前面已经介绍了简单的视觉编码器,这里主要介绍常用的目标检测算法
1、CV中常用Backbone-2:ConvNeXt模型详解
2、CV中常用Backbone(Resnet/Unet/Vit系列/多模态系列等)以及代码
3、CV中常用Backbone-3:Clip/SAM原理以及代码操作
目标检测算法
基于卷积的目标检测算法如:R-CNN、FastRCNN、Yolo(部分版本)等,基于Attention如Vit等
R-CNN目标检测
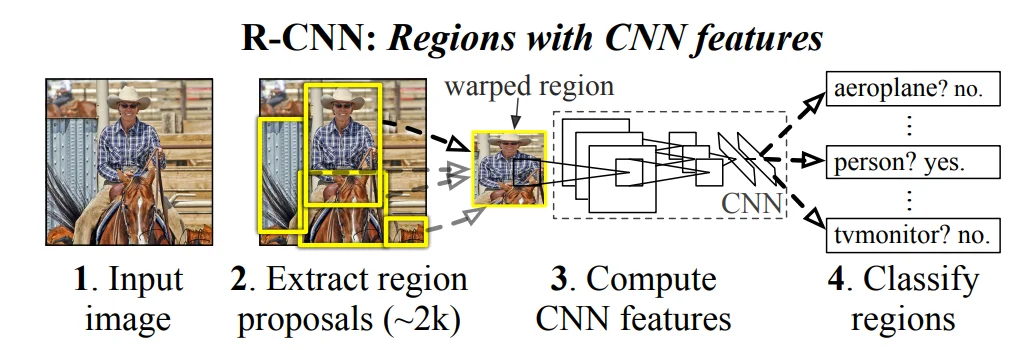
算法原理1如上面所述,主要过程为:1、区域候选框生成器(Region Proposal Extractor);2、CNN特征提取器;3、SVM分类器根据特征进行分类;4、回归模型用于收紧边界框。其中主要需要着重介绍的 区域候选款生成器用像 Selective Search 这样的传统方法从输入图像产生大约 1–2k 个候选框(每个候选框可能包含一个物体或背景)。Selective Search 利用图像分割和层次合并产生高召回率的候选区域。
整体过程如上面描述一下,通过预训练的神经网络(AlexNet)等去获取CNN特征,然后再去通过选择性搜索算法(Selective Search)获取所有的可能的“目标”
对于选择性搜索算法的一个大致思路:大概的意思就是首先根据图像分割的算法来初始化划分区域,然后根据不同颜色模式、目标颜色、纹理、大小、形状等特征来计算相似度合并子区域。
在经过分类以及SVM分类之后直接再去收缩边界框,这个过程主要是通过非极大值抑制去剔除重叠的建议框。
非极大值抑制:对于每一个框都会有一个置信度,首选按照置信度进行排列得到最大的置信度框,然后去计算其他框和这个最大框的IoU,如果某个框与选取框的IoU大于我们设定的阈值(比如0.5),说明它们和选取框检测的是同一个目标,所以需要被抑制(删除)。如果某个框与选取框的IoU小于阈值,说明它们和框A检测的可能是另一个目标(或者只是重叠不多),予以保留。
$\text{IoU}=\frac{\text{Area}(A\cap B)}{\text{Area}(A\cup B)}$ 具体的代码实现如下
def bbox_iou(box1, box2):
inter_x1 = max(box1[0], box2[0])
inter_y1 = max(box1[1], box2[1])
inter_x2 = min(box1[2], box2[2])
inter_y2 = min(box1[3], box2[3])
# 交集的宽高(注意要 clamp 为 >=0)
inter_w = max(0, inter_x2 - inter_x1)
inter_h = max(0, inter_y2 - inter_y1)
inter_area = inter_w * inter_h
# 各自面积
area1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
# 并集面积
union_area = area1 + area2 - inter_area
# IoU
iou = inter_area / union_area if union_area > 0 else 0.0
return iou
Fast RCNN以及Faster RCNN目标检测
Fast RCNN2主要是依次解决上面模型存在的问题,其主要的原理如下: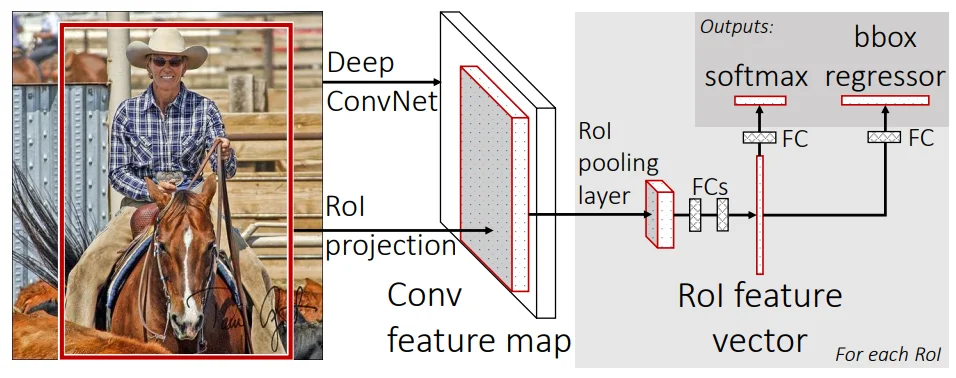
在Fast RCNN中主要过程:输入是一张图片和多个proposal,经过卷积层计算之后,通过ROI pooling的方式归一到一个fixed size的feature map,最后通过FCs计算分类损失(softmax probabilities)和框回归损失(b-box regression offsets)。这种方法的好处是一张图片只需要经过一次CNN的推理,不再像RCNN那样根据Proposals把原图切成多个子图输入到CNN中再去由SVM处理,大大提升了效率。
而在Faster CNN3主要是为了解决前者依赖于外部候选区域方法,而在该论文中主要提出改进措施是通过使用设计一个RPN去替换外部候选区域,整体流程如下: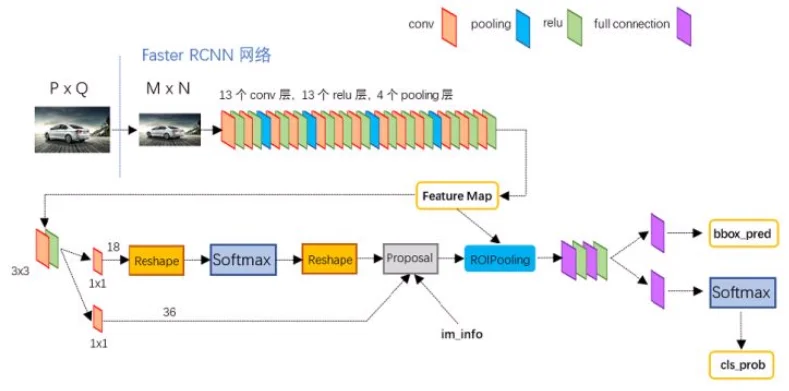
对于上面两个模型主要是需要关注两点:
1、RPN网络结构设计:在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。算法思路为:在得到特征图之后再特征图上每个像素点都预设9个anchor(基本就覆盖需要识别的目标),但是对于这些anchor肯定有很多多余的,因此再RPN中就有两个分支:1、分类分支(上面流程图中上面部分):直接通过(1, 1, 2k)(k=9)卷积去计算得到Objectness Score(标记框是目标还是背景);2、回归分支(上面流程图中下面部分):微调锚点框的位置和大小,使其更贴合真实目标。它不是直接预测坐标,而是预测偏移量(offsets)
2、RoI Pooling以及RoI Align4:两个RoI算法主要是将bbox映射到特征图上获取bbox中特征,后者是为了解决前者纯在的数据舍入问题。
YoLo算法
在Yolov1中其网络结构如下所示: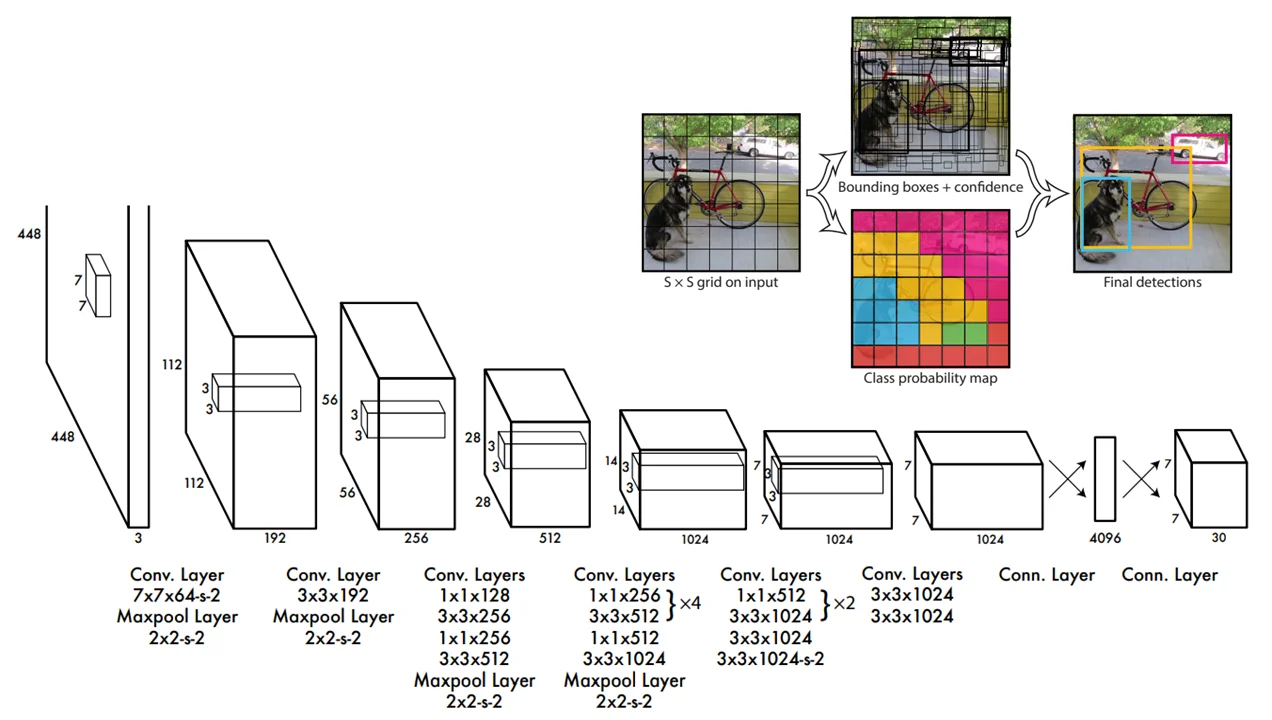
主要解决的是上面提到哪些检测算法需要用卷积核去“扫描”图像问题,在Yolo中直接将图像提前切割为 $S\times S$个格子而后就是按照上面的网络结构进行处理最后输出的张量为 $7\times 7\times 30$,可以理解为每一块都有30个特征值对于这30个特征值分别表示的含义是:$B\times 5+ C$ 其中B代表候选框数量(论文中选择2,具体的bbox坐标是直接通过模型训练得到),C代表类别,之所以用5表示的是 $(x,y,w,h,conf)$ 前面4个不解释后面一个指标代表的的是该框的 置信度水平,这样一来可以直接通过计算每个框属于哪个类别也就是计算执行都和类别C的乘积结果: $C\times \text{conf}$得到结果为 $20\times 1$这样一来每一个框都会这样计算那么最后得到 $7\times 7\times 2=98$,借鉴5中的PPT,那么我最后得到结果如下所述: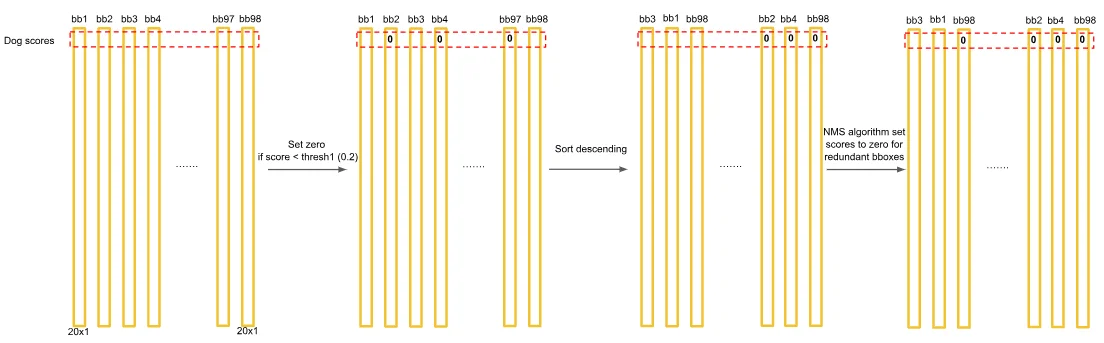
假设我的第一行是判断“狗”这个类别,那么第一行行都会有关于狗这个类别一个置信度,那么后续就可以直接去计算NMS来得到最后的bbox了。对于Yolo使用可以直接使用ultralytics来使用Yolo权重(Yolo11-SAM代码)