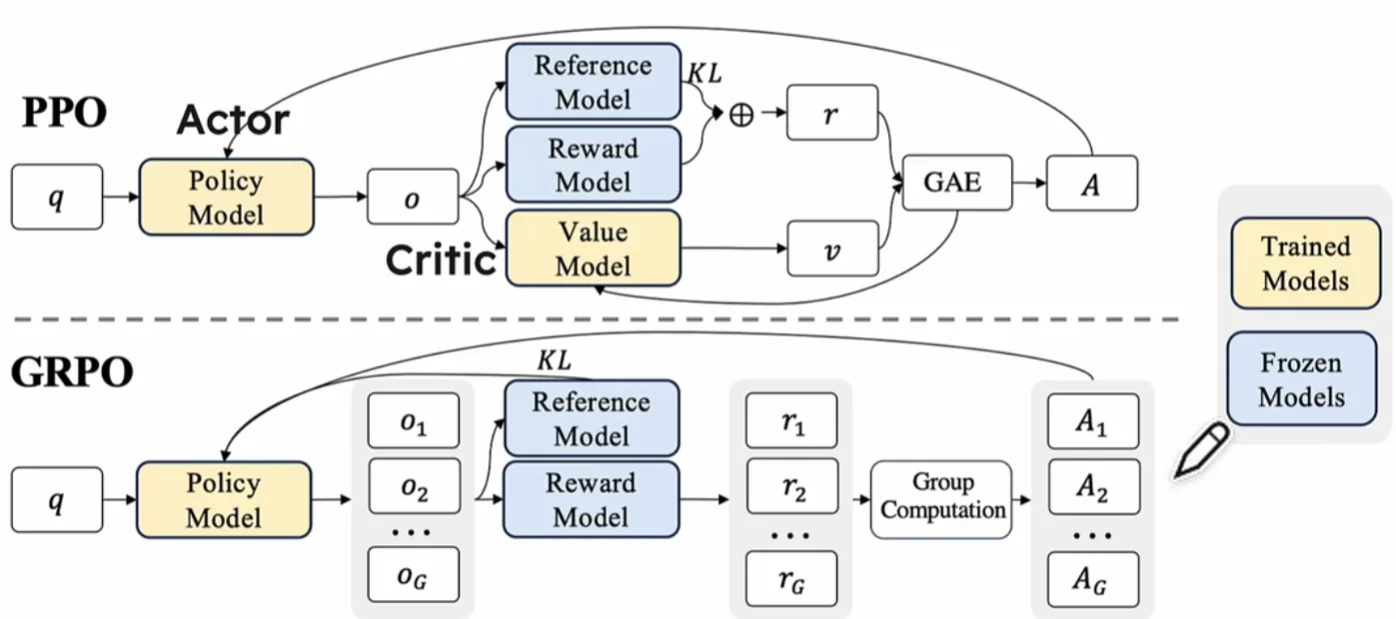
上面提到的几个模型:
1、Policy Model:我们需要优化的模型
2、Value Model:估计状态的价值,帮助指导策略优化
3、Reference Model:提供历史策略的参考,确保优化过程中策略变化不过度
4、Reward Model:定义奖励信号,用于强化学习中的奖励反馈
GRPO实现,参考腾讯以及 Github上实现代码,对于复现可以直接用Huggingface中的 trl来进行复现
LLama系列
LLama v1
LLaMA8 所采用的 Transformer 结构和细节,与标准的 Transformer 架构不同的地方包括采用了前置层归一化(Pre-normalization)并使用 RMSNorm归一化函数、激活函数更换为 SwiGLU,并使用了旋转位置嵌入(RoP),整体 Transformer 架构与 GPT-2 类似,大致模型结构如下: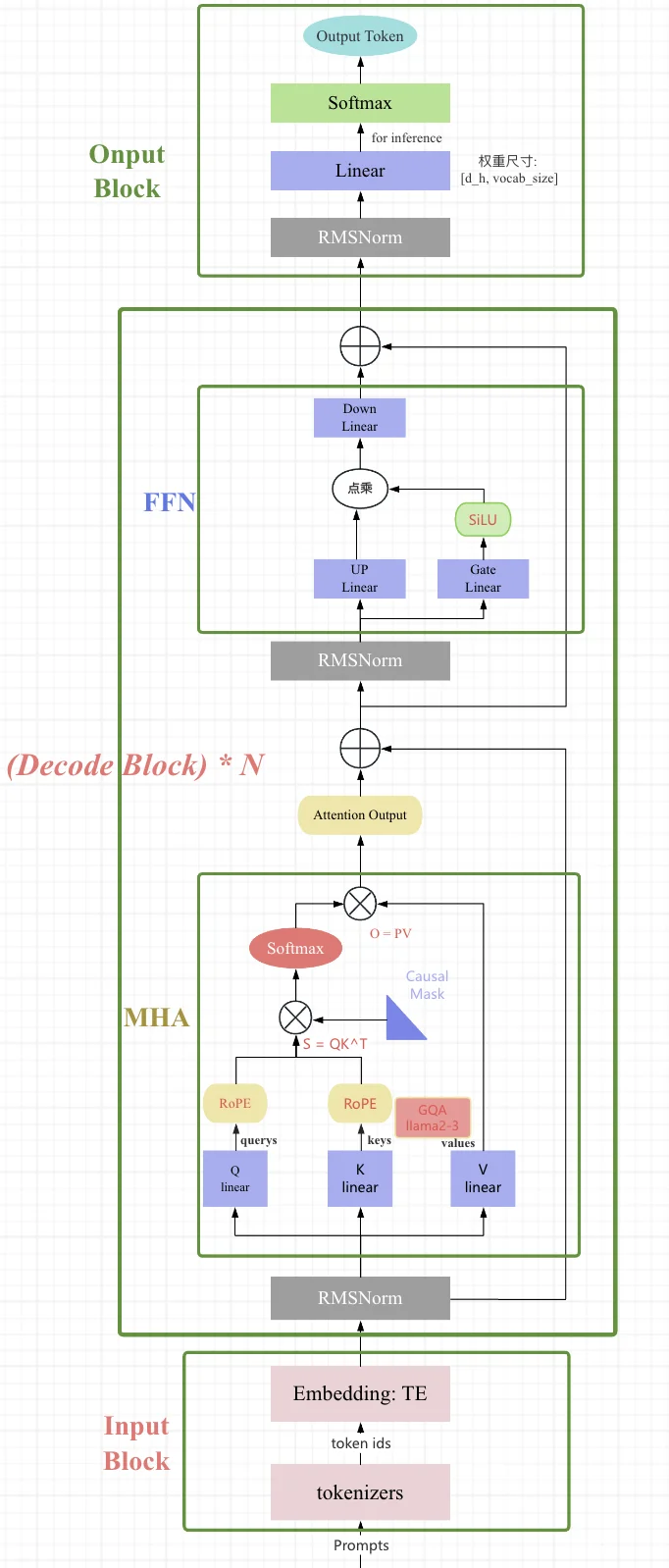
image from: https://zhuanlan.zhihu.com/p/625775403
1、RMSNorm归一化函数:论文假设 LayerNorm 中的重新中心化不再是必须的(平移不变性不重要),RMSNorm 通过均方根(RMS)对每一层神经元的输入进行归一化,使模型具备重新缩放不变性和隐式学习率调整的能力。相比LayerNorm,RMSNorm计算更为简洁,大约可以节省 7% 到 64% 的运算。
\[\begin{aligned} \text{RMSNorm}(x) &: \hat{x}_i = \gamma \odot \frac{x_i}{\text{RMS}(x)} \\ \text{RMS}(\mathbf{x}) &= \sqrt{\frac{1}{d} \sum_{x_i \in \mathbf{x}} x_i^2} \end{aligned}\]和LayerNorm之间差异在于后者归一化处理计算就是常规的归一化(减均值然后除方差),但是在rmsenorm中直接除均方根,除此之外
2、SwiGLU激活函数:SwiGLU 激活函数与 GELU 激活函数类似,但 GELU 激活函数的计算速度更快,并且 GELU 激活函数的输出范围更广,因此 SwiGLU 激活函数被用于 LLaMA 模型。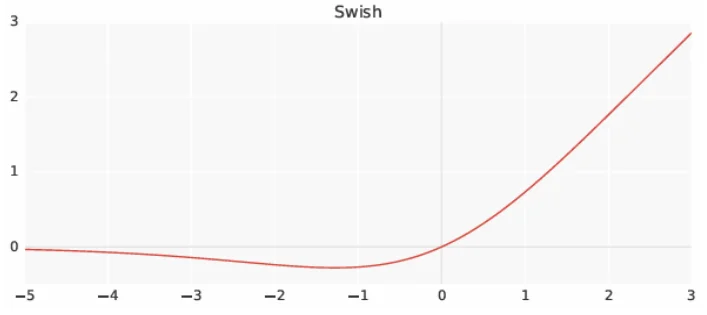
其中a、b代表的就是两个线性变化输出(如$a=xW_1+b_1$),$Swish(a) = Sigmoid(\beta a) \cdot a$,和FFN结合代码为:
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim):
super().__init__()
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
def forward(self, x):
# SwiGLU: (SiLU(W1x) * W3x) @ W2
return self.w2(F.silu(self.w1(x)) * self.w3(x))
3、RoPE旋转位置编码:文本序列是一种“顺序化”序列(文本字符之间排序对于文本的结果存在影响),因此通过位置编码去表示不同位置的输入,从而提高模型对长文本的生成效果。对于RoPE通俗的解释就是:就是对于输入调整向量乘以一个旋转矩阵(内积矩阵),但是为了使用绝对位置信息还会去补充参数m。在Llamav1中处理方式为:对于 token 序列中的每个词嵌入向量,都计算其对应的 query 和 key 向量;然后在得到 query 和 key 向量的基础上,对每个 token 位置都计算对应的旋转位置编码;接着对每个 token 位置的 query 和 key 向量的元素按照两两一组应用旋转变换;最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。
LLama v2
区别于上一代的LLama v1在LLama v29中改进如下几点:
1、序列长度:由原来的2048 tokens变化为4096 tokens
2、使用GQA:通过使用KV-cache可以加快模型生成速度,但是也会造成过大的显存占用,因此LLama v2在decode阶段使用GQA来减少这个过程中的显存占用。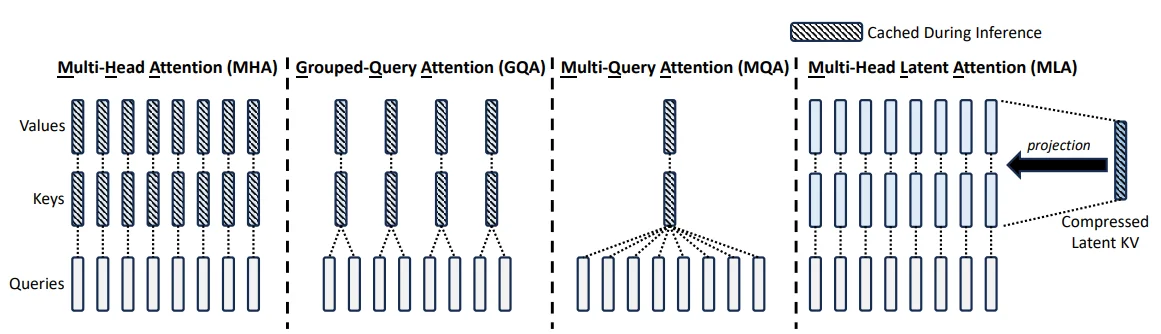
在LLama v2中对于GQA10实现如下:
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
# 根据n_rep,拓展KV
if n_rep == 1:
return x
return (x[:, :, :, None, :].expand(bs, slen, n_kv_heads, n_rep, head_dim).reshape(bs, slen, n_kv_heads * n_rep, head_dim))
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
...
self.n_local_heads = args.n_heads // model_parallel_size #Q的头数
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size #KV的头数
self.n_rep = self.n_local_heads // self.n_local_kv_heads
...
self.wq = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim, # Q的头数* head_dim
...)
self.wk = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim, # K的头数* head_dim
...)
self.wv = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,# V的头数* head_dim
...)
self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,... )
self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads, #KV的头数
self.head_dim,)).cuda()
self.cache_v = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,#KV的头数
self.head_dim,)).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis) #嵌入RoPE位置编码
...
# 按此时序列的句子长度把kv添加到cache中
# 初始在prompt阶段seqlen>=1, 后续生成过程中seqlen==1
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
# 读取新进来的token所计算得到的k和v
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
#计算q*k
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
#加入mask,使得前面的token在于后面的token计算attention时得分为0,mask掉
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
LLama v3
模型11参数细节: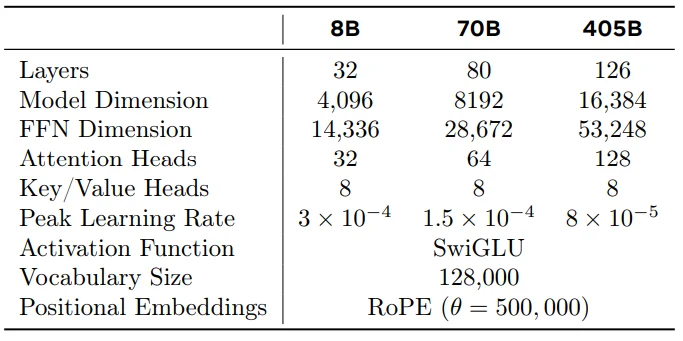
BERT
BERT12训练主要分为如下阶段,预训练阶段任务:
1、Masked LM(MLM)
MLM是一种预训练任务,通过随机掩蔽输入序列中的部分词元,模型根据上下文预测被掩蔽的词元,从而学习双向语言表示。在模型中作者按照:80:10:10的比例进行处理(80:将词元替换为[MASK];10:将词元替换为词汇表中随机选取的其他词。;10:保持原词元不变)
例子:
输入:“今天天气真好,我打算去[MASK]。”
模型的任务是根据上下文预测“[MASK]”应该是“公园”。
2、Next Sentence Prediction(NSP)
NSP是一种预训练任务,模型接收两个句子并预测第二个句子是否是第一个句子的后续。该任务帮助模型理解句子间的逻辑关系。
例子:
句子对:
句子1:“我喜欢去公园散步。”
句子2:“今天下午我会去跑步。”
模型的任务是判断第二个句子是否是第一个句子的自然延续,答案是“是”。
- 缺点
1、BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy(忽略了屏蔽位置之间的依赖性,并遭受预训练微调差异的影响)
这是因为在 BERT模型中,在预训练阶段会添加 [MASK],但是在 下游任务(downsteram tasks)中并不会使用 [MASK]
参考
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning ↩ ↩2
Better & Faster Large Language Models via Multi-token Prediction ↩
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ↩ ↩2
The Math Behind DeepSeek: A Deep Dive into Group Relative Policy Optimization (GRPO) ↩
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩