本文主要介绍几篇图像擦除论文模型:PixelHacker、PowerPanint、Attentive Eraser,并且实际测试模型的表现效果
PixelHacker
Code: https://github.com/hustvl/PixelHacker
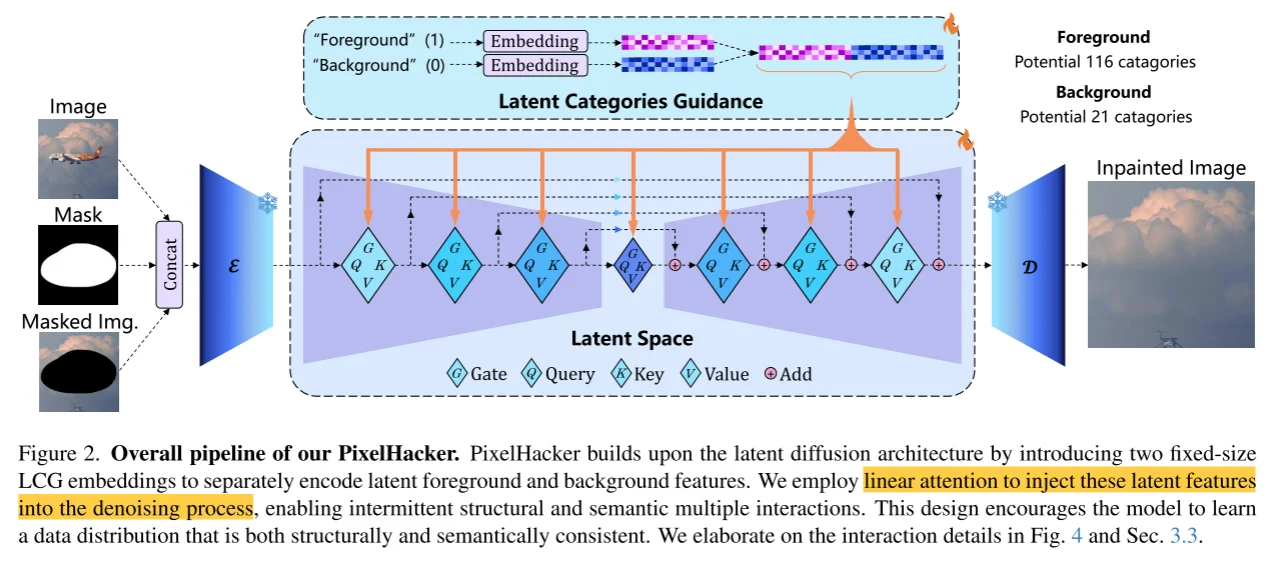
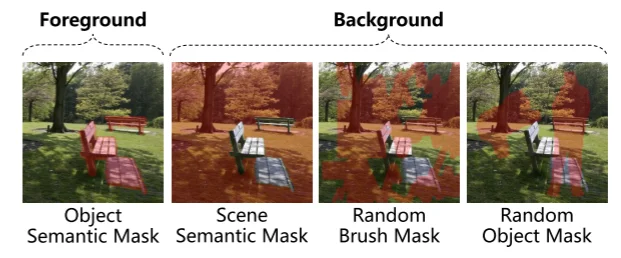
模型整体框架和Diffusion Model相似,输入分为3部分:1、image;2、mask;3、mask image而后将这三部分进行拼接,然后通过VAE进行encoder,除此之外类似Diffusion Model中处理,将condition替换为mask内容(这部分作者分为两类:1、foreground(116种类别);2、background(21种类别))作为condition(对于foreground直接通过编码处理,对于background的3部分通过:$M_{scene}+M_{rand}P_{rand}+M_{obj}P_{obj}$ 分别对于background的3部分)然后输入到注意力计算中。
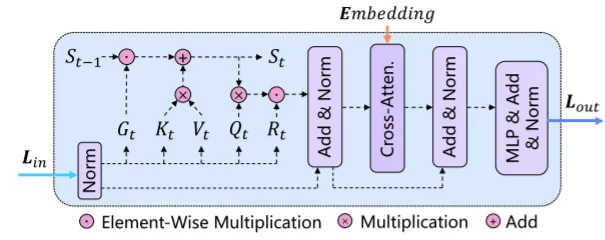
注意力计算过程,对于通过VAE编码后的内容$L_{in}$ 直接通过 $LW$ 计算得到QKV,并且通过 2D遗忘矩阵 $G_t$计算过程为:
\[G_t = \alpha_t^T \beta_t \in \mathbb{R}^{d_k \times d_v}, \alpha_t = \sigma(\text{Lin}_{\alpha} W_\alpha + b_\alpha)^{\frac{1}{2}} \in \mathbb{R}^{L \times d_k}, \beta_t = \sigma(\text{Lin}_{\beta} W_\beta + b_\beta)^{\frac{1}{2}} \in \mathbb{R}^{L \times d_v},\]$L_t$计算过程: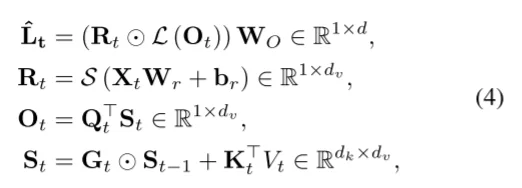
PixelHacker实际测试效果
| 图像 | mask | 结果 | 问题 |
|---|---|---|---|
 |  |  | 背景文字细节丢失 |
 |  |  | 人物细节 |
|  |  | 生成错误 |
分析:只能生成较低分辨率图像(512x512,Github),去除过程中对于复杂的图像可能导致细节(背景中的文字、图像任务)处理不好。
PowerPanint
A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting
From: https://github.com/open-mmlab/PowerPaint
Modle:SD v1.5、CLIP
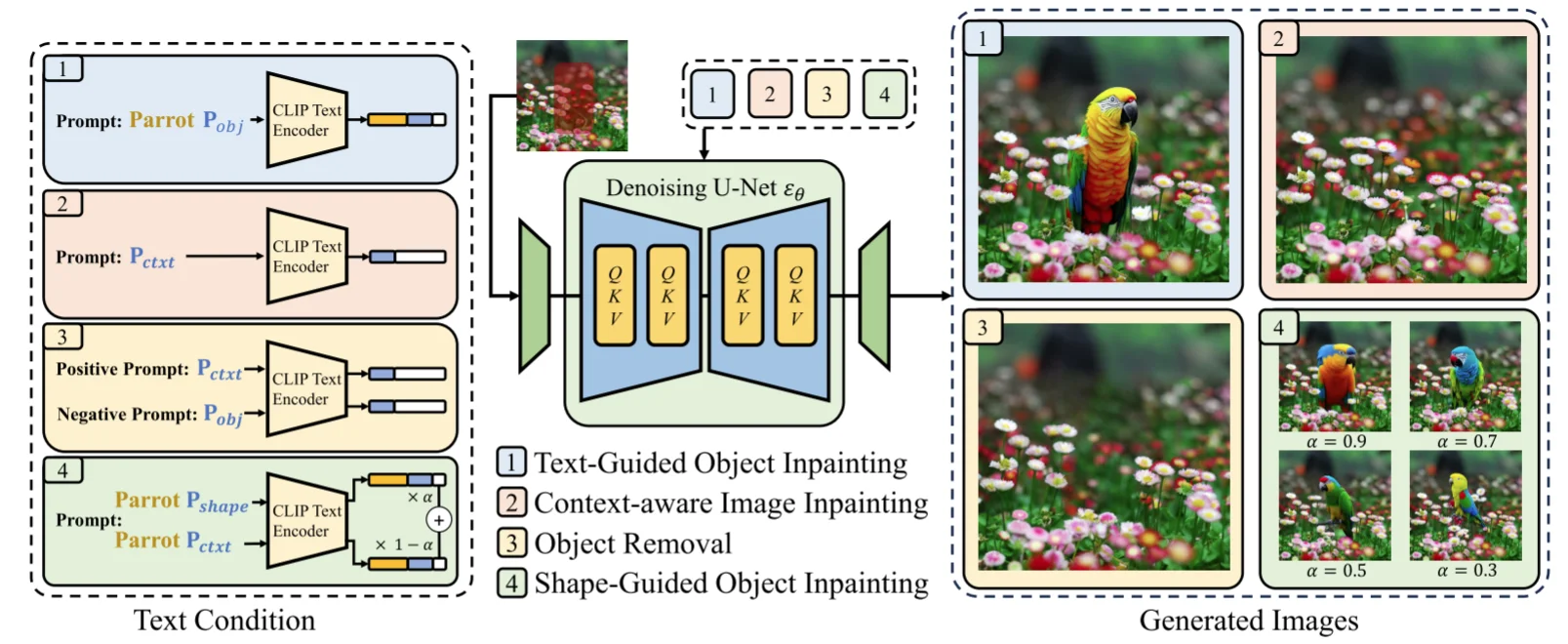
模型整体结构和DF模型相同,输入模型内容为:噪声的潜在分布、mask图像($x \bigodot (1-m)$)、mask;在论文中将condition替换为4部分组合(微调两部分:$P_{obj}$ 以及 $P_{ctxt}$):1、$P_{obj}$
1、增强上下文的模型感知:使用随机mask训练模型并对其进行优化以重建原始图像可获得最佳效果,通过使用$P_{ctxt}$(可学习的)让模型学会如何根据图像的上下文信息来填充缺失的部分,而不是依赖于文本描述,优化过程为: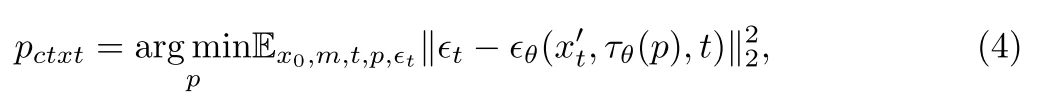
2、通过文本增强模型消除:通过使用$P_{obj}$:训练过程和上面公式相同,不过将识别得到的物体bbox作为图像mask并且将 $P_{obj}$作为mask区域的文本描述,引导模型根据给定的文本描述生成对应的对象。
第1和第2点区别在于,第二点输入有文本描述,而第一点就是可学习的文本
3、物品移除:使用移除过程中模型很容易进入一个“误解”:模型是新生成一个内容贴在需要消除的内容位置而不是消除内容(比如下面结果),作者的做法是直接将上面两个进行加权: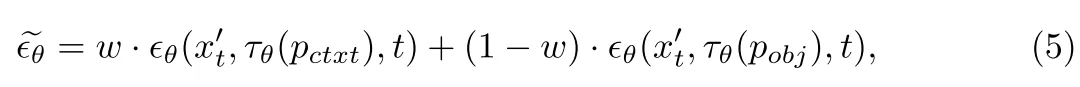
4、通过形状增强模型消除:$P_{shape}$:使用精确的对象分割mask和对象描述进行训练,不过这样会使得模型过拟合(输入文本和选定的区域,可能模型只考虑选定区域内容生成),因此替换做法是:直接对精确识别得到内容通过 膨胀操作让他没那么精确,具体处理操作为: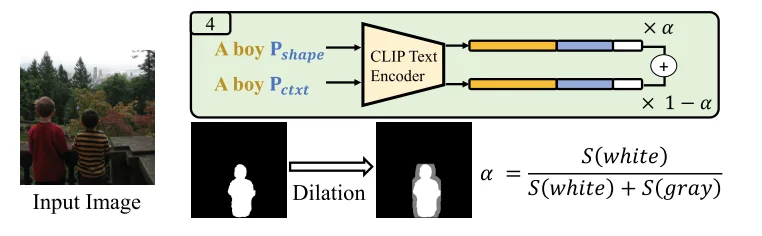
于此同时参考上面过程还是进行加权组合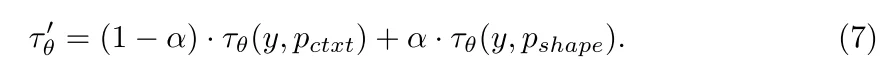
PowerPanint实际测试效果
只测试
Object removal inpainting,测试的权重:ppt-v1
| 图像 | mask | 结果 | 测试 |
|---|---|---|---|
 |  |  | 部分移除 |
|  |  | 全部移除 |
 |  |  | 复杂布局全部移除 |
|  |  | 复杂布局细小内容移除 |
|  |  | 多目标内容移除 |
 |  |  | 多目标内容移除 |
总的来说:PowerPanint还是比较优秀的消除模型,总体移除效果“说得过去”(如果不去追求消除的细节,见下面图像,比如说消除带来的图像被扭曲等)不过得到最后的图像的尺寸会被修改(in:2250x1500 out:960x640,此部分没有仔细去检查源代码是否可以取消或者自定义),除此之外,参考Github上提出的issue-1:图像 resize 了,修改了分辨率,VAE 对人脸的重建有损失,如果mask没有完全覆盖掉人,留了一些边缘,模型有bias容易重建生成出新的东西。issue-2:平均推理速度20s A100 GPU。
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
From: https://github.com/Nnn-s/CATdiffusion.
没有提供权重无法测试
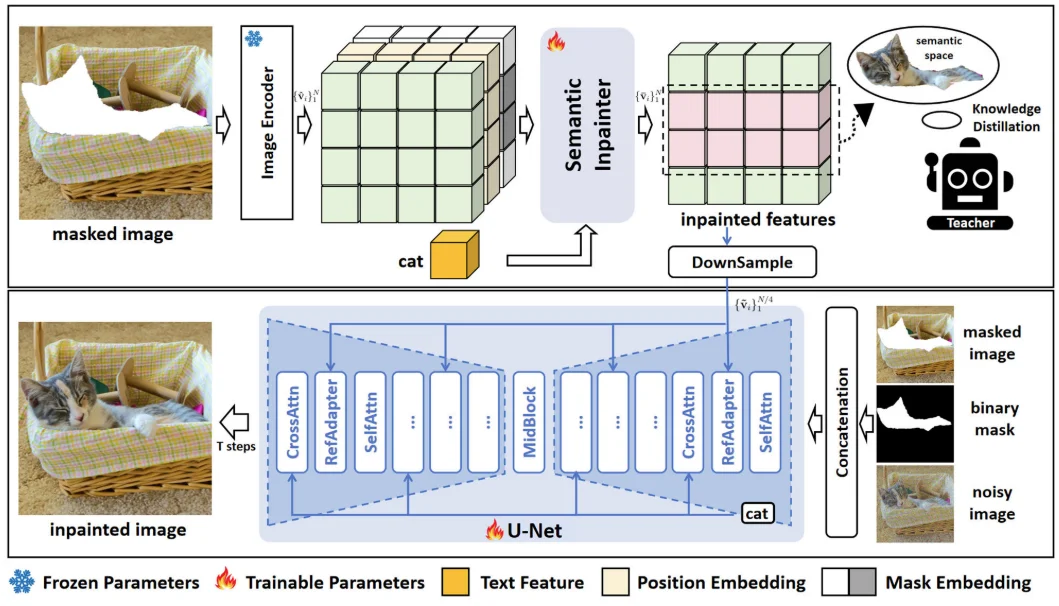
由于DDM生成过程中是不可控的,本文提出通过text来提高模型可控。相比较之前研究(直接将图片通过VAE处理输入DF中,并且将文本作为条件进行输入),最开始得到的latent space和text feature之间存在“信息不对齐”。在该文中“提前”将text feature输入到模型中。具体做法是:
- 首先通过CLIP来对齐特征信息
将image通过clip image encoder进行编码得到特征而后通过SemInpainter:同时结合可学习的位置信息(PE)、可学习的mask图像特征(ME)、文本特征,整个过程为: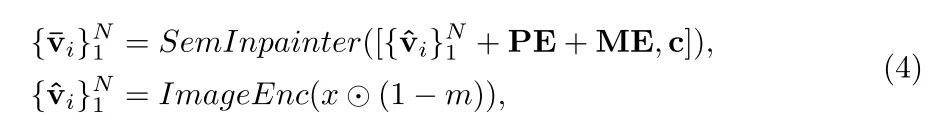
其中:SemInpainter(和CLIP的image encoder相似结构)根据视觉上下文和文本提示c的条件下,恢复CLIP空间中mask对象的ground-truth语义特征,说人话就是通过知识蒸馏方式来训练这个模块参数。对于两部分特征最后通过下采样方式得到最后特征: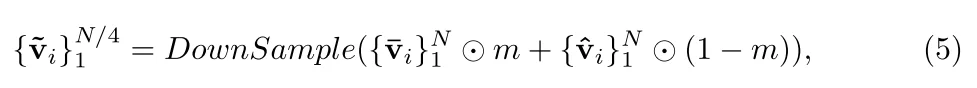
- **reference adapter layer (RefAdapter) **
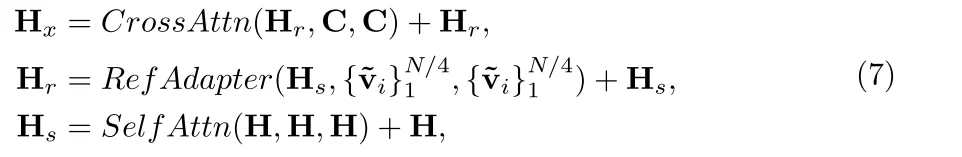
Attentive Eraser
Attentive Eraser: Unleashing Diffusion Model’s Object Removal Potential via Self-Attention Redirection Guidance
测试demo
AAAI-2025
模型结构:

模型出出发点:图像擦除过程中会生成随机伪影,以及在删除后无法用适当的内容重新绘制前景对象区域。主要改进:
1、Attention Activation and Suppres-sion (AAS):是一种自我注意机制修改操作,专为应对物体移除任务的固有挑战而量身定制,旨在使前景物体区域的生成更加关注背景,同时消除物体的外观信息。此外,”相似性抑制”(SS)可抑制由于自我注意的固有特性而可能导致的对相似物体的高度关注。具体做法:计算得到注意得分:$S$;以及$A=softmax(S)\in R^{N^2 \times N^2}$。其中具体计算方式(对于上面流程图中对呀公式序号,其中$M_{l,t}$代表的是如果属于obg那么标记1否则0):


对于公式13:强化obj信息(将$obj\rightarrow obj$设定为负无穷);对于公式14:强化$obj\rightarrow bg$ 将其设为负无穷。
2、Self-Attention Redirection Guidance (SARG):这是一种应用于扩散反向取样过程的引导方法,它通过 AAS 利用重定向自我注意引导取样过程朝物体移除的方向进行。
算法流程:
Attentive Eraser实际测试效果
| 原图 | Mask | 结果 | |
|---|---|---|---|
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  |
总结
简单终结上面几篇论文,基本出发思路都是基于Stable diffusion Moddel然后通过修改Condition方式:无论为是CLip编码文本嵌入还是clip编码图像嵌入。不过值得留意几个点:1、对于mask内容可以用“非规则”(类似对mask内容进行膨胀处理)的方式输入到模型中来提高能力。2、在图像擦除中容易出现几个小问题:图像替换问题(理论上是擦除图像但是实际被其他图像给“替换”)、图像模糊问题(擦除图像之后可能会在图像上加一个“马赛克”,擦除区域模糊)对于这两类问题可以参考论文。
进一步阅读: 1、https://arxiv.org/pdf/2504.00996;2、RAD: Region-Aware Diffusion Models for Image Inpainting