本文主要介绍几篇图像擦除论文模型:RORem、ObjectClear
RORem
https://arxiv.org/pdf/2501.00740
https://github.com/leeruibin/RORem
基座模型:SDXL
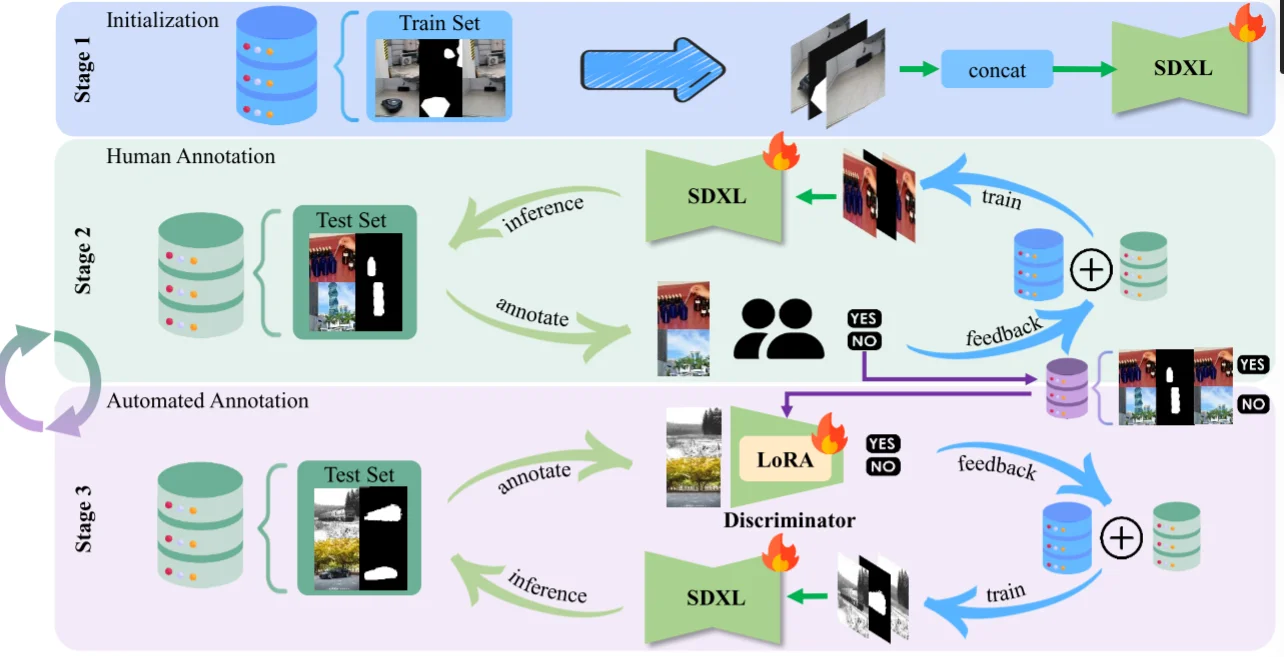
数据集选择的是 RORD(通过视频帧中前后变化的物体就是mask进而构建高质量数据集)以及 Mulan数据集。对于输入到SDXL中的数据为:1、mask;2、原始图片;3、消除mask后的图片。而后将这三部分数据进行concat。
只通过上面过程微调的SDXL模型效果不佳,然后(上图的Human Annotation过程)再去从开源数据集中进行筛选(排除部分例子如:衣服、身体等)保证每种实体都有500种再得到数据之后然后就是人工筛选出高质量和低质量数据集。但是整个过程是消耗时间的因此会训练一个判别器网络结构(将SDXL-Inpainting中的下采样和中间层作为backbone而后通过Lora进行微调)通过人工筛选的数据集进行训练进而实现自动化过程(只有判别器得分>0.9的数据集才能算“合格”)。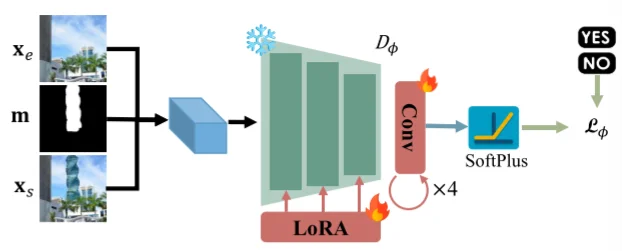
本路文中(纯力大飞砖,通过构建大规模数据集去微调模型)对于模型改进不大,为例加速消除过程,再去通过蒸馏得到LCM模型来加速消除过程(从4s到0.5s)。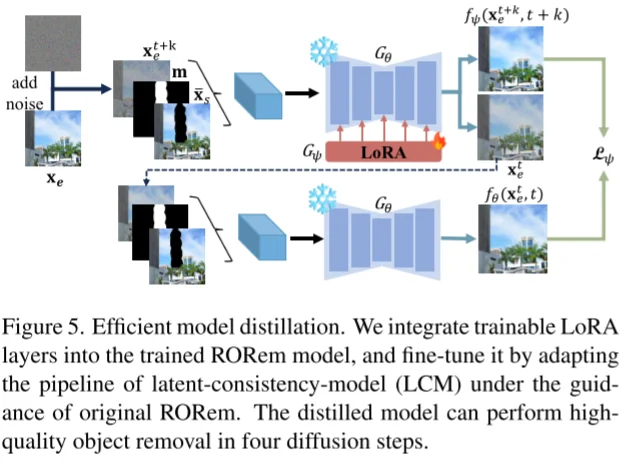
ObjectClear
https://arxiv.org/pdf/2505.22636
https://github.com/zjx0101/ObjectClear
基座模型:SDXL-Inpainting
本文出发点主要为两个:1、创建数据集;2、通过引入注意力机制(attention-mask)去引导模型消除,处理思路和论文:https://arxiv.org/pdf/2403.18818很相似
数据集构建
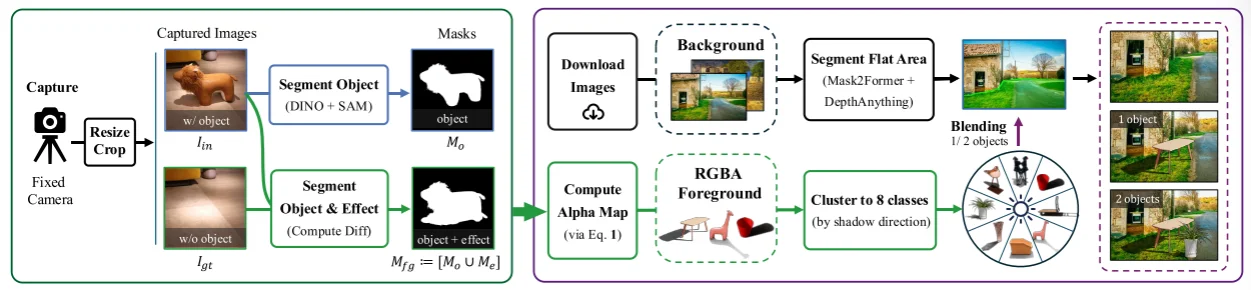
主要为两部分数据集(数据集构建方式上和SmartEraser论文里面处理方式相似:首先分割小实体是从图像中通过检查(DINO/YOLO等)加分割(SAM等)得到“小实体”而后将这些“小实体”去“合理”的贴到图像中):1、拍摄数据集(2875张图片);2、开源下载数据集。对于 拍摄数据集处理方式:首先将图片处理为512x512而后,直接通过DIBO+SAM去识别然后切割实体得到mask($M_o$)然后去结合“mask相关的语义特征”(比如说阴影 $M_e$ 等)得到$M_{fg}=[M_o,M_e]$。除此之外对于下载得到的数据集首先是通过Mask2former(切割图像中的实体然后将一些特殊实体(比如说road等)作为背景)+DepthAnythin(通过整个算法去保证后续贴图的质量)后续就是直接将从相机拍摄照片里面抽取出来的小实体帖带开源数据集中。
模型结构
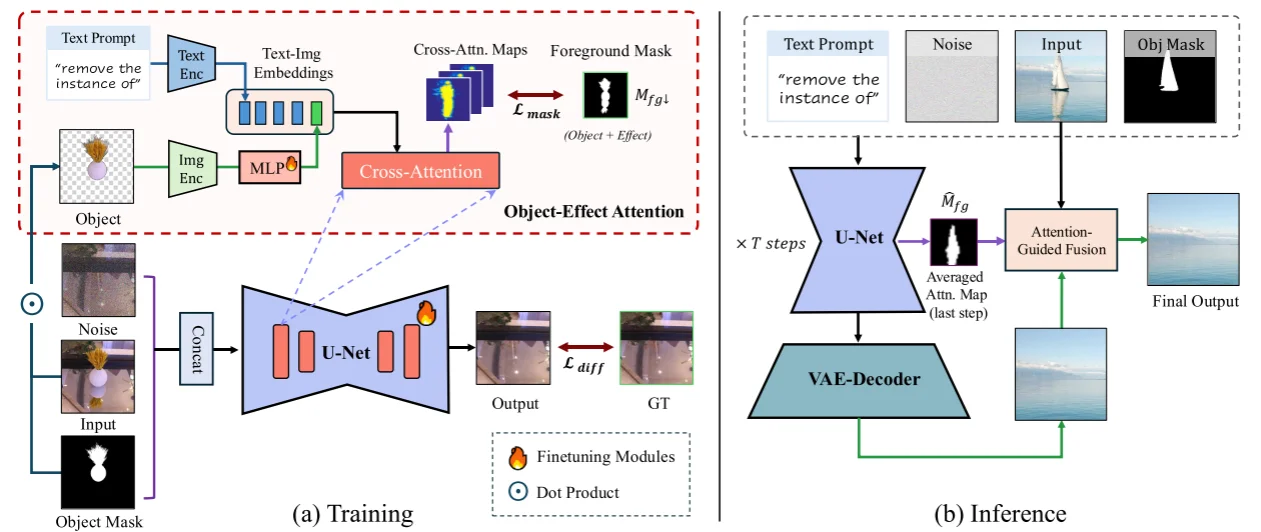
将基座模型(SDXL-Inpainting)的输入(1、噪声分布$z_t$;2、masked image $I_m$这个一般就是直接将mask从图中扣除;3、mask:$M_o$;4、文本prompt:$c$)中的mask image替换为原始的图像:$I_{in}$(这和之前的SmartEraser处理方式类似),除此之外对于输入DF模型中的处理思路和SmartEraser也是相似的:图像(需要消除的)和文本分别通过Clip不同编码器处理然后组合。而后输入到DF的Attention计算当中,对于特征组合部分代码处理方式为:
text_object_embed = self.fuse_fn(object_embeds)#两层mlp+norm
text_embeds_new = text_embeds.clone()
text_embeds_new[:, fuse_index, :] = text_object_embed.squeeze(1)
将得到的text_object_embed作为文本特征编码特征输入到unet中进行计算。除此之外论文中添加了一个mask loss计算。
除此之外使用Attention-Guided Fusion具体代码处理方式为:
def unet_store_cross_attention_scores(self, unet, attention_scores):
from diffusers.models.attention_processor import (
Attention,
AttnProcessor,
AttnProcessor2_0,
)
import types
UNET_LAYER_NAMES = [
"down_blocks.0",
"down_blocks.1",
"down_blocks.2",
"mid_block",
"up_blocks.1",
"up_blocks.2",
"up_blocks.3",
]
start_layer = 0
end_layer = 2
applicable_layers = UNET_LAYER_NAMES[start_layer:end_layer]
def make_new_get_attention_scores_fn(name):
def new_get_attention_scores(module, query, key, attention_mask=None):
attention_probs = module.old_get_attention_scores(
query, key, attention_mask
)
attention_scores[name] = attention_probs
return attention_probs
return new_get_attention_scores
for name, module in unet.named_modules():
if isinstance(module, Attention) and "attn2" in name:
if not any(layer in name for layer in applicable_layers):
continue
if isinstance(module.processor, AttnProcessor2_0):
module.set_processor(AttnProcessor())
module.old_get_attention_scores = module.get_attention_scores
module.new_get_attention_scores = types.MethodType(
make_new_get_attention_scores_fn(name), module
)
module.get_attention_scores = module.new_get_attention_scores
return unet
....
fuse_index = 5
if self.config.apply_attention_guided_fusion:
if i == len(timesteps) - 1:
attn_key, attn_map = next(iter(self.cross_attention_scores.items()))
attn_map = self.resize_attn_map_divide2(attn_map, mask, fuse_index)
init_latents_proper = image_latents
if self.do_classifier_free_guidance:
_, init_mask = attn_map.chunk(2)
else:
init_mask = attn_map
attn_map = init_mask
self.clear_cross_attention_scores(self.cross_attention_scores)
...
attn_pils = []
if output_type == "pil" and attn_map is not None:
for i in range(len(attn_map)):
attn_np = attn_map[i].mean(dim=0).cpu().numpy() * 255.
attn_pil = PIL.Image.fromarray(attn_np.astype(np.uint8)).convert("L")
attn_pils.append(attn_pil)
original_pils = self.image_processor.postprocess(init_image, output_type="pil")
generated_pils = image
fused_images = []
for i in range(len(generated_pils)):
ori_pil = original_pils[i]
gen_pil = generated_pils[i]
attn_pil = attn_pils[i]
fused_np = attention_guided_fusion(np.array(ori_pil), np.array(gen_pil), np.array(attn_pil))
fused_pil = PIL.Image.fromarray(fused_np.astype(np.uint8)).resize(ori_pil.size)
fused_images.append(fused_pil)
image = fused_images
首先对于unet_store_cross_attention_scores主要是处理如下两个步骤:1、搜集down_blocks.0和down_blocks.1中attn2模块的注意力分数;2、将down_blocks.0和down_blocks.1中attn2模块处理器从AttnProcessor2_0替换为AttnProcessor
而后在attention_guided_fusion设计中直接将三部分结果:1、原图 image;2、生成得到结果:generated_pils;3、将注意力得分转化为图像:attn_pil进行融合
总结
总得来说两个论文中都是通过构建数据集去训练模型,对与他们的数据集构建:Rorem中是直接通过“循环”方式去获得高质量数据(首先人工筛选高质量的消除数据集)然后去训练SDXL模型然后会有一个判别判断消除效果如何对于效果好的数据直接加到数据中再去训练模型循环上面过程,而再Object中的处理思路为切割实体然后再去将实体去贴到背景中。