视觉多模态模型在结构上比较统一,一个视觉编码器(较多使用的是Vit/Resnet等)对图像信息进行处理,然后将其和文本信息一起结合然后输入到LLM模型中得到最后的结果,因此在此过程中一个最大的挑战就是:如果将不同模态信息进行结合(当然有些可能还需要考虑如何将图像进行压缩,这里主要是考虑有些图像的分辨率比较高)。
Clip
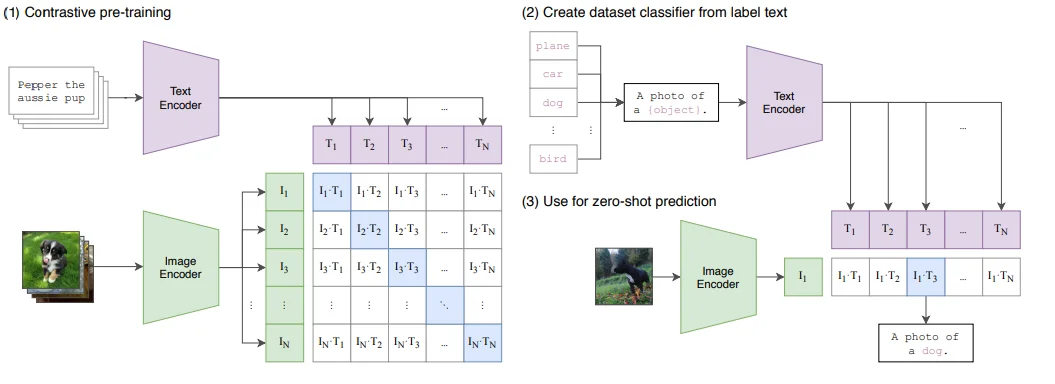
代表模型 CLIP1,更加像一种 图像-文本对齐模型,按照论文里面他自己提到的计算范式:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
在将 Image 和 Text 编码完成之后,直接计算它们之间的相似度,实现模态之间的对齐。优化过程的目标是让匹配的图文对的相似度尽可能大,同时让不匹配对的相似度尽可能小。换言之,CLIP 的对比学习机制本质上是在学习一种跨模态的相似度表示。其核心机制是通过对比学习和嵌入空间对齐,将图像和文本映射到一个共享的语义空间中。
尽管 CLIP 本身并不直接包含复杂的推理能力或任务特定的知识,但它通过大规模预训练,展现出了强大的通用性和零样本学习能力。在论文中,CLIP 表现出了不俗的零样本性能,但需要注意的是,CLIP 的主要目标是学习跨模态的对齐表示,这使得它能够胜任多种任务(如图文检索、零样本分类等)。相比于传统的目标识别模型,CLIP 更像是一个多模态的基础模型,具备更广泛的适用性和灵活性。
ALBEF
Albef2模型基本结构如下: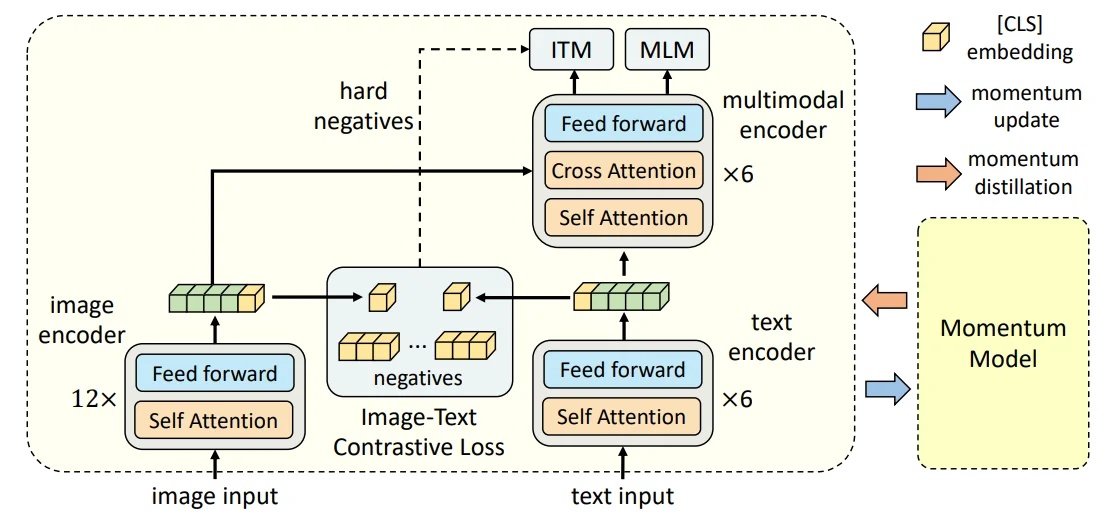
模型结构:1、图像编码器(12层的Vit-B/16);2、文本编码器(6层 $\text{BERT}{\text{base}}$ );3、多模态编码器(6层 $\text{BERT}{\text{base}}$)。对于文本和图像都会编码为带前缀的向量,图像:${v_{cls},v_1,…,v_N}$,文本:${w_{cls},w_1,…,w_N}$。
训练过程:1、模态对齐(ITC):这个过程主要是计算image-to-text以及text-to-image相似性计算过程如下: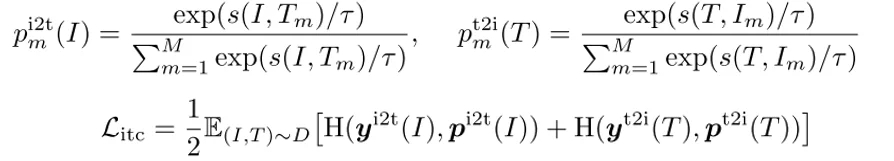
其中 $s(I, T_m)=g_v(v_{cls})^Tg^′(w^′_{cls})$,相似性计算公式中 $g$主要是将 [CLS]通过线性处理处理到256维,而 $g^′$则是通过动量编码器的规范化特征表示。$y$代表GT。
对于这个loss计算过程再Albef中会改写为:
其中$s$代表score function(比如说直接计算点乘),$\tau$温度稀疏
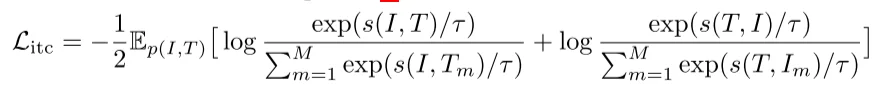
2、遮蔽语言模型( MLM ):直接预测被MASK掉的词;3、图文匹配(ITM):主要是判断图文之间匹配,对于这两个过程数据处理为:
BLIP
BLIPv1
BLIP-13模型结构如下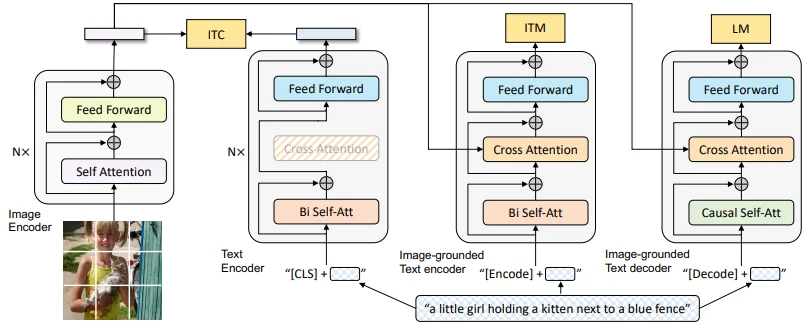
对于模型使用对于视觉编码器直接使用Vit,对于文本编码器直接使用BERT,不过值得注意的是和Albef中处理相同的是在特征前面都会选择添加一个[CLS]标记然后其他结构集合上面的一致。在模型结构上主要分为3块:1、Text Encder;2、Image grounded Text encoder;3、Image-grouned Text decoder;对于这3块都分别对应的去计算ITC、ITM以及LM3个损失,其中前两个和Albef中计算方式相同。除此之外虽然设计了3个模块但是模块之间参数是共享的(颜色相同那么参数就是相同的)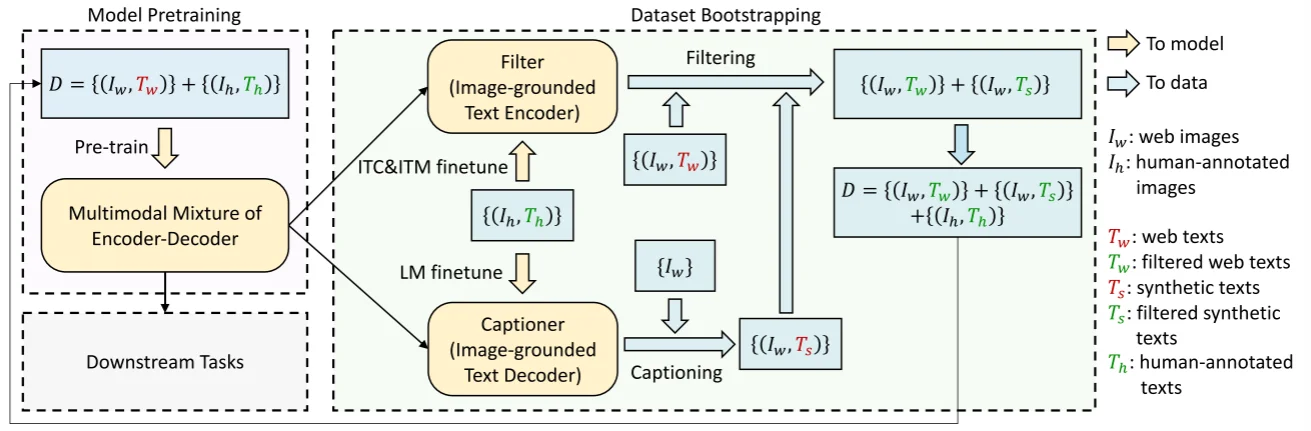
论文中数据合成方法,其实还是基于BLIP自身的encoder-decoder结构,首先是通过标注的数据($I_h,T_h$)进行训练模型在得到很好的效果之后,将未标注的图片 $I_w$直接输入到模型中生成图-文对($I_w,T_s$)以及从网络上搜索得到的图-文对($I_w,T_w$)此时这两部分图文对不是很“恰当的”通过filter去过滤掉不合适的配对这样一来最后就可以得到相对干净的图-文对。
其中
filter设计就是直接使用 image-ground text encoder通过直接微调来让模型知道 图-文匹配效果
BLIPv2
BLIP-24模型结构如下: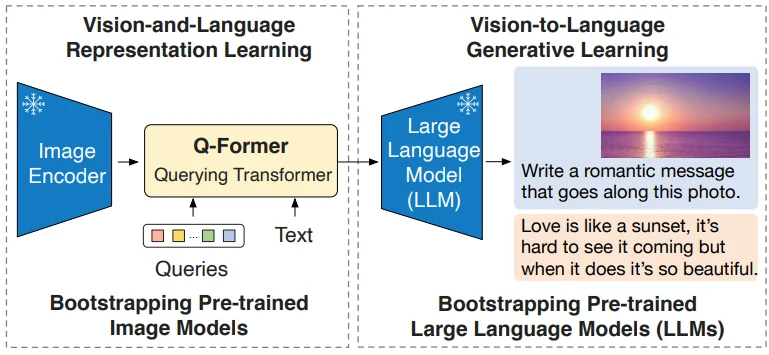
在 BLIP-2中同时冻结了Image Encoder以及LLM因此为了弥补不同模态之间的差异,就需要设计一个“模块”来进行表示(在论文中做法是:通过设计一个Q-Former将Image/Text上的信息都”反映“到一个Learned-Queries上)。
Q-Former通过初始化的query然后将图片和文本特征都反映到query上,其结构就是直接使用BERT作为主体结构,通过改变BERT的输入数据来保证对于图片和文本的特征“反映”
具体操作分为两个阶段: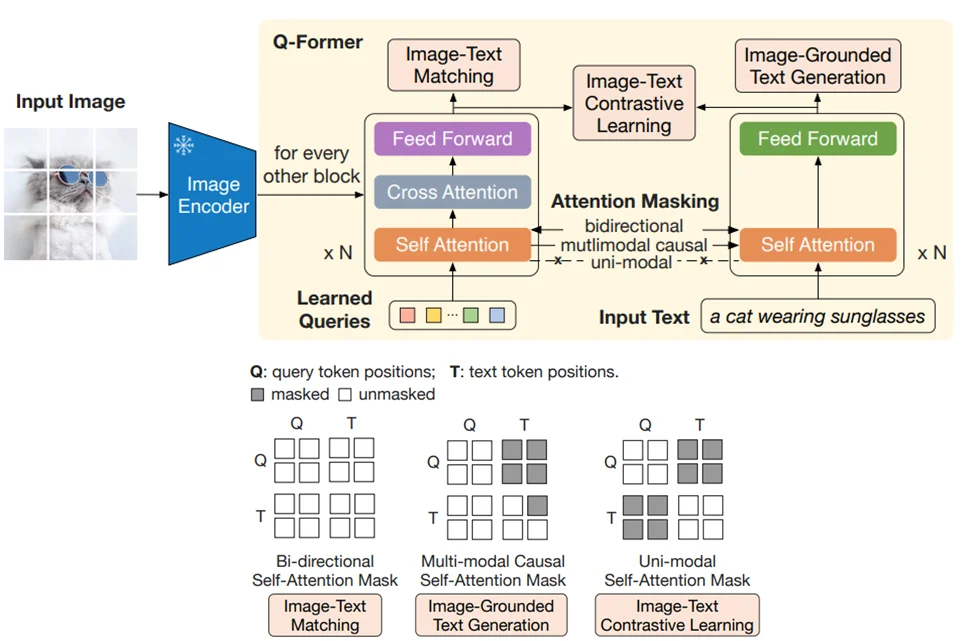
第一阶段:结构图如上所述通过冻结image-encoder,模型对于输出首先进行处理过程:
image_embeds = self.ln_vision(self.visual_encoder(image))
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.Qformer.bert(query_embeds=query_tokens,encoder_hidden_states=image_embeds,encoder_attention_mask=image_atts,...)
image_feats = F.normalize(self.vision_proj(query_output.last_hidden_state), dim=-1)
text_tokens = self.tokenizer(text,...)
text_output = self.Qformer.bert(text_tokens.input_ids,...)
对于self.query_tokens初始化直接通过生成全0的向量。除此之外对于初始化后的 query_tokens之后会通过 self.Qformer.bert(Qformer采用的还是BERT结构,因此所有的上面结构图中涉及到的各种attention mask操作也都是再bert中计算只是通过参数:attention_mask控制)将其核图像特征进行“交互”最后得到 image_feats,而对于文本处理过程就比较简单直接tokenizer处理之后再去有bert编码即可得到text_feat
在得到3部分输入之后再Qformer中而后进行3个训练任务:
1、图片对比损失ITC(代码):
sim_q2t = torch.matmul(image_feats.unsqueeze(1), text_feat_all.unsqueeze(-1)).squeeze()
sim_i2t, _ = sim_q2t.max(-1)
sim_i2t = sim_i2t / self.temp
sim_t2q = torch.matmul(text_feat.unsqueeze(1).unsqueeze(1), image_feats_all.permute(0, 2, 1)).squeeze()
sim_t2i, _ = sim_t2q.max(-1)
sim_t2i = sim_t2i / self.temp
...
loss_itc = (
F.cross_entropy(sim_i2t, targets, label_smoothing=0.1)+
F.cross_entropy(sim_t2i, targets, label_smoothing=0.1)) / 2
对于ITC中计算 InfoNCE
2、图片文本配对ITM(代码):这个过程首先再ITC中会得到 sim_t2i 和 sim_i2t这两个矩阵(分别代表图片文本相似度矩阵),这样一来就可以直接更具这个相似度矩阵去不匹配的图文对和文图对。最终,作为正样本的图文对就是原始输入的图文对,而作为负样本的图文对和文图对就是通过相似矩阵采样出来的。
image_embeds_all = torch.cat([image_embeds, image_embeds_neg, image_embeds], dim=0) # pos, neg, pos
image_atts_all = torch.ones(image_embeds_all.size()[:-1], dtype=torch.long).to(image.device)
...
text_ids_all = torch.cat([text_tokens.input_ids, text_tokens.input_ids, text_ids_neg], dim=0) # pos, pos, neg
query_tokens_itm = self.query_tokens.expand(text_ids_all.shape[0], -1, -1)
...
output_itm = self.Qformer.bert(
text_ids_all,
query_embeds=query_tokens_itm,
attention_mask=attention_mask_all,
encoder_hidden_states=image_embeds_all,
encoder_attention_mask=image_atts_all,...)
vl_embeddings = output_itm.last_hidden_state[:, : query_tokens_itm.size(1), :]
vl_output = self.itm_head(vl_embeddings)
logits = vl_output.mean(dim=1)
itm_labels = torch.cat([torch.ones(bs, dtype=torch.long), torch.zeros(2 * bs, dtype=torch.long)],dim=0,).to(image.device)
loss_itm = F.cross_entropy(logits, itm_labels)
3、图片生成文本ITG:
lm_output = self.Qformer(
decoder_input_ids,
attention_mask=attention_mask,
past_key_values=query_output.past_key_values,
return_dict=True,
labels=labels,
)
loss_lm = lm_output.loss
通过上面三个任务,训练好的query tokens和Q-Former就能够将image encoder提取的原始图像特征和文本特征进行拉近。理论上,这个阶段的模型,就是一个训练完成的图文多模态模型。该模型能够完成图文retrieval、图文匹配、图生文的任务5。为了进一步利用LLMs的生成能力和zero-shot能力,训练进入第二阶段。
第二阶段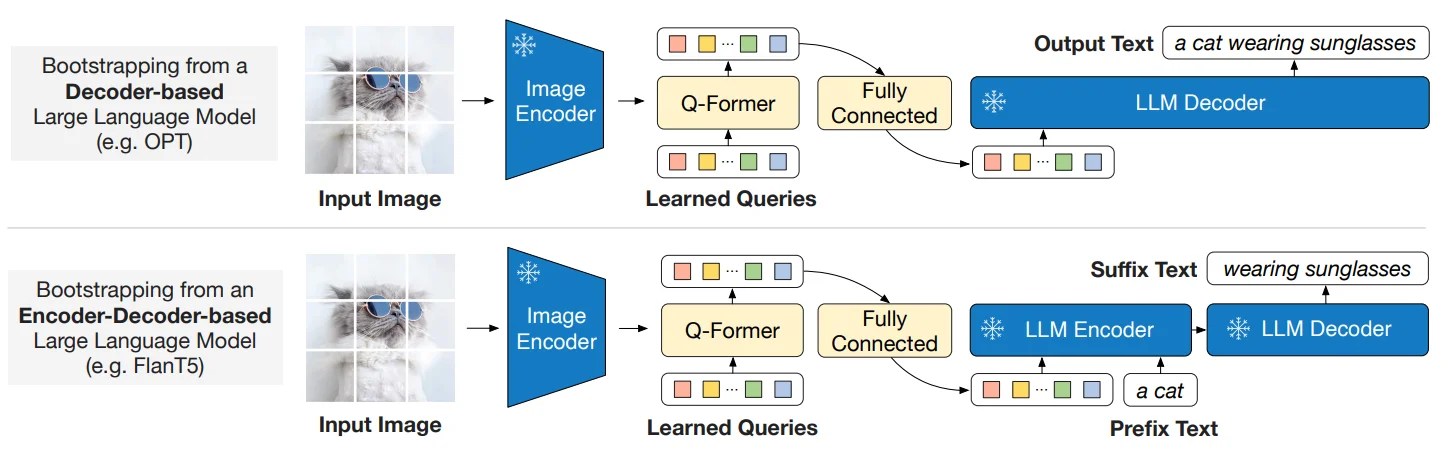
LLMs是一个生成式模型,整个流程是:冻结的Image Encoder生成原始的图像特征,而query tokens和Q-Former从原始图像特征中生成转化好的图像特征,然后该图像特征经过全连接层映射到LLMs的文本embedding空间中。然后这些映射后的图像特征,就相当于视觉prompts,和文本embedding一起,输入到冻结的LLMs中,最后生成目标文本。
总结
上面提到几个模型Clip、Albef、Blipv1、Blipv2首先再文本以及图片编码上差异不大,特征对齐上也都是选择 对比学习方式去对齐图片和文本之间的模态信息,后面3个模型在模态对齐上选择计算方式都是 InfoNCE
\(\mathcal{L}_{\text{itc}} = -\frac{1}{2} \mathbb{E}_{p(I,T)} \left[ \log \frac{\exp(s(I,T)/\tau)}{\sum_{m=1}^M \exp(s(I,T_m)/\tau)} + \log \frac{\exp(s(T,I)/\tau)}{\sum_{m=1}^M \exp(s(T,I_m)/\tau)} \right]\)
不过在Blipv2中是将文本,图片信息都反映到一个初始化的query上。