DPO、PPO、GRPO代码乱记
DPOTrainer
数据处理
在使用DPOTrainer第一步就是准备数据集,对于数据集准备过程为,收集3元组数据集:
一般而言构建的具体的数据格式如下:
[
{
"role": "system",
"content": [{xxxxx}],
},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
},
{
"type": "text",
"text": (xxxxxx)
},
],
},
]
在得到数据集之后,在DPOTrainer内部会直接通过_prepare_dataset函数通过输入的tokenizer进行编码处理,得到主要内容为:'prompt', 'prompt_input_ids', 'chosen_input_ids', 'rejected_input_ids'。其中prompt主要就是上面数据格式中的 user的content-text内容。而chosen和rejected则是分别对应system的内容。通过tokenizer将所有的文本进行编码处理,接下来就是模型训练过程。
模型训练
在DPOTrainer训练中主要是继承Trainer类,因此对于DPOTrainer核心需要关注的点就是loss计算过程,在代码中主要是通过函数get_batch_loss_metrics来计算loss具体值
def get_batch_loss_metrics(
self,
model: PreTrainedModel | nn.Module,
batch: dict[str, list | torch.LongTensor],
train_eval: Literal["train", "eval"] = "train",
) -> tuple[torch.Tensor, dict[str, float]]:
metrics = {}
if self.args.use_liger_kernel:
model_output = self._compute_loss_liger(model, batch)
losses = model_output["loss"]
chosen_rewards = model_output["chosen_rewards"]
rejected_rewards = model_output["rejected_rewards"]
else:
model_output = self.concatenated_forward(model, batch)
# if ref_chosen_logps and ref_rejected_logps in batch use them, otherwise use the reference model
if "ref_chosen_logps" in batch and "ref_rejected_logps" in batch:
ref_chosen_logps = batch["ref_chosen_logps"]
ref_rejected_logps = batch["ref_rejected_logps"]
else:
ref_chosen_logps, ref_rejected_logps = self.compute_ref_log_probs(batch)
# Initialize combined losses
losses = 0
chosen_rewards = 0
rejected_rewards = 0
# Compute losses for each loss type
for idx, loss_type in enumerate(self.loss_type):
# Compute individual loss using standard DPO loss function
_losses, _chosen_rewards, _rejected_rewards = self.dpo_loss(
model_output["chosen_logps"],
model_output["rejected_logps"],
ref_chosen_logps,
ref_rejected_logps,
loss_type,
model_output,
)
# Add weighted contributions
weight = self.loss_weights[idx] if self.loss_weights else 1.0
losses = losses + _losses * weight
chosen_rewards = chosen_rewards + _chosen_rewards * weight
rejected_rewards = rejected_rewards + _rejected_rewards * weight
reward_accuracies = (chosen_rewards > rejected_rewards).float()
if self.args.rpo_alpha is not None:
losses = losses + self.args.rpo_alpha * model_output["nll_loss"] # RPO loss from V3 of the paper
if self.use_weighting:
losses = losses * model_output["policy_weights"]
if self.aux_loss_enabled:
losses = losses + self.aux_loss_coef * model_output["aux_loss"]
...
return losses.mean(), metrics
省略掉所有的处理过程直接看模型分别得到什么样的结果,首先在self.concatenated_forward中主要就是将数据丢到model中outputs = model(input_ids, **model_kwargs) logits = outputs.logits得到处理的每一个token的概率而后通过logits = logits[:, -seq_len:]来截取模型回答的token概率,因此最后返回:model_output,最后得到的model_output主要是由如下组成(不过最后的chosen logps等都是整个句子的mean值)
...
outputs = model(input_ids, **model_kwargs)
logits = outputs.logits # [dim_1, dim_2, dim_3]
logits = logits[:, -seq_len:] # [dim_1, dim_2, dim_4]
...
all_logps = per_token_logps[:, 1:].sum(-1) # 其中per_token_logps直接通过计算 log softmax计算得到token概率值
...
output = {
'chosen_logps': log_probs[:B, L_p:L_p+L_c].mean(dim=-1),
'rejected_logps': log_probs[B:, L_p:L_p+L_r].mean(dim=-1),
'mean_chosen_logits': logits[:B, L_p:L_p+L_c, :].mean(),
'mean_rejected_logits': logits[B:, L_p:L_p+L_r, :].mean(),
} # 上面 4个都是具体的数值,其中 chosen_logps > rejected_logps 代表 DPO 正在学习!
而后就是具体计算loss过程self.dpo_loss(这部分代码比较简单)
模型结果
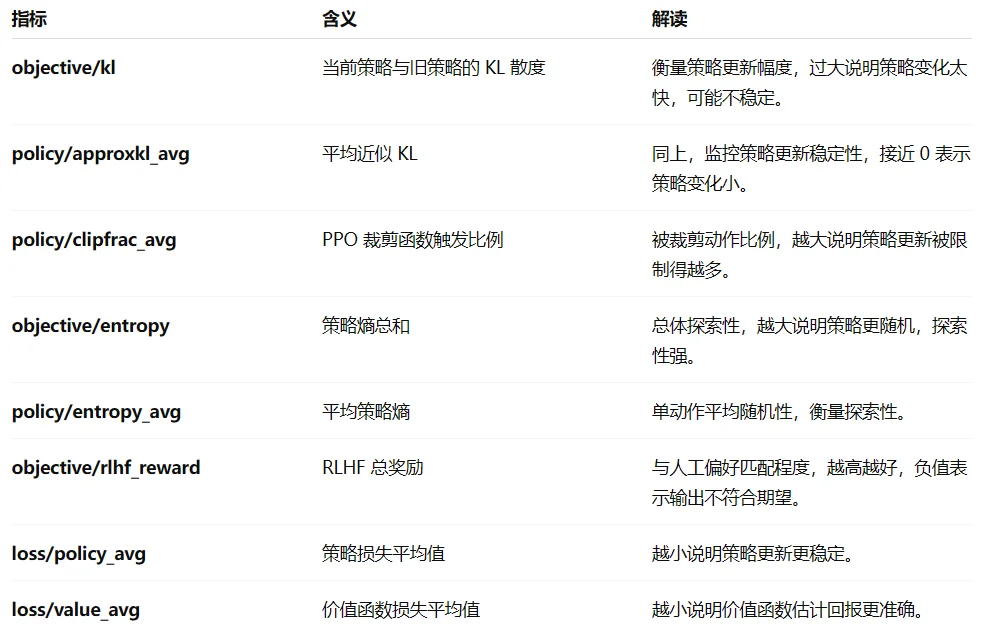
模型训练过程中通过report_to参数确定记录训练过程,在DPOTrainer中主要是如下几个结果值需要关注:1、奖励信号:rewards/chosen、rewards/rejected,rewards/margins;2、准确性:rewards/accuracies(模型是否正确偏好 chosen);3、对数概率:logps/chosen,logps/rejected(policy 模型对响应的打分);4、其他指标,如grad_norm(训练稳定性定量评估)
GRPOTrainer
数据处理
在GRPOTrainer中对于数据处理过程会直接通过_prepare_inputs,_generate_and_score_completions来准备模型所需要的输入,其中模型主要得到的输入(这部分其实就和普通的SFT过程是相同的将数据通过tokenizer进行处理)为比如说最基本的几个值:
output = {
"prompt_ids": prompt_ids, # torch.Size([8, 256])
"prompt_mask": prompt_mask, # torch.Size([8, 256])
"completion_ids": completion_ids, # torch.Size([8, 68])
"completion_mask": completion_mask, # torch.Size([8, 68])
"advantages": advantages, # torch.Size([8])
"num_items_in_batch": num_items_in_batch,
"ref_per_token_logps": ref_per_token_logps # torch.Size([8, 68])
}
# 对于多模态数据 就会多几个参数如 pixel_values等
其中对于output中各个部分代表含义:prompt_ 主要指的是prompt内容,completion_ 主要指的是模型的回答内容(值得注意的是这两项还都是我的数据中内容而非模型生成内容)。除此之外还有两个值得关注的结果:1、old_per_token_logps:主要通过 model生成(这个model主要是”旧的没有更新“的模型);2、ref_per_token_logps(beta!=0)主要通过 ref_model生成。之所以需要计算这两个值 为了计算KL值。
都是直接通过
self._get_per_token_logps_and_entropies计算得到
除此之外需要关注的是advantages的计算过程:
# 首先、计算reward值
rewards_per_func = self._calculate_rewards(inputs, prompts, completions,completion_ids_list)
rewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).nansum(dim=1) # 如果有多个 rewards 计算函数 那么通过使用 self.reward_weights 去平衡 不同计算函数
# 而后计算 (r- mean)/std
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = rewards - mean_grouped_rewards # r- mean
...
elif self.scale_rewards == "batch":
std_rewards = rewards.std().expand_as(rewards)
advantages = advantages / (std_rewards + 1e-4)
模型训练
在GRPOTrainer中计算loss过程为:
def _compute_loss(self, model, inputs):
prompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"]
completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"]
input_ids = torch.cat([prompt_ids, completion_ids], dim=1)
attention_mask = torch.cat([prompt_mask, completion_mask], dim=1)
logits_to_keep = completion_ids.size(1) # we only need to compute the logits for the completion tokens
# 计算模型输出结果 logits = model(**model_inputs).logits logps = selective_log_softmax(logits, completion_ids)
per_token_logps, entropies = self._get_per_token_logps_and_entropies(model,input_ids,attention_mask,logits_to_keep,.....)
...
# 计算KL散度值
if self.beta != 0.0:
ref_per_token_logps = inputs["ref_per_token_logps"]
per_token_kl = (
torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
)
# Compute the loss
advantages = inputs["advantages"]
old_per_token_logps = inputs.get("old_per_token_logps")
old_per_token_logps = per_token_logps.detach() if old_per_token_logps is None else old_per_token_logps
log_ratio = per_token_logps - old_per_token_logps
if self.importance_sampling_level == "token":
log_importance_weights = log_ratio
elif self.importance_sampling_level == "sequence":
log_importance_weights = (log_ratio * completion_mask).sum(-1) / completion_mask.sum(-1).clamp(min=1.0)
log_importance_weights = log_importance_weights.unsqueeze(-1)
# From here, log_importance_weights (and all subsequent tensors, coef_1, coef_2, etc.) shape depends on
# importance_sampling_level: "token" level: (B, T); "sequence" level: (B, 1)
coef_1 = torch.exp(log_importance_weights)
coef_2 = torch.clamp(coef_1, 1 - self.epsilon_low, 1 + self.epsilon_high)
# Two-sided clipping
if self.args.delta is not None:
coef_1 = torch.clamp(coef_1, max=self.args.delta)
per_token_loss1 = coef_1 * advantages.unsqueeze(1)
per_token_loss2 = coef_2 * advantages.unsqueeze(1)
per_token_loss = -torch.min(per_token_loss1, per_token_loss2)
if entropy_mask is not None:
per_token_loss = per_token_loss * entropy_mask
if self.use_vllm and self.vllm_importance_sampling_correction:
per_token_loss = per_token_loss * inputs["importance_sampling_ratio"]
if self.beta != 0.0:
per_token_loss = per_token_loss + self.beta * per_token_kl
if self.loss_type == "grpo":
loss = ((per_token_loss * completion_mask).sum(-1) / completion_mask.sum(-1).clamp(min=1.0)).mean()
loss = loss / self.current_gradient_accumulation_steps
...
# 记录计算过程结果
...
return loss
在计算loss过程中需要再次使用 self._get_per_token_logps_and_entropies(在数据处理过程中会分别使用 model、ref_model都进行计算)不过这里使用model是”最新的需要更新“的模型。
模型结果
参考GPT对于输出结果的解释

PPOTrainer
使用PPOTrainer中坑很多:1、对于reward model就必须要有 score 但是对于Qwen0.5B测试过程中他是没有的因此需要封装一个
数据处理
模型训练
在了解PPOTrainer之前需要知道的是,对于输入到PPOTrainer的模型主要是如下3个:1、model;2、ref_model;3、reward_model。其中对于后面两个模型都必须有 socre属性(TODO:这个后续继续补充!)
对于PPOTrainer训练过程代码(在trl中封装不是很多)直接看他的train部分代码即可:
def train(self):
...
model = self.model
ref_policy = self.ref_model
reward_model = self.reward_model
processing_class = self.processing_class
dataloader = self.dataloader
...
generation_config = GenerationConfig(...)
...
# 记录训练过程的值
stats_shape = (args.num_ppo_epochs, args.num_mini_batches, args.gradient_accumulation_steps) # 换言之 epoch, batch, gradient_accumulation_steps
vf_loss_stats = torch.zeros(stats_shape, device=device)
...
for update in range(1, args.num_total_batches + 1): # math.ceil(int(args.num_train_epochs * self.train_dataset_len) / args.batch_size)
...
#⭐1、记录一个batch数据的 奖励和优势
with torch.no_grad():
queries = data["input_ids"].to(device) # [batch_size* gradient_accumulation_steps, max_tokens]
query_responses, logitss = batch_generation(unwrapped_model.policy,queries,...)
for i in range(0, queries.shape[0], args.local_rollout_forward_batch_size):# local_rollout_forward_batch_size 代表一次多少的 promt 输入
# 1.1 首先是去截取输出
# 首先是最开始的policy模型的输出
query = queries[i : i + args.local_rollout_forward_batch_size]
query_response = query_responses[i : i + args.local_rollout_forward_batch_size]
response = query_response[:, context_length:] # 截取出只需要的模型回答
logits = logitss[i : i + args.local_rollout_forward_batch_size]
logprob = selective_log_softmax(logits, response) # 计算每个 token 的概率值
# refmodel输出
...
else:
ref_output = forward(ref_policy, query_response, ...)
ref_logits = ref_output.logits[:, context_length - 1 : -1]
ref_logits /= args.temperature + 1e-7
ref_logprob = selective_log_softmax(ref_logits, response)
...
# 1.2 拼接内容 而后去计算 reward 值
postprocessed_query_response = torch.cat((query, postprocessed_response), 1)
...
full_value, _, _ = get_reward(unwrapped_value_model, query_response, processing_class.pad_token_id, context_length)
value = full_value[:, context_length - 1 : -1].squeeze(-1)
_, score, _ = get_reward(reward_model, postprocessed_query_response, processing_class.pad_token_id, context_length)
...
# 1.3、计算KL、rewards等值
logr = ref_logprobs - logprobs
kl = -logr
non_score_reward = -args.kl_coef * kl
rewards = non_score_reward.clone()
actual_start = torch.arange(rewards.size(0), device=rewards.device)
actual_end = torch.where(sequence_lengths_p1 < rewards.size(1), sequence_lengths_p1, sequence_lengths)
rewards[actual_start, actual_end] += scores
# 1.4、计算优势值
...
#⭐2、模型训练优化
for ppo_epoch_idx in range(args.num_ppo_epochs):
...
for mini_batch_start in range(0, args.local_batch_size, args.local_mini_batch_size):
...
for micro_batch_start in range(0, args.local_mini_batch_size, args.per_device_train_batch_size):
#2.1 分别去从第一步中得到的 query_responses、responses、advantages等拿出小批次的数据也就是 micro_batch
对于PPOTrainer训练过程分解出来就是如下几个比较核心的环节:
1、记录一个batch数据的 奖励和优势。这个过程中主要是分为如下几个步骤,首先是去截取输出、这一步主要是需要ref_logprob、logprob、query_response,拼接内容 而后去计算 reward 值,计算优势值。
总结为:问题(
query)丢到model中得到logprobs以及模型的回答query_response,同样将模型回答query_response丢到ref_model中得到ref_logprobs这样一来直接计算KL散度值:-(ref_logprobs - logprobs)。除此之外将query和query_response进行组合然后由reward_model去计算得到reward值,而对于优势值,直接通过GAE,通过一个带衰减的公式平滑计算
2、模型训练优化
模型结果
参考GPT对于输出结果的解释