torch计算图概念
在深度学习框架中,计算图(英文简称Graph)是一个有向无环图(DAG),它的节点代表操作(例如加法、乘法或者更复杂的函数),边则代表数据(例如张量或者标量)。计算图为深度学习中的前向传播(forward propagation)和反向传播(backward propagation)提供了一个可视化的框架,它能清楚地展示数据是如何流动和操作的。
在PyTorch中,计算图是随着代码计算过程动态构建的。“计算图捕获”(Graph Capture)就是通过分析/运行代码来捕获计算图的过程。捕获了计算图之后,PyTorch能够得到整个计算过程的全局视角,从而有可能进行更好的优化。例如,通过图优化,PyTorch可以删除没必要的计算,合并相似的操作,或者重新排列计算顺序,以此来提升计算效率
基础过程
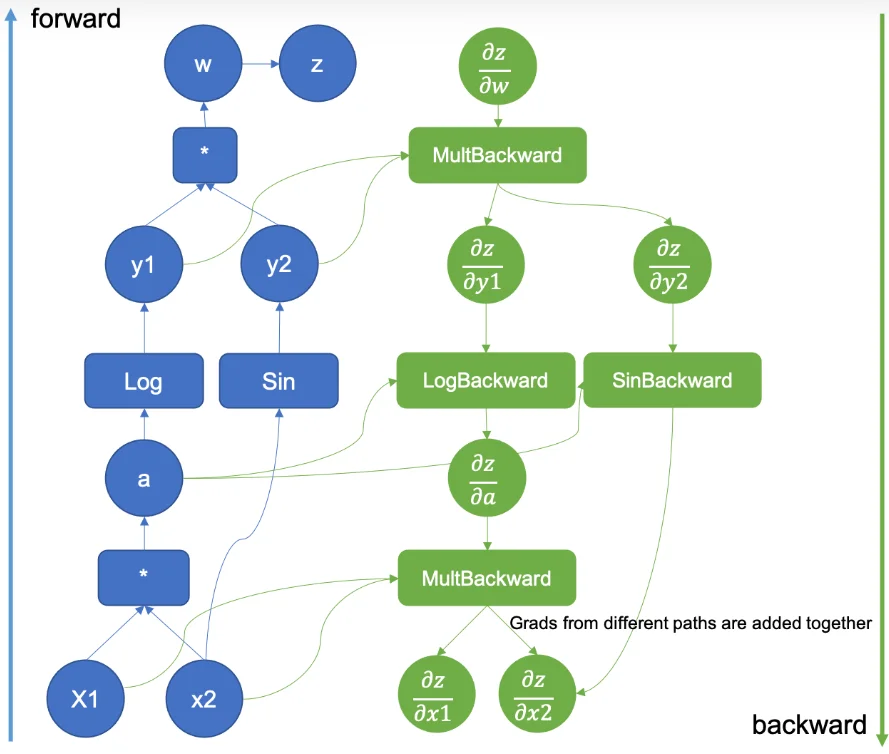
参考上图中给出的例子1,对于(pytorch中的)计算图而言主要起到的作用就是:用来记录张量之间的运算关系。涉及到的几个概念:1、节点(Node):张量(Tensor)或者运算(Function)。2、边(Edge):表示数据流和依赖关系,指明一个张量是由哪些运算生成的,或一个运算的输入来源于哪个张量。3、叶子节点(Leaf Tensor):通常是用户创建的、需要梯度的张量(requires_grad=True)。4、动态计算图:PyTorch 是 动态图框架,计算图会在每次 forward 运行时即时构建,执行完一次计算后,默认图会释放(除非使用retain_graph=True)。当通过调用 .backward() 时,PyTorch 会沿着这个计算图从输出节点反向传播,依次计算每个叶子节点的梯度。比如说对于上面的过程(上面过程中每一个圆圈节点就会对应一个节点,那么反向传播就可以去计算这些节点梯度去对参数进行更新):$z=w=y_1\times y_2= \log(a) \times \sin(x_2)=\log(x_1\times x_2)+ \sin(x_2)$
import torch
X1 = torch.tensor(2.0, requires_grad=True)
X2 = torch.tensor(3.0, requires_grad=True)
a = X1 * X2 # a = X1 * X2
y1 = torch.log(a) # y1 = log(a)
y2 = torch.sin(X2) # y2 = sin(X2)
w = y1 * y2 # w = y1 * y2
z = w # z = w
a.retain_grad()
y1.retain_grad()
y2.retain_grad()
w.retain_grad()
z.retain_grad()
print("Forward: z =", z.item())
z.backward()
print(f"dz/dz = 1 (输出对自己的梯度永远是1) -> {z.grad.item()}")
print(f"dz/dw = dz/dz * ∂z/∂w = 1 * 1 = {w.grad.item()}")
print(f"dz/dy1 = dz/dw * ∂w/∂y1 = {w.grad.item()} * y2 = {w.grad.item()} * {y2.item()} = {y1.grad.item()}")
print(f"dz/dy2 = dz/dw * ∂w/∂y2 = {w.grad.item()} * y1 = {w.grad.item()} * {y1.item()} = {y2.grad.item()}")
print(f"dz/da = dz/dy1 * ∂y1/∂a = {y1.grad.item()} * (1/a) = {y1.grad.item()} * (1/{a.item()}) = {a.grad.item()}")
print(f"dz/dX1 = dz/da * ∂a/∂X1 = {a.grad.item()} * X2 = {a.grad.item()} * {X2.item()} = {X1.grad.item()}")
print(f"dz/dX2 = dz/da * ∂a/∂X2 + dz/dy2 * ∂y2/∂X2\n"
f" = {a.grad.item()} * X1 + {y2.grad.item()} * cos(X2)\n"
f" = {a.grad.item()} * {X1.item()} + {y2.grad.item()} * {torch.cos(X2).item()}\n"
f" = {X2.grad.item()}")
输出结果为:
Forward: z = 0.2528530955314636
dz/dz = 1 (输出对自己的梯度永远是1) -> 1.0
dz/dw = dz/dz * ∂z/∂w = 1 * 1 = 1.0
dz/dy1 = dz/dw * ∂w/∂y1 = 1.0 * y2 = 1.0 * 0.14112000167369843 = 0.14112000167369843
dz/dy2 = dz/dw * ∂w/∂y2 = 1.0 * y1 = 1.0 * 1.7917594909667969 = 1.7917594909667969
dz/da = dz/dy1 * ∂y1/∂a = 0.14112000167369843 * (1/a) = 0.14112000167369843 * (1/6.0) = 0.023520000278949738
dz/dX1 = dz/da * ∂a/∂X1 = 0.023520000278949738 * X2 = 0.023520000278949738 * 3.0 = 0.07056000083684921
dz/dX2 = dz/da * ∂a/∂X2 + dz/dy2 * ∂y2/∂X2
= 0.023520000278949738 * X1 + 1.7917594909667969 * cos(X2)
= 0.023520000278949738 * 2.0 + 1.7917594909667969 * -0.9899924993515015
= -1.7267885208129883
对于计算图就是对于你的输入数据进行了那种计算方式进行记录,后续梯度反向传播时候通过上面计算图(计算图保存了所有中间变量和梯度信息)来计算梯度更新参数,那么进一步了解一下这些概念与显存的分析,运行过程中数据的显存占用主要如下几个部分:1、数据本身显存占用;2、数据中间激活(计算图)显存占用。对于这两部分可以直接通过checkpoint以及改变精度来减小显存占用。结果在后续计算中不再需要梯度,可以直接使用 .detach() 将其从计算图中分离,以减少显存占用。如果要得到模型具体的计算图下面两种方法:
import torch
from torchviz import make_dot
from torchvision.models import resnet18
"""
apt-get install -y graphviz
pip install torchviz
pip install onnxscript
"""
model = resnet18()
model.eval()
x = torch.randn(1, 3, 224, 224)
y = model(x)
dot = make_dot(y, params=dict(model.named_parameters()))
dot.format = 'png'
dot.render("model_graph")
onnx_file_path = "resnet18_model.onnx"
torch.onnx.export(
model, # 要导出的模型
x, # 虚拟输入
onnx_file_path, # 导出文件路径
export_params=True, # 是否导出权重参数
opset_version=17, # ONNX 算子版本,建议 12 及以上
do_constant_folding=True, # 是否执行常量折叠优化
input_names=['input'], # 输入节点的名称
output_names=['output'], # 输出节点的名称
dynamic_axes={ # 可选:支持动态 Batch Size
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)
print(f"模型已成功导出至: {onnx_file_path}")
对于第二种可以直接将到处的模型通过网站:https://netron.app/ 去分析每个节点的具体参数以及输入和输出。
torch.compile
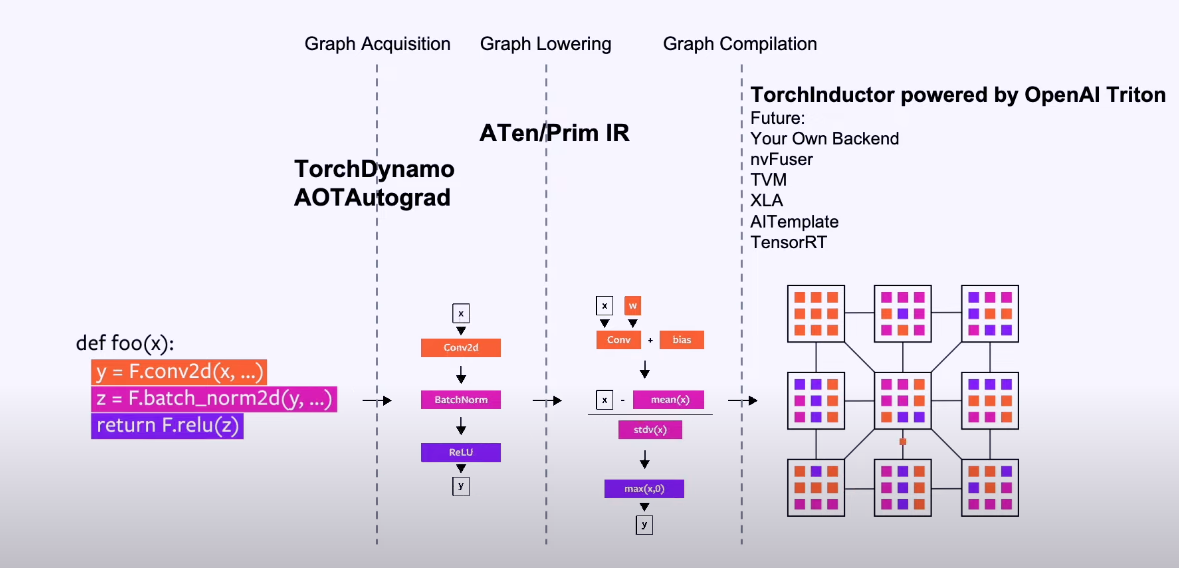
首先了解几个基本过程2:
第一步:首先通过TorchDynamo —— “动态录音机”(抓图)
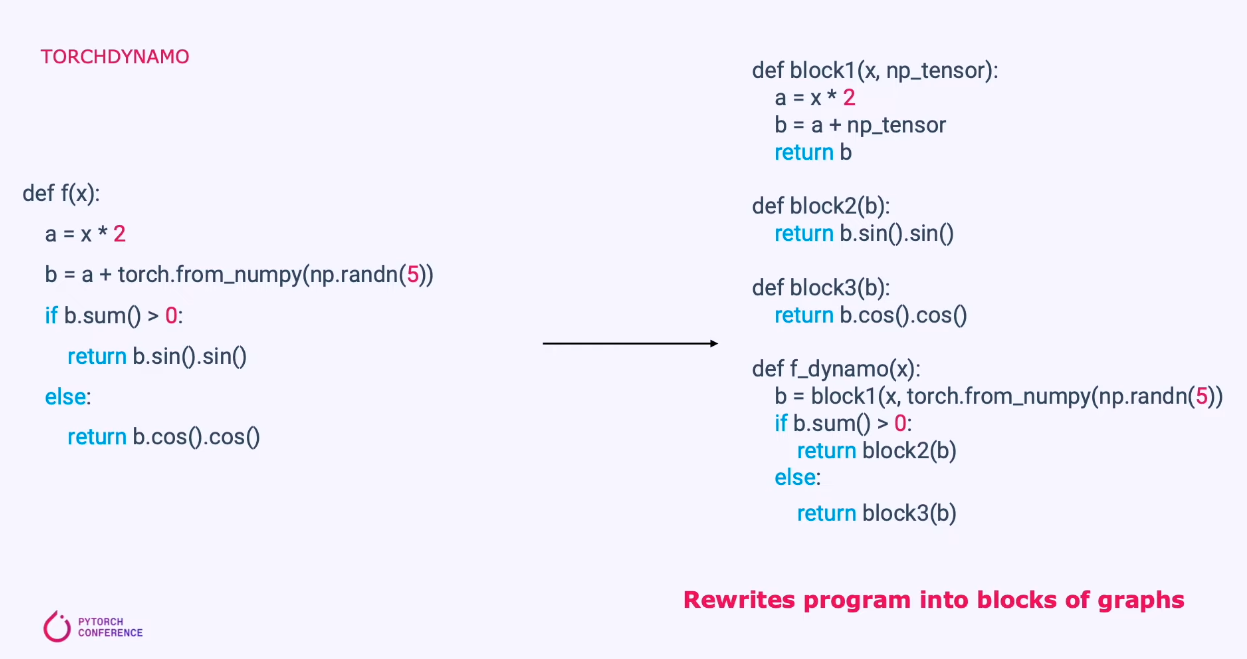
当你第一次运行被 torch.compile 装饰的函数时,Dynamo 会“偷偷”接管 Python 的执行。 它不是静态看代码,而是一边模拟运行,一边录音: 把所有 PyTorch 操作(加、乘、卷积、ReLU 等)记录下来,画成一张 FX Graph(一张计算流程图)。 python 的普通代码(if 判断、for 循环、打印等)如果太复杂,就产生 Graph Break(图断开),这部分还是用原来的慢方式运行。 它还会记录“假设”:比如输入 tensor 的形状是 [32, 3, 224, 224]、类型是 float32 等。这些假设叫 Guards(守卫)。 为什么动态录音?因为 PyTorch 代码经常有动态形状、控制流,静态分析太难了。
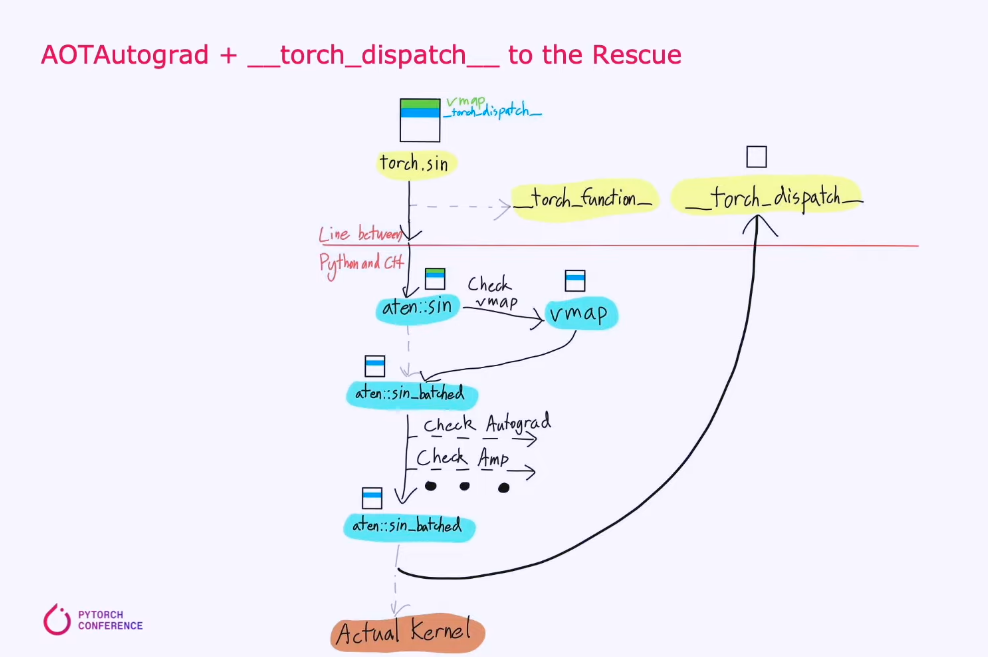
第二步:AOTAutograd —— “提前准备反向传播”
如果是训练(需要 backward),Dynamo 只抓了前向(forward)。 AOTAutograd 会提前从前向图生成反向图(不用等到真正做 backward 时才临时建图)。 它还会把复杂操作分解成更基础的操作(PrimTorch),让后续优化更容易。 好处:前向+反向可以一起优化,节省内存(不用保存所有中间结果)。
第三步:TorchInductor(默认后端)—— “优化工厂 + 代码生成器”
拿到干净的计算图后,Inductor 开始大改造: 融合操作:把能合并的算子合成一个内核(例如 conv + batchnorm + relu 变成一个 GPU 内核,减少内存读写)。 布局优化、内存复用、循环优化等。 生成代码: GPU 上主要生成 Triton 代码(一种简单却高效的语言,比手写 CUDA 容易,性能接近官方)。 CPU 上生成 C++ 代码。
简单使用
值得注意的是:在torch>2.0之后引入一个新的概念 torch.compile3 在传统的计算过程中,如 x+y那么pytorch就会执行Python 解释器调用函数、检查类型、分配内存、调用 GPU/CPU 操作等操作,这样以来过程就会比较慢,比如说简单的计算:
import torch
def fun1(a, b):
return a+b
fun_compile = torch.compile(fun1)
@torch.compile
def fun2(a, b):
return a+b
基本上只需要对涉及到计算的函数用 torch.compile处理即可(第一次编译速度比较慢,后续计算就快了),直接测试使用compile再模型训练过程中的表现,值得注意的是在使用Trl框架进行强化学习过程中,训练参数直接支持使用 compile(具体位置为:transformers/training_args.py,直接在DPOConfig中进行指定即可,直接使用 torch_compile= True 即可启动),如果是其它训练过程(假设使用accelerator框架进行):
if compile:
s_compile_time = time.time()
model = torch.compile(model, mode="reduce-overhead")
accelerator.print(f"Compile Time: {time.time() - s_compile_time:.2f}s")
...
model, optimizer, train_loader, test_loader = accelerator.prepare(model, optimizer, train_loader, test_loader)
在测试resnet50在CIFAR10数据集上表现如下(代码):
# 使用compile
Compile Time: 0.89s
Epoch 00 | Train Time: 12.17s | Batch Time: 0.14764126466245067Train ACC: 11.19% | Test ACC: 11.89%
Epoch 05 | Train Time: 5.72s | Batch Time: 0.046339944917328506Train ACC: 15.49% | Test ACC: 15.54%
Epoch 10 | Train Time: 5.71s | Batch Time: 0.04499245176509935Train ACC: 18.26% | Test ACC: 19.50%
...
Epoch 85 | Train Time: 5.60s | Batch Time: 0.04556511859504544Train ACC: 37.01% | Test ACC: 39.24%
Epoch 90 | Train Time: 5.70s | Batch Time: 0.04652732245776118Train ACC: 37.74% | Test ACC: 40.30%
Epoch 95 | Train Time: 5.66s | Batch Time: 0.04582754933104223Train ACC: 38.30% | Test ACC: 41.03%
# 不使用compile
Epoch 00 | Train Time: 5.71s | Batch Time: 0.05050786174073511Train ACC: 11.29% | Test ACC: 11.41%
Epoch 05 | Train Time: 5.25s | Batch Time: 0.047670155155415436Train ACC: 15.84% | Test ACC: 16.45%
Epoch 10 | Train Time: 6.11s | Batch Time: 0.04854408575564015Train ACC: 18.56% | Test ACC: 19.64%
...
Epoch 85 | Train Time: 6.00s | Batch Time: 0.048004476391539284Train ACC: 36.92% | Test ACC: 39.01%
Epoch 90 | Train Time: 5.05s | Batch Time: 0.04837274064823073Train ACC: 37.71% | Test ACC: 39.21%
Epoch 95 | Train Time: 5.30s | Batch Time: 0.04843420398478605Train ACC: 38.82% | Test ACC: 40.20%
从上述结果上看,最后ACC差异不大,但是在每个epoch以及batch_time上还是有差异的,于此同时对于在GRPOTrainer上表现如下(只看loss和奖励值,测试的数据以及模型为trl-lib/DeepMath-103K和Qwen2-0.5B-Instruct,其中只使用1%数据):
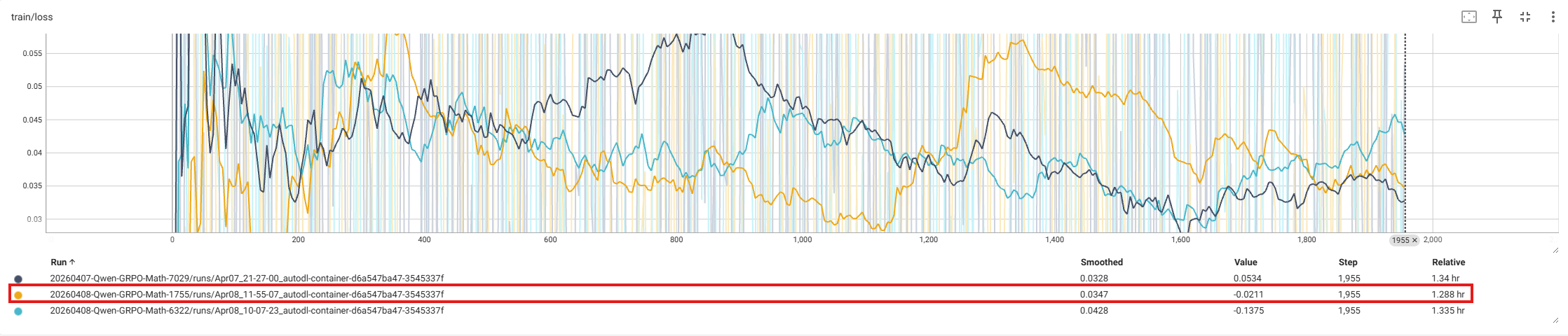
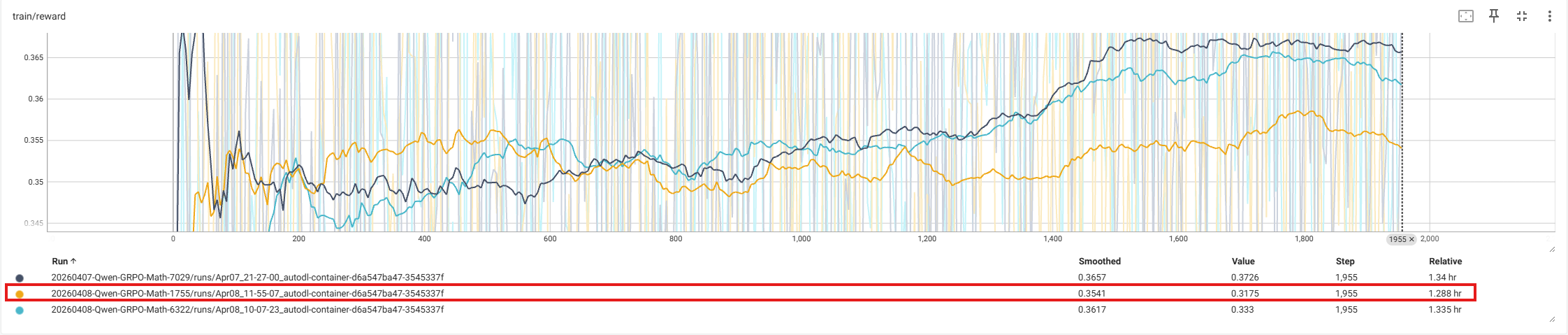
通过在Resnet以及GRPO两种训练中发现,时间上都会减少并且在模型最后效果是差异不大。下面进一步解释上面没有解释的几个概念。
dynamo
最上面提到在使用 compile 之前会去获取计算图,之所以要提前获取计算图是因为:pytorch中有些计算如 ReLU(Add(A, B))等,执行逻辑就是先add而后计算relu,但是如果提前获取计算图可以直接通过triton将两部合并为一段代码进而减少计算提高速度,参考4这些内容理解。比如说在官方示例中:
from typing import List
import torch
from torch import _dynamo as torchdynamo
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print("my_compiler() called with FX graph:")
gm.graph.print_tabular()
return gm.forward # return a python callable
@torchdynamo.optimize(my_compiler)
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
得到的输出是:
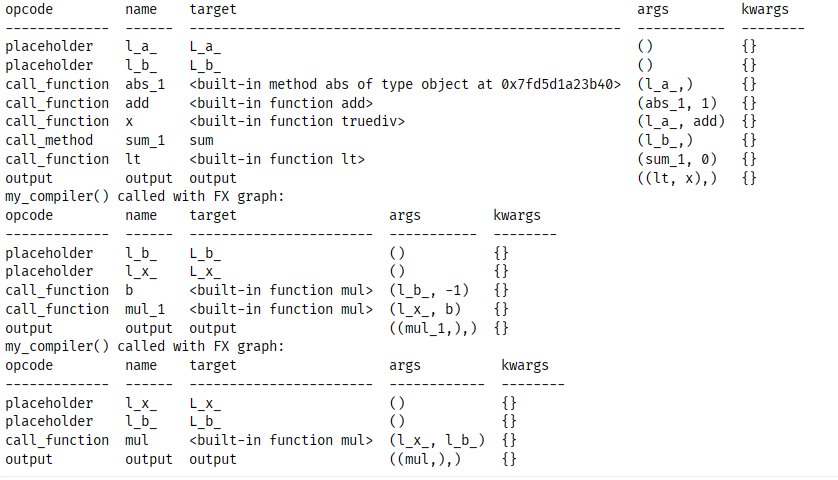
对于上述参数解释如下:1、opcode(操作码),placeholder: 函数的输入参数(入口)。 call_function: 调用一个 Python 函数(如 add, mul)。 call_method: 调用一个对象的方法(如 tensor.sum())。 output: 整个图的返回值(出口);2、name: 这个节点在图中的唯一名称(可以理解为变量名)。 3、target: 实际执行的具体函数或目标。 4、args / kwargs: 该操作需要的输入参数。如果参数是 abs_1,表示它引用了前面名为 abs_1 节点的输出。
第一个图:逻辑分支的“上半部分” ,这个图展示了一段包含条件判断的计算逻辑:
输入: 接收两个输入 l_a_ 和 l_b_。
计算路径 A: 计算 abs(l_a_) + 1,然后计算 l_a_ / (abs(l_a_) + 1),结果存为 x。
计算路径 B: 计算 l_b_.sum(),结果存为 sum_1。
条件判定: 判断 sum_1 < 0,结果存为 lt(此时其为一个bool类型数据)。
输出: 返回了一个元组 (lt, x)。
之所以要返回一个bool类型数据是因为 TorchDynamo 遇到了图中断(Graph Break)。Python 的 if 分支通常无法直接被编译进同一个静态图中。它先编译到 if 判定的地方,根据 lt 的真假,再决定后面走哪个子图。
后两个图:分支后的执行路径,由于代码中可能存在类似 if sum(b) < 0: return x * (-b) else: return x * b 的逻辑,编译器生成了两个不同的子图:子图 2 (my_compiler called again):执行的是 x * (b * -1)。这对应 sum(b) < 0 成立时的逻辑。子图 3 (my_compiler called again):执行的是 x * b。这对应 sum(b) < 0 不成立时的逻辑
那么最后通过上述过程将图处理为:
def forward(a, b):
# 对应第一个图
abs_1 = abs(a)
add = abs_1 + 1
x = a / add
sum_1 = b.sum()
# 此时发生了 Graph Break (图中断)
# 因为后端需要知道 lt 是 True 还是 False 才能继续
if sum_1 < 0:
# 对应第二个图
return x * (b * -1)
else:
# 对应第三个图
return x * b
那么此时不妨进一步了解底层原理(compile是怎么拆分得到计算图的呢?)借鉴56中描述捕获计算图是在翻译 Python 字节码7的过程中实现的,还是用最上面的例子直接通过 dis.dis(toy_example) 输出得到字节码:
11 0 RESUME 0
12 2 LOAD_FAST 0 (a)
4 LOAD_GLOBAL 1 (NULL + torch)
14 LOAD_ATTR 2 (abs)
34 LOAD_FAST 0 (a)
36 CALL 1
44 LOAD_CONST 1 (1)
46 BINARY_OP 0 (+)
50 BINARY_OP 11 (/)
54 STORE_FAST 2 (x)
13 56 LOAD_FAST 1 (b)
58 LOAD_ATTR 5 (NULL|self + sum)
78 CALL 0
86 LOAD_CONST 2 (0)
88 COMPARE_OP 2 (<)
92 POP_JUMP_IF_FALSE 5 (to 104)
14 94 LOAD_FAST 1 (b)
96 LOAD_CONST 3 (-1)
98 BINARY_OP 5 (*)
102 STORE_FAST 1 (b)
15 >> 104 LOAD_FAST 2 (x)
106 LOAD_FAST 1 (b)
108 BINARY_OP 5 (*)
112 RETURN_VALUE
那么dynamo利用这个字节码的逻辑就是,输入:Python 字节码。 处理:逐条扫描字节码,若是 Tensor 运算就记在 FX Graph 账本上,若是普通 Python 逻辑就正常模拟。 结果:产生一个高效的 FX Graph + 一组确保安全的 Guards,对于这个过程可以看博客8。
AOTAutograd
dynamo只是获取了forward过程,模型优化(backward过程)在compile中则是通过AOTAutograd进行处理为推理出来的计算图,自动生成配套的反向传播(Backward)计算图。在pytorch中还有一中计算梯度方式也是最常见的计算方式autograd对于这两种之间差异在于(借用Grok中给出解释):
1、Autograd::你只写前向传播(forward),PyTorch 会在运行时动态记录每一步操作,自动构建一个计算图(computational graph)。当你对 loss 调用 .backward() 时,它就沿着这个图反向走一遍,用链式法则自动算出所有参数的梯度。
这个图是动态、临时的(ephemeral):每次 forward 都会重新建图,用完就销毁(除非你手动 retain_graph=True)。优点是超级灵活——支持 if、for 循环、任意 Python 代码,调试也方便。但缺点是每次都要重新建图,Python 开销大,不容易做全局优化。
2、AOTAutograd:它和普通 Autograd 的最大区别是:不是在运行时动态建图,而是提前就把前向和反向的整个计算图一次性捕获。第一次运行时,用“假张量”(FakeTensor)模拟一遍 forward,记录下所有操作,生成两个静态的 FX Graph(一个 forward,一个 backward)。这两个图是可分析、可复用、可优化的 Python 对象。
简单总结就是:
Autograd没有计算都会重新去构建图,AOTAutograd提前将图创建好,下次用直接按照图去运行即可(省去创建费时)
进阶使用
1、如何debug;2、如何使用compile中参数;3、可以更加深入的去了解代码底层细节,比如说对于字节码在dynamo中式如何将其转化为计算图的呢?以及在atoautograd中又是如何利用直观计算图的呢?
当你执行 compiled_model = torch.compile(model) 时,内部大致分成以下几步:
TorchDynamo(图捕获阶段)
它负责第一次运行时拦截 Python 字节码(bytecode)。
分析代码,把纯 PyTorch 张量操作的部分提取出来,生成一个或多个 FX Graph(前向计算图)。
Python 控制流(if、for、print 等)如果无法静态化,就会产生 graph break,那部分保持 eager 执行。
这一步主要捕获的是 forward(前向) 的计算图。
AOTAutograd(Ahead-of-Time 自动微分阶段)
Dynamo 捕获到 forward 的 FX Graph 后,会把它交给 AOTAutograd。
AOTAutograd 不是简单“利用”这个图,而是做更重要的事:
使用 FakeTensor(假张量,不占内存)模拟运行一次 forward。
在这个模拟过程中,让 PyTorch 原生的 Autograd 引擎跑一遍,从而提前记录并生成完整的 backward 图。
得到一个 joint graph(前向 + 反向合并的完整图)。
然后进行 min-cut partition(最小割划分),把 joint graph 拆分成:
一个优化的 forward graph(决定哪些中间结果需要保存)
一个优化的 backward graph(决定哪些可以重计算以节省显存)
最后把 forward + backward 包装成一个 torch.autograd.Function,这样当你调用 loss.backward() 时,实际执行的就是这个提前编译好的 backward 图。
后续编译器(如 TorchInductor)
对划分后的 forward 和 backward 图分别做算子融合、代码生成等底层优化,生成高效的内核代码。
torch数据形状改变方式
在torch中涉及到数据形状改变函数,总结如下:
| 方法 | 功能描述 | 是否拷贝数据 | 注意事项 |
|---|---|---|---|
reshape() |
返回指定形状的新张量,可能会返回原数据的视图,也可能复制数据 | 视情况而定 | 当原张量在内存中不连续时会复制数据 |
view() |
返回与原数据共享内存的新张量,形状可变 | 否 | 仅适用于内存连续的张量,否则需先 .contiguous() |
unsqueeze() |
在指定维度插入一个大小为 1 的维度 | 否 | 常用于增加 batch 维度或通道维度 |
squeeze() |
删除大小为 1 的维度 | 否 | 默认删除所有为 1 的维度,可指定 dim |
expand() |
扩展张量的某个维度,不复制数据,使用广播 | 否 | 扩展的维度只能是 1,否则报错;共享内存需注意修改风险 |
expand_as() |
将张量扩展为与另一个张量形状相同 | 否 | 同 expand(),但形状由另一张量决定 |
transpose() |
交换两个维度位置 | 否 | 常用于矩阵转置,返回视图 |
permute() |
按指定顺序重新排列所有维度 | 否 | 返回视图,但会改变 strides |
contiguous() |
返回一个内存连续的张量 | 是(如必要) | 常与 view() 搭配使用 |
clone() |
复制张量数据并返回一个新张量 | 是 | 独立内存,与原张量不共享存储 |
detach() |
返回与原数据共享内存但不参与计算图的张量 | 否 | 常用于切断梯度计算链条 |
torch多进程
model.train()、model.eval()、torch.no_grad()
model.train():把整个模型设为训练模式;如 Dropout 开启、BatchNorm 用小批量统计并更新滑动均值/方差。不影响是否计算梯度。
model.eval():把模型设为评估/推理模式;如 Dropout 关闭、BatchNorm 使用已累计的运行统计,不再更新。不影响是否计算梯度。
torch.no_grad():在其上下文中关闭 autograd 记录,从而不构建计算图、不产生 .grad,省显存、加速前向。不改变模型里层的训练/评估行为
总结
建议:通过上述结果对比发现模型训练可以提前去开启compile
参考
-
https://pytorch.org/blog/computational-graphs-constructed-in-pytorch/ ↩
-
https://zhuanlan.zhihu.com/p/680288200?utm_psn=2025772286163067927 ↩
-
https://docs.pytorch.org/tutorials/intermediate/torch_compile_tutorial.html ↩
-
https://docs.pytorch.org/docs/stable/user_guide/torch_compiler/torch.compiler_dynamo_overview.html ↩