前文已经介绍了VAE以及GAN这里介绍另外一个模型:Diffusion Model,除此之外介绍Conditional diffusion model、Latent diffusion model
Diffusion Model
diffusion model(后续简称df)模型原理很简单:前向过程在一张图像基础上不断添加噪声得到一张新的图片之后,反向过程从这张被添加了很多噪声的图像中将其还原出来。原理很简单,下面直接介绍其数学原理: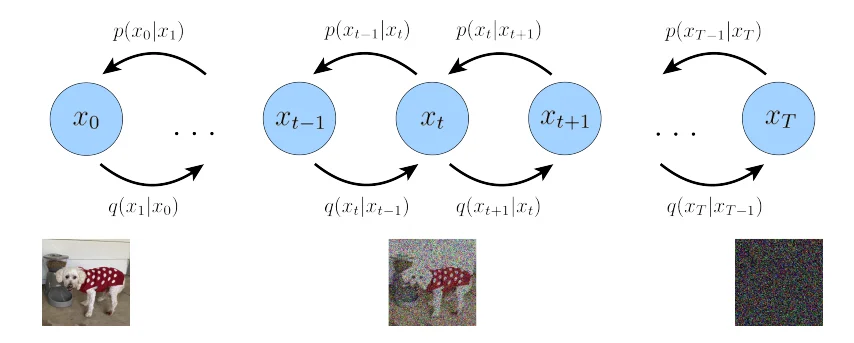
上图中实线代表:反向过程(去噪);虚线代表:前向过程(加噪)
那么我们假设最开始的图像为 $x_0$通过不断添加噪声(添加噪声过程假设为$t$)那么我们的 前向过程:$q(x_1,…,x_T\vert x_0)=q(x_0)\prod_{t=1}^T q(x_t\vert x_{t-1})$,同理 反向过程:$p_\theta(x_0,…\vert x_{T})=p(x_T)\prod_{t=1}^Tp_\theta(x_{t-1}\vert x_t)$
前向过程
在df的前向过程中:
\[q(x_1,...,x_T\vert x_0)=q(x_0)\prod_{t=1}^T q(x_t\vert x_{t-1})\]通常定义如下的高斯分布:$q(x_t\vert x_{t-1})=N(x_t;\sqrt{1-\beta_t}x_{t-1},\beta_tI)$,其中参数$\beta$就是我们的 噪声调度参数来控制我们每一步所添加的噪声的“权重”(这个权重可以固定也可以时间依赖,对于时间依赖很好理解最开始图像是“清晰”的在不断加噪声过程中图像变得越来越模糊),于此同时随着不断的添加噪声那么数据$x_0$就会逐渐的接近标准正态分布 $N(0,I)$的 $x_t$,整个加噪过程就为:
\[\begin{align*} t=1 \quad & x_1 = \sqrt{1 - \beta_1} x_0 + \sqrt{\beta_1} \epsilon_1 \\ t=2 \quad & x_2 = \sqrt{1 - \beta_2} x_1 + \sqrt{\beta_2} \epsilon_2 \\ &\vdots \\ t=T \quad & x_T = \sqrt{1 - \beta_T} x_{T-1} + \sqrt{\beta_T} \epsilon_T \end{align*}\]在上述过程中我们可以将$t=1$得到的 $x_1$代到下面 $t=2$的公式中,类似的我们就可以得到下面的结果:$x_2=\sqrt{(1-\beta_2)(1-\beta_1)}x_0+ \sqrt{1-(1-\beta_2)(1-\beta_1)}\epsilon$ (之所以用一个$\epsilon$是因为上面两个都是服从相同高斯分布就可以直接等同过来)那么依次类推就可以得到下面结果:
\[\begin{align*} x_T=\sqrt{(1-\beta_1)\dots(1-\beta_T)}x_0+ \sqrt{1-(1-\beta_1)\dots(1-\beta_T)}\epsilon \\ \Rightarrow x_T=\sqrt{\bar{\alpha_T}}x_0+ \sqrt{1-\bar{\alpha_T}}\epsilon \end{align*}\]其中:$\bar{\alpha_T}=\sqrt{(1-\beta_1)\dots(1-\beta_T)}$,那么也就是说对于前向过程(加噪过程)可以从$x_0$到 $x_T$一步到位,不需要说再去逐步计算中间状态了。
反向过程
反向过程:$p_\theta(x_0,…\vert x_{T})=p(x_T)\prod_{t=1}^Tp_\theta(x_{t-1}\vert x_t)$,也就是从最开始的标准正态分布的 $x_t$逐步去除噪声最后还原得到 $x_0$。仔细阅读上面提到的前向和反向过程中都是条件概率但是在反向传播过程中会使用一个参数$\theta$,这是因为前向过程最开始的图像和噪声我们是都知道的,而反向过程比如$p(x_{t-1}\vert x_t)$是难以直接计算的,需要知道整个数据分布,因此我们可以通过神经网路去近似这个分布,而这个神经网络就是我们的参数:$\theta$。于此同时反向过程也会建模为正态分布:$p_\theta(x_{t-1}\vert x_t)=N(x_{t-1};\mu_\theta(x_t,t),\sum_\theta(x_t,t))$,其中 $\sum_\theta(x_t,t)$为我们的方差对于在值可以固定也可以采用网络预测1
在OpenAI的Improved DDPM中使用的就是使用预测的方法:$\sum_\theta(x_t,t)=\exp(v\log\beta_t+(1-v)\hat{\beta_t})$,直接去预测系数:$v$
回顾一下生成模型都在做什么。在GAN中是通过 生成器网络 来拟合正式的数据分布也就是是 $G_\theta(x)≈P(x)$,在 VAE中则是通过将原始的数据分布通过一个 低纬的潜在空间来表示其优化的目标也就是让 $p_\theta(x)≈p(x)$,而在Diffusion Model中则是直接通过让我们 去噪过程得到结果 和 加噪过程结果接近,什么意思呢?df就像是一个无监督学习我所有的GT都是知道的(每一步结果我都知道)也就是是让:$p_\theta(x_{t-1}\vert x_t)≈p(x_{t-1}\vert x_t)$ 换句话说就是让我们最后解码得到的数据分布和正式的数据分布相似:$p_\theta(x_0)≈p(x_0)$ 既然如此知道我们需要优化的目标之后下一步就是直接构建损失函数然后去优化即可。
优化过程
通过上面分析,发现df模型的优化目标和VAE的优化目标很相似,其损失函数也是相似的,首先我们的优化目标是最大化下面的边际对数似然2:$\log p_\theta(x_0)=\log \int_{x_{1:T}}p_\theta(x_0,x_{1:T})dx_{1:T}$,对于这个积分计算是比较困难的,因此引入:$q(x_{1:T}\vert x_0)$ 那么对于这个公式有:
\[\begin{align*} \log p_\theta(x_0)&=\log \int_{x_{1:T}}p_\theta(x_{0:T})dx_{1:T} \\ &=\log \int_{x_{1:T}} q(x_{1:T}\vert x_0)\frac{p_\theta(x_{0:T})}{q(x_{1:T}\vert x_0)}dx_{1:T}\\ &=\log\mathbb{E}_{q(x_{1:T|x_0})}[\frac{p_\theta(x_{0:T})}{q(x_{1:T}\vert x_0)}]\\ &≥\mathbb{E}_{q(x_{1:T|x_0})}[\log \frac{p_\theta(x_{0:T})}{q(x_{1:T}\vert x_0)}]\\ &=\underbrace{\mathbb{E}_{q(\boldsymbol{x}_1|\boldsymbol{x}_0)}[\log p_\theta(\boldsymbol{x}_0|\boldsymbol{x}_1)]}_{\text{reconstruction term}} - \underbrace{\mathbb{E}_{q(\boldsymbol{x}_{T-1}|\boldsymbol{x}_0)}[D_{\text{KL}}(q(\boldsymbol{x}_T|\boldsymbol{x}_{T-1})\parallel p(\boldsymbol{x}_T))]}_{\text{prior matching term}} - \sum_{t=1}^{T-1} \underbrace{\mathbb{E}_{q(\boldsymbol{x}_{t-1},\boldsymbol{x}_{t+1}|\boldsymbol{x}_0)}[D_{\text{KL}}(q(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\parallel p_\theta(\boldsymbol{x}_t|\boldsymbol{x}_{t+1})]}_{\text{consistency term}}\\ &=\underbrace{\mathbb{E}_{q(\boldsymbol{x}_1|\boldsymbol{x}_0)}[\log p_\theta(\boldsymbol{x}_0|\boldsymbol{x}_1)]}_{\text{reconstruction term}} - \underbrace{D_{KL}(q(x_T|x_0)||p(x_T))}_{\text{prior matching term}} - \sum_{t=2}^{T} \underbrace{\mathbb{E}_{q(\boldsymbol{x}_{t}|\boldsymbol{x}_0)}[D_{\text{KL}}(q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t}, x_0)\parallel p_\theta(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t})]}_{\text{denoisiong matching term}} \end{align*}\]中间化简步骤可以见论文2中的描述(论文里面有两个推导,推导步骤直接省略,第二个等式: $q(x_t\vert x_{t-1})=q(x_t\vert x_{t-1},x_0)$),那么上面结果分析,在计算我们的参数$\theta$时候(反向传播求导计算)第2项直接为0,第1项可以直接通过蒙特卡洛模拟就行计算,那么整个结果就只有第三项,因此对于第二个等式为例可以将优化目标变为:$\text{arg}\min_\theta D_{KL}(q(x_{t-1}\vert x_t, x_0)\Vert p_\theta(x_{t-1}\vert x_t))$
对于这个优化目标根据论文3可以得到:
最终,训练目标是让神经网络 $\epsilon_\theta$ 准确预测前向过程中添加的噪声,从而实现高效的去噪生成,因此整个DF模型训练和采样过程就变为3:

比如说下面一个例子:对于输入数据$x_0=[1,2]$ 于此同时假设我们的采样噪声 $\epsilon \in[0.5, -0.3]$并且进行500次加噪声处理,假设$\bar{\alpha}_{500} = 0.8$那么计算500次加噪得到结果为:
\[x_t=\sqrt{\bar{\alpha_t}}x_0+ \sqrt{1-\bar{\alpha_t}}\epsilon=\sqrt{0.8}\times[1,2]+\sqrt{0.2}[0.5, -0.3]≈[1.118,1.654]\]关键在于损失函数,通过上面简化过程可以直接通过模型预测噪声因此可以直接计算$\epsilon_\theta(x_t,t)=[0.48,-0.28]$然后去计算loss即可。直接上代码,代码实现上面过程可以自定义实现/使用diffusers4
diffusers实现简易demo
from diffusers import DDPMScheduler
# 直接加载训练好的调度器
# scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
# 初始化调度器
scheduler = DDPMScheduler(num_train_timesteps=1000) #添加噪声步数
...
for image in train_dataloader:
# 假设 image为 32,3,128,128
noise = torch.randn(image.shape, device=image.device)
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps,
(image.shape[0],), device=image.device, dtype=torch.int64)
noisy_images = scheduler.add_noise(image, noise, timesteps) # 32 3 128 128
...
noise_pred = model(noisy_images)
loss = F.mse_loss(noise_pred, noise)
...
Conditional Diffusion Model
条件扩散模型(Conditional Diffusion Model)5顾名思义就是在使用DF过程中添加一个 限定条件(文本、图像等)来指导模型的生成(原理很简单,而且 条件扩散模型这个概念比较广泛,只要在生成图片过程中加上一个“条件”),这里主要介绍OpenAI的论文来解释 条件扩散模型。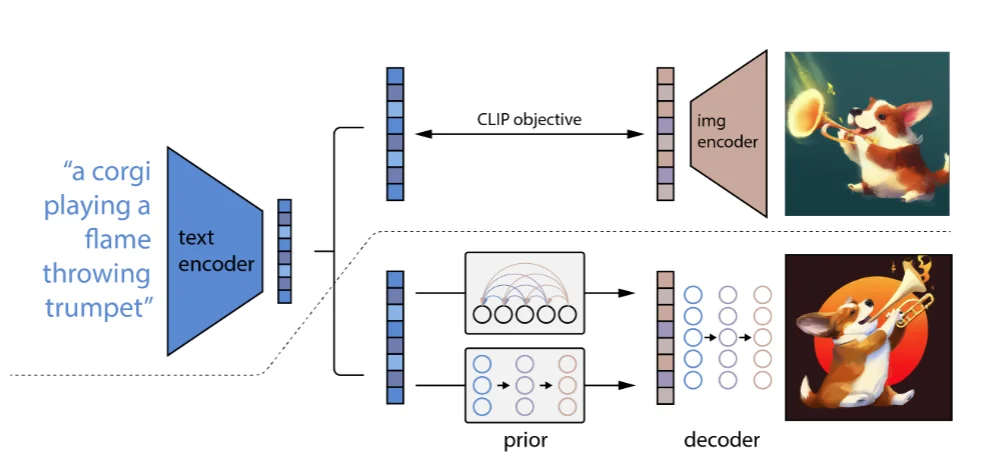
在论文里面提到了一点: 可以通过文本来提升模型的生成质量。主要了解一下对于条件如何嵌入到模型中:
1、直接相加范式:这类主要就是将文本、标签进行编码之后直接和 噪声/ 时间步进行相加而后进行后续实验;
2、注意力融合范式:比如下面的Stable Diffusion直接将文本编码之后融入到注意力里面进行计算
Latent Diffusion Model
对于Latent Diffusion Model(LDM)6主要出发点就是:最开始的DF模型在像素空间(高纬)进行评估这是消耗计算的,因此LDF就是直接通过对 autoencoding model得到的 潜在空间(低维)进行建模。整个思路就比较简单,用降低维度的潜在空间来进行建模,整个模型结构为(代码操作):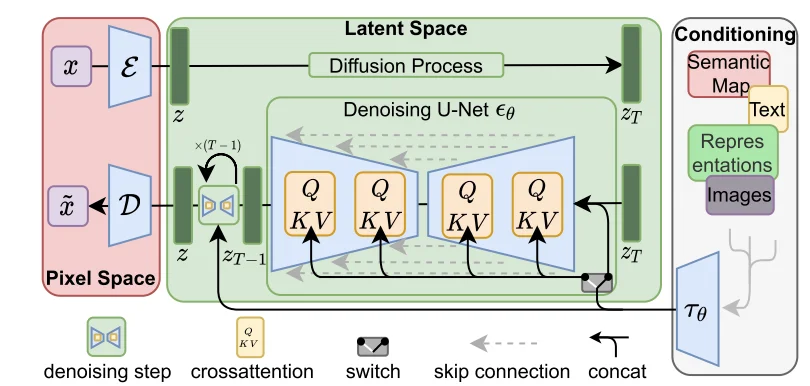
对于上述过程,输入图像为$x=[3,H,W]$而后通过encoder将其转化为 潜在空间($z=\varepsilon(x)$)而后直接在潜在空间 $z$进行扩散处理得到$z_T$直接对这个$z_T$通过U-Net进行建模,整个过程比较简单。不过值得注意的是在U-Net里面因为可能实际使用DF时候会有一些特殊输入(文本、图像等)因此会对这些内容通过一个encoder进行编码得到:$\tau_\theta(y)\in R^{M\times d_\tau}$,而后直接进行注意力计算:
\[\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d}})V\]其中:$Q=W_{Q}^{(i)}\cdot\varphi_{i}(z_{t}),K=W_{K}^{(i)}\cdot\tau_{\theta}(y),V=W_{V}^{(i)}\cdot\tau_{\theta}(y)$并且各个参数维度为:$W_V^{i}\in R^{d\times d_\epsilon^i},W_Q^i\in R^{d\times d_\tau},W_k^i\in R^{d\times d_\tau}$
DF模型生成
DDPM
最开始上面有介绍如何使用DF模型来进行生成,比如说在DDPM中生成范式为:
也就是说DDPM生成为:
\[x_{t-1}=\frac{1}{\sqrt{\alpha_t}}\left(x_t-\frac{1- \alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_\theta(x_t,t)\right)+\sigma_tz,\quad z\sim\mathcal{N}(0,I)\]但是这种生成范式存在问题,比如说T=1000那就意味着一张“合格”图片就需要进行1000次去噪如果1次是为为0.1s那么总共时间大概是100s如果要生产1000张图片那就是:1000x1000x0.1/60≈27h。这样时间花销就会比较大
DDIM
最开始在介绍DDPM中将图像的采样过程定义为马尔科夫链过程,而DDIM7则是相反直接定义为:非马尔科夫链过程
并且定义图像生成过程为:
\[x_{t-1}=\sqrt{\alpha_{t-1}}\left(\frac{x_t-\sqrt{1-\alpha_t}\epsilon_\theta(x_t,t)}{\sqrt{\alpha_t}}\right)+\sqrt{1-\alpha_{t-1}-\sigma_t^2}\epsilon_\theta(x_t,t)+\sigma_tz\]代码操作
DF模型结构
通过上面分析,知道对于 $x_T=\sqrt{\bar{\alpha_T}}x_0+ \sqrt{1-\bar{\alpha_T}}\epsilon$通过这个方式添加噪声,但是实际因为时间是一个标量,就像是最开始的位置编码一样,对于这些内容都会通过“类似位置编码”操作一样将其进行embedding处理然后在模型里面一般输入的参数也就是这三部分:
noise_image,time_step,class_label
Dit模型
更加详细原理描述: 深入浅出了解生成模型-6:常用基础模型与 Adapters等解析
将Transformer使用到Diffusion Model中,而Dit8在论文中进行的操作:通过一个autoencoder来将图像压缩为低维度的latent,扩散模型用来生成latent,然后再采用autoencoder来重建出图像,比如说在Dit中使用KL-f8对于输入图像维度为:256x256x3那么压缩得到的latent为32x32x4。Dit的模型结构为: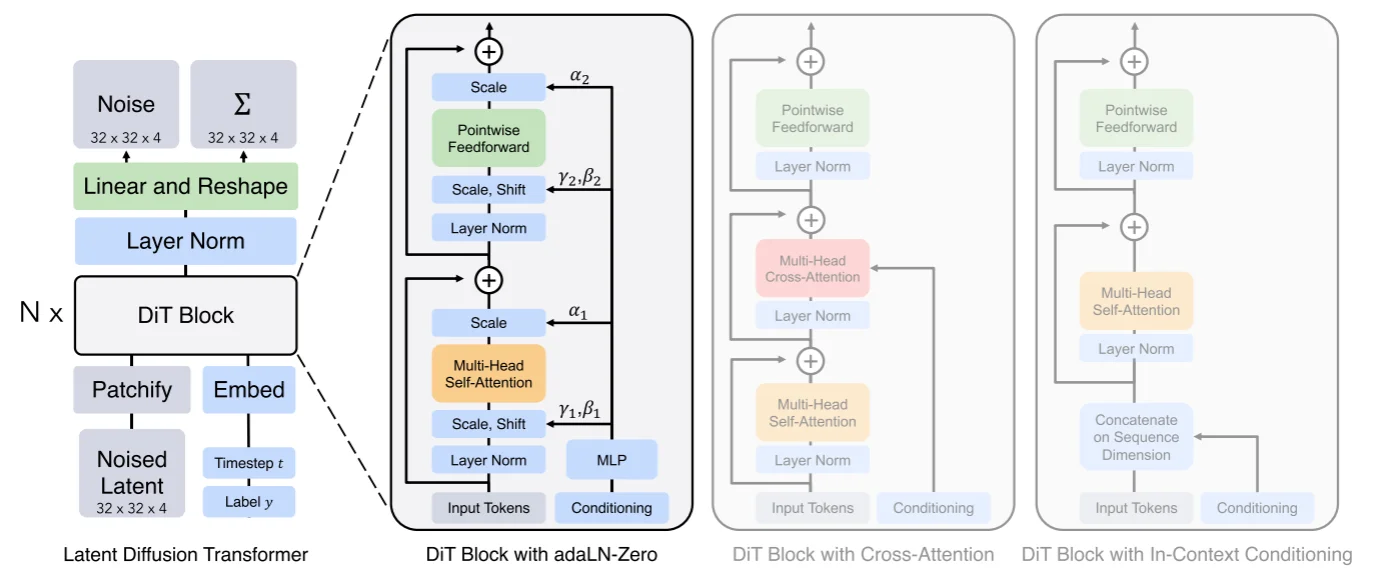
模型输入参数3个分别为:1、低纬度的latent;2、标签label;3、时间步t。对于latent直接通过一个patch embed来得到不同的patch(得到一系列的token)而后将其和位置编码进行相加得到最后的embedding内容,直接结合代码9来解释模型:
假设模型的输入为:
#Dit参数为:DiT(depth=12, hidden_size=384, patch_size=4, num_heads=6)
batch_size= 16
image = torch.randn(batch_size, 4, 32, 32).to(device)
t = torch.randint(0, 1000, (batch_size,)).to(device)
y = torch.randint(0, 1000, (batch_size,)).to(device)
那么对与输入分别都进行embedding处理:1、Latent Embedding:得到(8,64,384),因为patchembedding直接就是假设我们的patch size为4那么每个patch大小为:4x4x4=64并且得到32/4* 32/4=64个patches,而后通过线linear处理将64映射为hidden_size=384;2、Time Embedding和Label Embedding:得到(8,384)(8,384),因为对于t直接通过sin进行编码,对于label在论文里面提到使用 classifier-free guidance方式,具体操作就是在训练过程中通过dropout_prob来将输入标签随机替换为无标签来生成无标签的向量,在 推理过程可以通过 force_drop_ids来指定某些例子为无条件标签。将所有编码后的内容都通过补充位置编码信息(latent embedding直接加全是1,而label直接加time embedding),补充完位置编码之后就直接丢到 DitBlock中进行处理,对于DitBlock结构:
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x
在这个代码中不是直接使用注意力而是使用通过一个 modulate这个为了实现将传统的layer norm($\gamma{\frac{x- \mu}{\sigma}}+ \beta$)改为动态的$\text{scale}{\frac{x- \mu}{\sigma}}+ \text{shift}$,直接使用动态是为了允许模型根据时间步和类标签调整 Transformer 的行为,使生成过程更灵活和条件相关,除此之外将传统的残差连接改为 权重条件连接 $x+cf(x)$。再通过线性层进行处理类似的也是使用上面提到的正则化进行处理,处理之后结果通过unpatchify处理(将channels扩展2倍而后还原到最开始的输入状态)
Unet模型结构
Unet模型在前面有介绍过了就是通过下采样和上采用并且同层级之间通过特征拼接来补齐不同采用过程之间的“信息”损失。如果直接使用stable diffusion model(封装不多),假设参数如下进行代码操作:
{
'ch': 64,
'out_ch': 3,
'ch_mult': (1, 2, 4), # 通道增加倍数 in: 2,3,128,128 第一层卷积:2,64,128,128 通过这个参数直接结合 num_res_blocks来判断通道数量增加 ch_mut*num_res_blocks=(1, 1, 2, 2, 4, 4)
'num_res_blocks': 2, # 残差模块数量
'attn_resolutions': (16,),
'dropout': 0.1,
'resamp_with_conv': True,
'in_channels': 3,
'resolution': 128,
'use_timestep': True,
'use_linear_attn': False,
'attn_type': "vanilla"
}
基本模块
1、残差模块: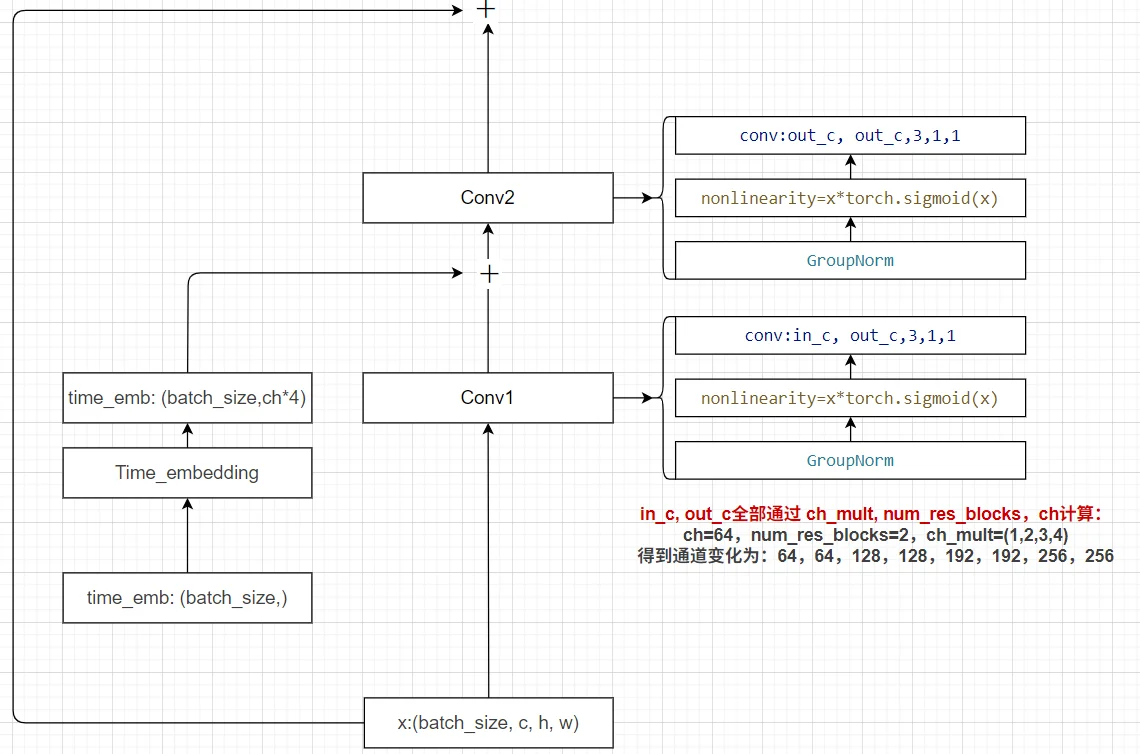
2、time embedding:直接使用attention的sin位置编码
具体过程
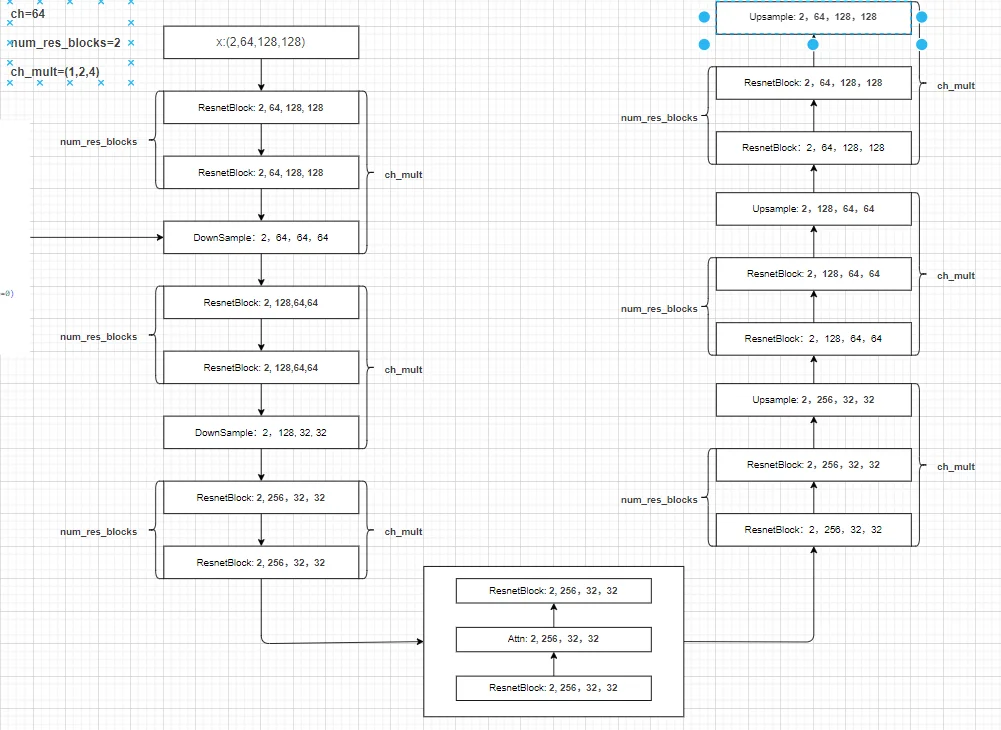
在得到的分辨率=attn_resolutions时候就会直接进行注意力计算(直接用卷积处理得到q,k,v然后进行计算attention),整个结构。如果这里直接使用diffuser里面的UNet模型进行解释(使用UNet2DModel模型解释),整个Unet模型就是3部分:1、下采样;2、中间层;3、上采样。假设模型参数为:
model = UNet2DModel(
sample_size= 128,
in_channels=3,
out_channels=3,
layers_per_block=2,
block_out_channels=(128, 128, 256, 256, 512, 512),
down_block_types=("DownBlock2D", "DownBlock2D", "DownBlock2D", "DownBlock2D", "DownBlock2D", "DownBlock2D"),
up_block_types=("UpBlock2D", "UpBlock2D", "UpBlock2D", "UpBlock2D", "UpBlock2D", "UpBlock2D")
).to(device)
整个过程维度变化,假设输入为:image:(32,3,128,128), time_steps: (32, ):
首先通过第一层卷积:(32,128,128,128)与此同时会将时间步进行编码得到:(32, 512)(如果有label数据也是(32,)那么会将其加入到time_steps中)
下采样处理:总共6层下采样,得到结果为:
Down-0: torch.Size([32, 128, 128, 128])
Down-1: torch.Size([32, 128, 64, 64])
Down-2: torch.Size([32, 256, 32, 32])
Down-3: torch.Size([32, 256, 16, 16])
Down-4: torch.Size([32, 512, 8, 8])
Down-5: torch.Size([32, 512, 4, 4])
中间层处理:torch.Size([32, 512, 4, 4])
上采样处理:总共6层上采样,得到结果为:
Up-0 torch.Size([32, 512, 8, 8])
Up-1 torch.Size([32, 512, 16, 16])
Up-2 torch.Size([32, 256, 32, 32])
Up-3 torch.Size([32, 256, 64, 64])
Up-4 torch.Size([32, 128, 128, 128])
Up-5 torch.Size([32, 128, 128, 128])
输出:输出就直接通过groupnorm以及silu激活之后直接通过一层卷积进行处理得到:torch.Size([32, 128, 128, 128])
DF训练
生成具有随机性展示图像效果不能很好说明模型生成能力
1、DDPM
对于传统的DF训练(前向+反向)比较简单,直接通过输入图像而后不断添加噪声而后解噪。以huggingface10上例子为例(测试代码),首先、对图像进行添加噪声。而后、直接去对添加噪声后的模型进行训练“去噪”(也就是预测图像中的噪声)。最后、计算loss反向传播。
对于加噪声等过程可以直接借助
diffusers来进行处理,对于diffuser:
1、schedulers:调度器
主要实现功能:1、图片的前向过程添加噪声(也就是上面的$x_T=\sqrt{\bar{\alpha_T}}x_0+ \sqrt{1-\bar{\alpha_T}}\epsilon$);2、图像的反向过程去噪;3、时间步管理等。如果不是用这个调度器也可以自己设计一个只需要:1、前向加噪过程(需要:使用固定的$\beta$还是变化的、加噪就比较简单直接进行矩阵计算);2、采样策略
测试得到结果为(因为HF官方提供了很好的参数去训练模型,因此测试新的数据集可能就没有那么效果好,只是做一个效果展示调参可能可以改善模型最后生成效果):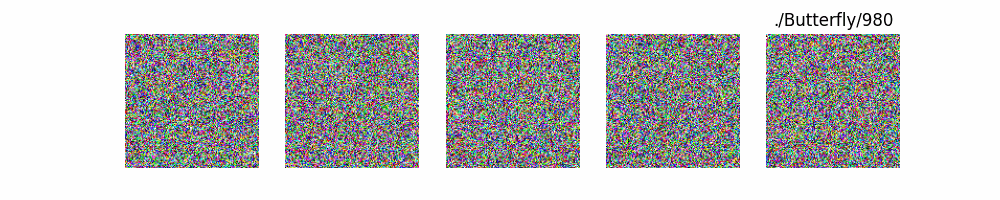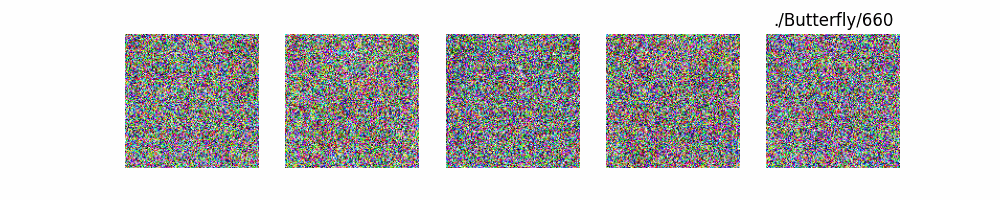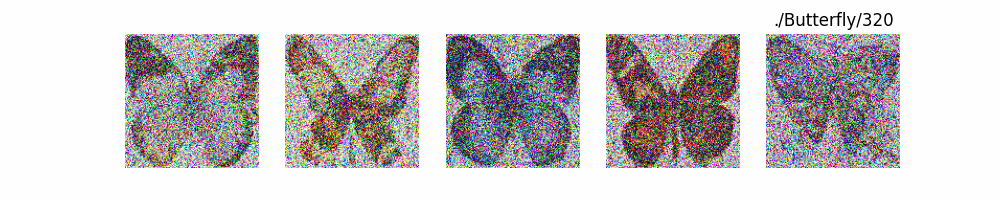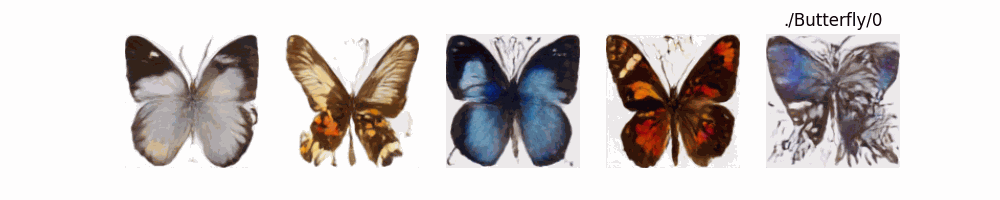
Stable Diffusion Model代码测试。数据集:”saitsharipov/CelebA-HQ”
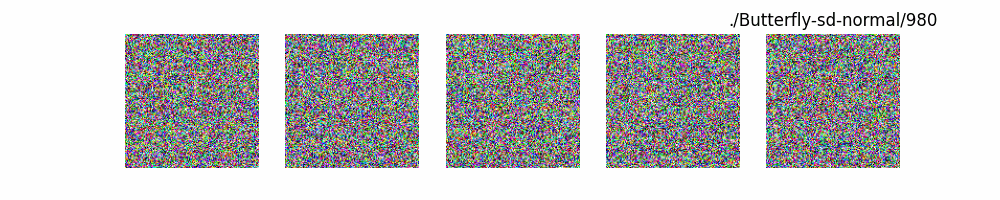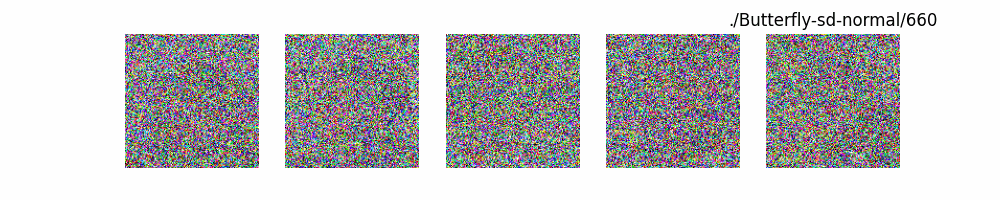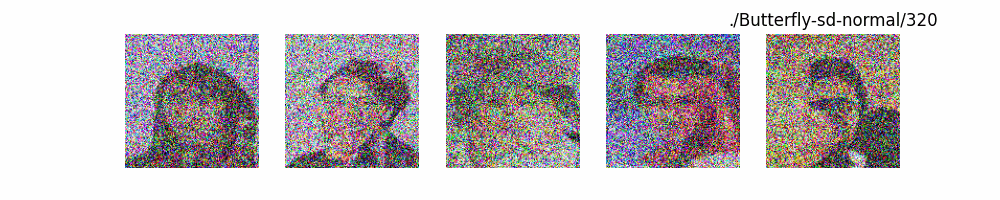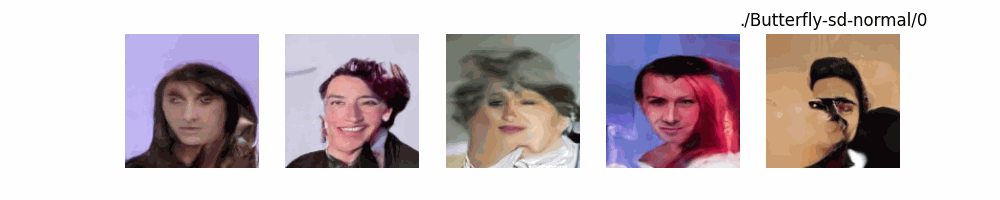
Hugging Face代码测试。数据集:”saitsharipov/CelebA-HQ”
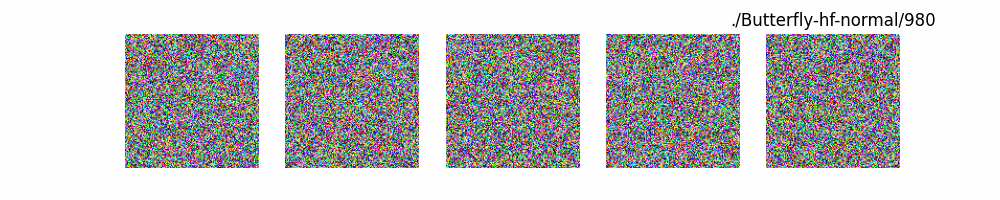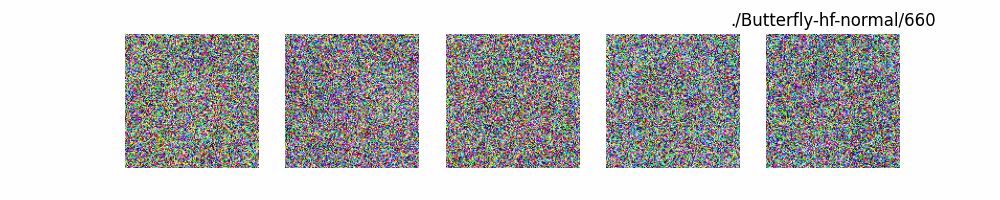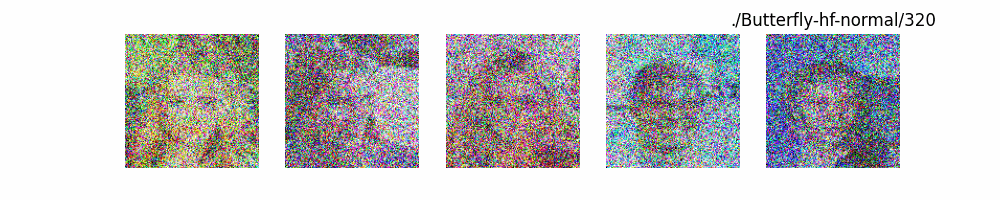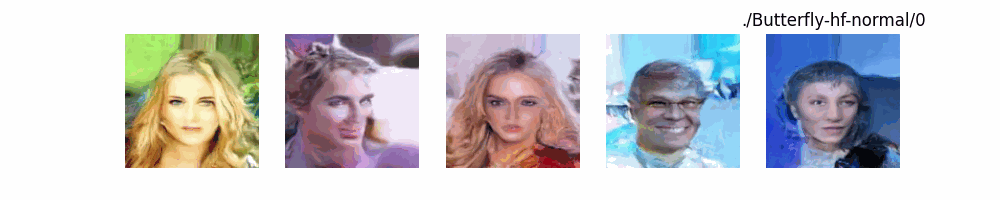
Dit代码测试。数据集:”saitsharipov/CelebA-HQ”
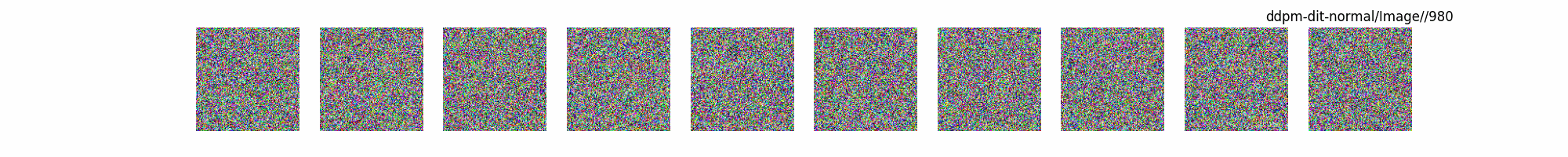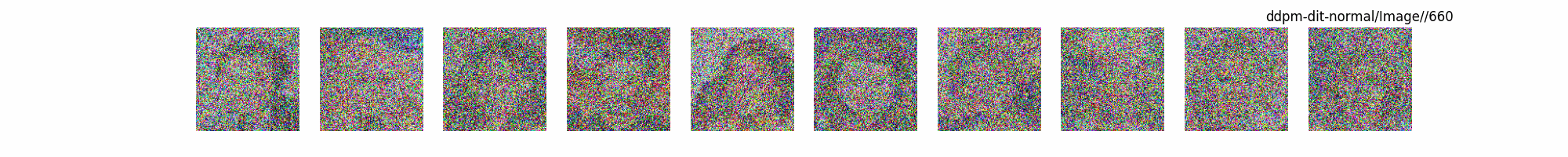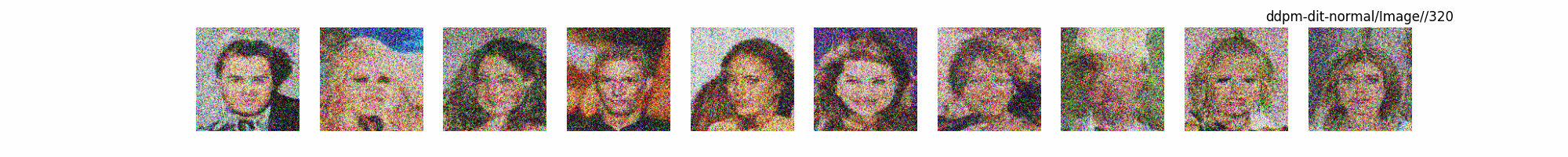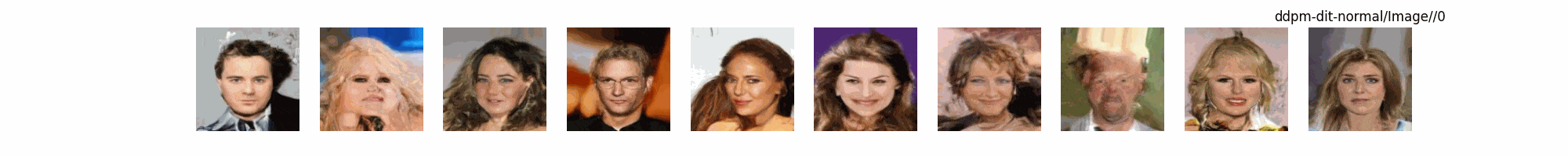
总结
上面介绍了各类DF以及具体的代码操作,总的来说在DF训练过程中(从代码角度)基本上就是这个公式:$x_t=\sqrt{\bar{\alpha_t}}x_0+ \sqrt{1-\bar{\alpha_t}}\epsilon$ 加噪过程得到$x_t$/去噪过程通过$x_t$通过去预测 噪声来优化模型的参数。于此同时训练过程中发现:扩散模型(如DDPM)确实倾向于先学习图像的低频信息(大致轮廓),再逐步学习高频信息(细节),这是由于模型的去噪过程和损失函数设计,因此扩散模型需要大量迭代(通常数千到数十万步)才能生成高质量图像,尤其在细节上需要长时间优化。比如下面为实际迭代过程中生成.
从左到右,从上到下,保存频率为每20个epoch保存一次,使用的模型为dit模型

参考
https://arxiv.org/pdf/2102.09672 ↩
https://huggingface.co/docs/diffusers/en/index ↩
https://arxiv.org/pdf/2204.06125 ↩
https://arxiv.org/abs/2112.10752 ↩
https://arxiv.org/pdf/2010.02502 ↩
https://arxiv.org/abs/2212.09748 ↩
https://github.com/facebookresearch/DiT ↩
https://huggingface.co/docs/diffusers/en/tutorials/basic_training ↩