Stable Diffusion WebUI 基础使用
SD WebUI 安装使用
SD WebUI官方地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui里面关于安装的介绍不多,这里直接介绍在Linux上直接安装并且基础使用。
首先、克隆仓库到本地
# 直接从Github
git clone git@github.com:AUTOMATIC1111/stable-diffusion-webui.git
# 直接从 Gitee(f非官方)
git clone git@gitee.com:smallvillage/stable-diffusion-webui.git
在clone得到文件之后对Stable Diffusion WebUI文件夹基本介绍如下1:
1、文本到图像的目录 (outputs/txt2img-images): 存储从文本描述生成的图像。这类目录通常用于保存用户输入文本提示后,系统生成的图像。
2、图像到图像的目录 (outputs/img2img-images): 存储基于现有图像进行修改或再创作后生成的新图像。这是用于图像编辑或风格迁移任务的输出位置。
3、附加或实验性质的输出目录 (outputs/extras-images): 可能用于存储实验性或不符合主要类别的其他图像生成结果。
4、文本到图像网格的目录 (outputs/txt2img-grids): 存储以网格形式展示的多个文本到图像的生成结果,这对于一次性查看和比较多个图像特别有用。
5、图像到图像网格的目录 (outputs/img2img-grids): 存储以网格形式展示的多个图像到图像的生成结果,同样便于比较和展示。
6、图像生成日志目录 (log/images): 存储与图像生成过程相关的日志信息,这对于调试和分析生成过程非常重要。
7、初始化图像的目录 (outputs/init-images): 用于保存在图像到图像转换过程中使用的初始图像或源图像。
根目录.launcher:可能包含与项目启动器相关的配置文件。__pycache__:存储 Python 编译过的字节码文件,以加快加载时间。config_states:可能用于存储项目配置的状态或历史版本。configs:用于存放配置文件,通常包含项目运行所需的参数设置。 detected_maps:可能存储自动生成的映射或检测结果。embeddings:可能包含用于机器学习的嵌入向量数据。extensions 和 ` extensions_builtin :存储项目的扩展或插件。 git:通常是 Git 版本控制的相关目录。 html、 javascript :存储网页前端相关的 HTML 文件和 JavaScript 脚本。 launcher:可能包含启动项目的脚本或可执行文件。 localizations:包含项目的本地化文件,如翻译或语言资源。 log:存储日志文件,记录项目运行时的活动或错误信息。 models:通常用于存储机器学习模型或项目中使用的数据模型。 modules:包含项目的代码模块或组件。 outputs:存储项目运行产生的输出文件,如生成的图像或报告。 py310:可能指 Python 3.10 版本的特定文件或环境。 repositories:可能用于存储与代码仓库相关的数据。 scripts:包含用于项目构建、部署或其他自动化任务的脚本。 tags:可能用于版本标记或注释。 test:存储测试代码和测试数据。 textual_inversion:可能是一个特定的功能模块,用于文本相关的处理或转换。 textual_inversion_templates:存储文本逆向工程或模板化处理的文件 tmp:临时文件夹,用于存储临时数据或运行时产生的临时文件。 得到内容之后直接去修改stable-diffusion-webui/modules/patches.py`里面的
# data_path = cmd_opts_pre.data_dir
# models_path = cmd_opts_pre.models_dir if cmd_opts_pre.models_dir else os.path.join(data_path, "models")
data_path = '/root/autodl-tmp/SDWebUIFile/data'
models_path = '/root/autodl-tmp/SDWebUIFile/models'
去避免文件直接都下载到本地环境,除此之外在webui.sh里面直接去第一行添加venv_dir="/root/autodl-tmp/SDWebUIFile/venv"(避免虚拟环境直接装在本地)准备工作做完之后就可以直接运行sh文件
cd stable-diffusion-webui/
# source /etc/network_turbo 如果使用 autodl 服务器
bash webui.sh -f # 加 -f 这个参数如果你是 root 用户使用这个参数避免
添加
-f是因为他不支持ERROR: This script must not be launched as root, aborting...
安装完毕之后基本就可以直接访问本地地址http://127.0.0.1:7860/然后进行生成图片了。
SD WebUI 其他模型安装
执行上面操作之后 SD WebUI会默认安装一个模型,不过这个模型效果不是很好,那就需要去安装其他模型,具体操作如下:比如说我需要安装这两个模型:dreamshaperXL_sfwV2TurboDPMSDE.safetensors和 sdxl_vae.safetensors那么只需要去huggingface上去找到指定权重然后下载(可以直接将huggingface改为国内镜像地址,但是autodl可以直接 source /etc/network_turbo可以加速Github和Huggingface)即可:
建议直接使用镜像进行下载具体操作:huggingface镜像然后看方法三即可
./hfd.sh lllyasviel/ControlNet-v1-1 --include control_v11e_sd15_ip2p.pth control_v11e_sd15_ip2p.yaml --local-dir /root/autodl-tmp/SDWebUIFile/models/ControlNet
值得注意的是上面代码如果 include 是一个文件夹那么会直接带着文件夹一起下载,比如说./hfd.sh lllyasviel/ControlNet --include annotator/ckpts/dpt_hybrid-midas-501f0c75.pt --local-dir /root/autodl-tmp/SDWebUIFile/data/extensions/sd-webui-controlnet/annotator/downloads/midas/
可能就需要去移动到指定目录:mv /root/autodl-tmp/SDWebUIFile/data/extensions/sd-webui-controlnet/annotator/downloads/midas/annotator/ckpts/dpt_hybrid-midas-501f0c75.pt /root/autodl-tmp/SDWebUIFile/data/extensions/sd-webui-controlnet/annotator/downloads/midas/
# 安装 huggingface-cli
pip install -U huggingface_hub
# 登录 下面操作可能因为 huggingface_hub版本不一致不用 可能直接使用 hug_cli 而不是 hf
hf auth login
# 下载所有权重
hf download Madespace/Checkpoint --local-dir ~/autodl-tmp/SDWebUIFile/models/Stable-diffusion/
# 下载部分权重
hf download Madespace/Checkpoint dreamshaperXL_sfwV2TurboDPMSDE.safetensors --local-dir ~/autodl-tmp/SDWebUIFile/models/Stable-diffusion/
hf download stabilityai/sdxl-vae sdxl_vae.safetensors --local-dir ~/autodl-tmp/SDWebUIFile/models/Stable-diffusion/
执行上面处理就可以在SD WebUI里面看到自己下载的权重了
SD WebUI 插件安装使用
对于SD WebUI插件主要介绍两种:1、汉化插件;2、ControlNext插件
安装汉化插件
项目地址:https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans
操作步骤:第一步:安装插件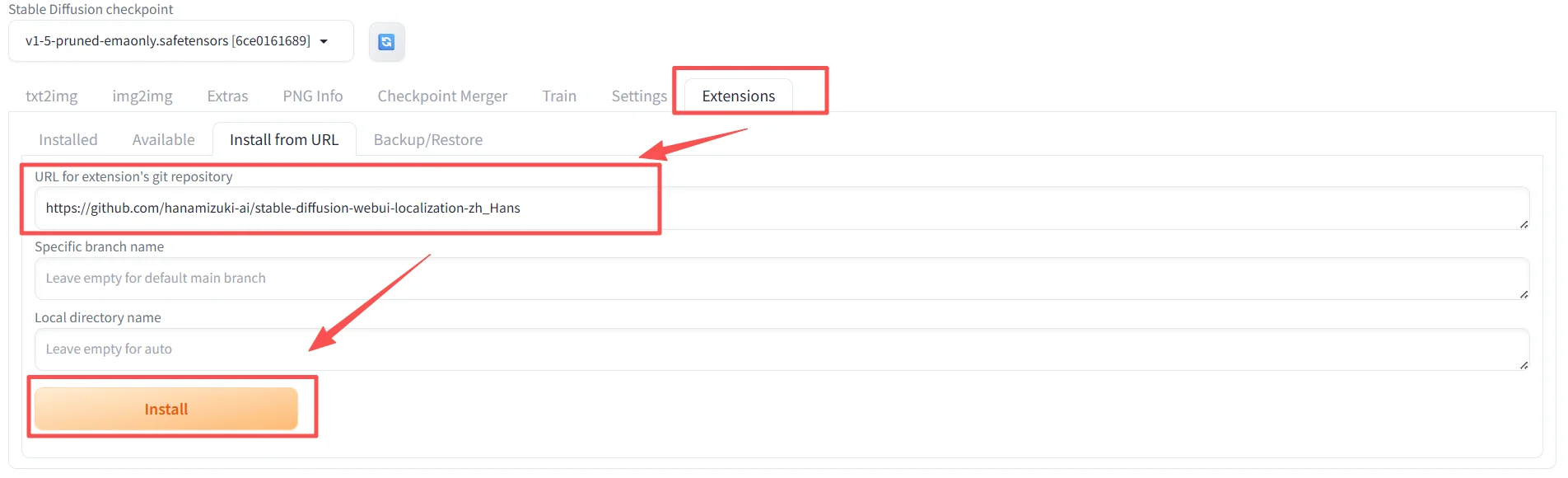
当下面出现:AssertionError: Extension directory already exists: /root/autodl-tmp/SDWebUIFile/data/extensions/stable-diffusion-webui-localization-zh_Hans时候就代表安装完毕,然后就可以直接去进行下面步骤
第二步:启用插件
然后就可以正常安装了,然后就需要去seeting–>User interface,然后在这个界面选择中文即可(一定要先点击Apply)
最后Reload UI即可,这样界面就变成中文了。
ControlNet 插件安装
基本安装步骤和上面的一样,只是不需要进行第二步:启用插件了。安装ControNet插件之后就只需要去安装对应的模型权重即可使用插件。如果按照上面步骤修改了地址那么:
(base) root@xxxx:~/autodl-tmp/SDWebUIFile/models# ls
Codeformer ControlNet GFPGAN Lora Stable-diffusion hypernetworks
然后对于ControlNet权重就可以直接下载然后放到ControlNet中即可,比如说下载
就只需要:
hf download lllyasviel/sd_control_collection diffusers_xl_canny_full.safetensors --local-dir /root/autodl-tmp/SDWebUIFile/models/ControlNet
hf download lllyasviel/sd_control_collection diffusers_xl_depth_full.safetensors --local-dir /root/autodl-tmp/SDWebUIFile/models/ControlNet
具体使用可以见:https://zhuanlan.zhihu.com/p/692537570
SD WebUI API调用
执行完毕上面操作之后既可以直接调用API进行处理了(bash webui.sh -f --api启用API访问)然后可以直接使用 requests方式进行访问,具体例子比如说:用上面下面的control_v11e_sd15_ip2p.pth和 control_v11f1p_sd15_depth.pth进行测试实验,具体代码:code,值得注意的是:
最终得到效果如下
ComfyUI 基础使用
教程:https://www.bilibili.com/video/BV14w41167eZ/?vd_source=881c4826193cfb648b5cdd0bad9f19f0对于ComfyUI只需要了解如下几个点:1、如何API调用;2、如何自定义节点;3、工作流搭建(这个直接多看几个别人的就会了)
对于ComfyUI不需要看太多视频,简单总结使用就是:在ComfyUI中所有的运行过程都是在 工作流 上进行运行,而工作流中每一个“方框”就是我们的 节点(可以意见为一个函数有与输入和输出),不同节点之间输入接输出。
ComfyUI 自定义节点
自定义节点之前,先了解安装节点,直接进入ComfyUI里面的节点目录/root/autodl-tmp/ComfyUI/custom_nodes,然后找到你需要安装的节点 clone到这个文件夹里面,然后安装依赖,就可以完成一个节点的安装了,推荐安装节点:ComfyUI-LG_HotReload避免每次更新节点都需要去重启服务。自定义节点过程2。这里直接给出一个比较简洁的模板去自定义节点,首先在ComfyUI/custom_nodes文件中创建一个节点名称(名字任取)文件夹,而后再去创建一个__init__.py文件,以及你的节点功能文件,比如说sam_node.py,对于这两个文件,前者主要是用来将你的节点暴露给comfyui让他可以找到你的节点,后者则是你的节点的功能实现。比如说我要做一个onefromer+sam去图像分割的节点那么就可以按照下面过程进行。
首先,明确我的函数需要的输入和返回。对于图像分割那么输入就是原始图像,而输出一般就是mask图像。那么对于sam_node.py就可以这么定义:
class OneformerSAMNode:
def __init__(self):
....
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"image": ("IMAGE",),
"oneformer_model": (["oneformer_large", "oneformer_tiny"], {"default": "oneformer_large"}),
"sam_model": (["vit_b", "vit_l"], {"default": "vit_l"}),
"processor_resolution": ("INT", {"default": 512, "min": 256, "max": 1024, "step": 64}),
}
}
RETURN_TYPES = ("IMAGE", "MASK", "BOOLEAN")
RETURN_NAMES = ("mask_image", "mask", "is_empty")
FUNCTION = "detect"
CATEGORY = "image/empty_detect"
def detect(self, image, oneformer_model, sam_model, processor_resolution):
...
return (mask_image, mask, is_empty)
对于上述函数,INPUT_TYPES里面定义了节点的输入,RETURN_TYPES定义了节点的输出,FUNCTION定义了节点的功能,CATEGORY定义了节点的分类。
而后,在定义函数之后就只需要让comfyui去找到这个节点,那么就需要在__init__.py文件中进行如下定义:
from .comfyui_node import NODE_CLASS_MAPPINGS as EMPTY_DETECT_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS as EMPTY_DETECT_DISPLAY
# 合并所有节点映射
NODE_CLASS_MAPPINGS = {}
NODE_CLASS_MAPPINGS.update(EMPTY_DETECT_MAPPINGS)
NODE_DISPLAY_NAME_MAPPINGS = {}
NODE_DISPLAY_NAME_MAPPINGS.update(EMPTY_DETECT_DISPLAY)
# ComfyUI 会自动导入这些映射
__all__ = ['NODE_CLASS_MAPPINGS', 'NODE_DISPLAY_NAME_MAPPINGS']