我们都知道在使用dl模型(比如图像分类)最后的结果都是一个概率值(比如100种类别,输出就是每种类别的概率),常见的作法就是直接取概率最大的作为最终预测结果,但是LLM里面也用这种方式合理吗(毕竟文本也需要考虑整体的不单单就是让下一个字最佳即可)。本文主要介绍:Beam search、Greedy search等LLM生成策略方式。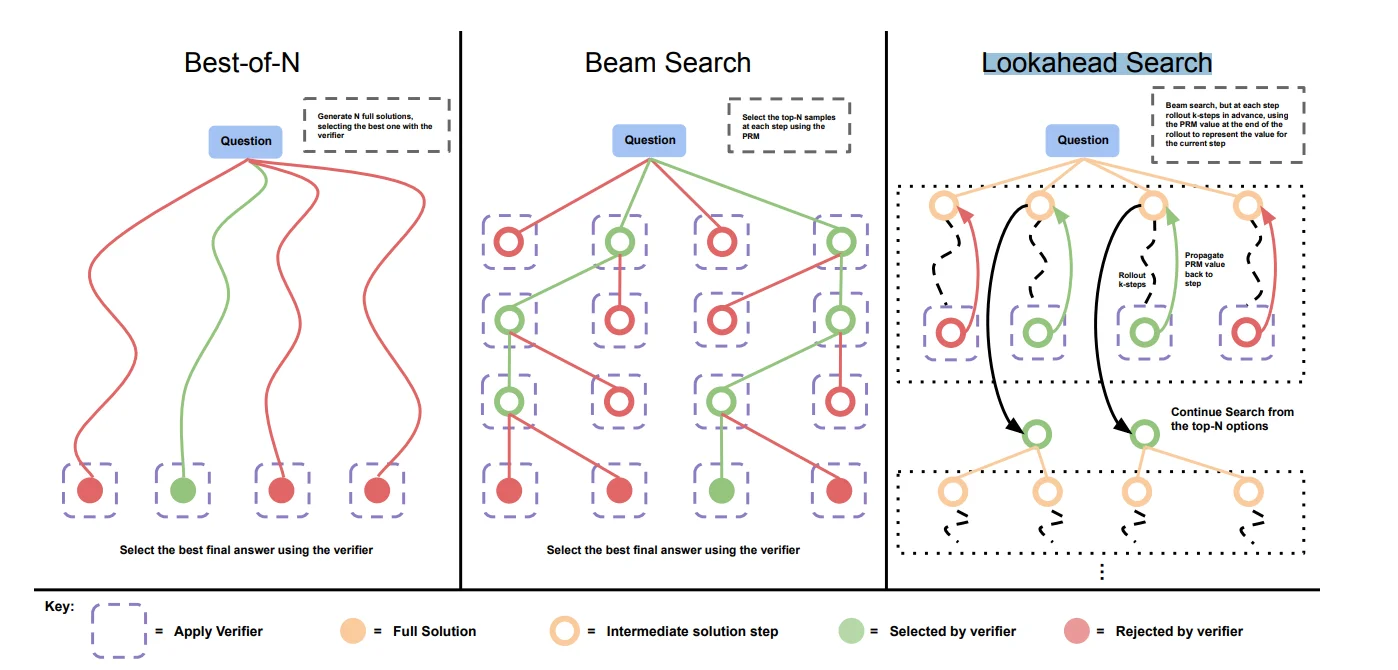
模型生成过程
都知道模型输出过程就是将prompt丢给模型,然后模型输出回答,但是实际上在模型输出的内部中输出过程是:Prefill阶段+Decoding阶段两部分组成首先对于这两部分简单介绍如下:1、Prefill阶段该阶段中直接将整个 prompt(用户输入 + system prompt + 历史对话等)的所有token进行输入而后去输出完整的KV Cache以及第一步生成logits(也就是预测第一个输出token);2、Decoding阶段直接将Prefill阶段中的KV Cache以及上一步生成的token进行输入而后进行自回归逐个生成(值得注意的是在模型输出中,直接根据Vocabulary数量得到在Vocabulary中每个token的概率),在面对海量的Vocabulary中就需要去对每一个token输出去使用不同的采样方式,其中使用比较多的有如下几种(以vllm中的采样方式为例)
贪婪解码
贪婪解码是最简单直接的采样方式:每一步都选择概率最高的那个token。这种方式保证了输出的确定性——同样的输入每次都会得到完全一样的输出。
from vllm import SamplingParams
greedy_params = SamplingParams(
temperature=0, # 设置为0即触发贪婪解码
max_tokens=100
)
随机采样
随机采样按照模型计算出的概率分布进行随机抽取。为了让分布更“平滑”或更“尖锐”,我们引入了温度(Temperature)参数: 低温度(<1.0):概率分布更集中,高概率token更容易被选中,输出更确定;高温度(>1.0):概率分布更平坦,低概率token也有更多机会,输出更多样
直观理解:温度就像给模型的“选择偏好”调节器。温度越低,模型越“固执”地选最可能的那条路;温度越高,模型越“随性”,愿意尝试一些意料之外的表达
# 低温度 - 更保守
conservative_params = SamplingParams(
temperature=0.3,
max_tokens=100
)
# 高温度 - 更随机
creative_params = SamplingParams(
temperature=1.2,
max_tokens=100
)
Top-k采样
Top-k采样只保留概率最高的k个token,然后在这k个token中进行重新归一化采样。这样可以有效过滤掉那些概率极低、毫无意义的token,让生成过程更稳定。
直观理解:就像让模型只能从“最有可能的前k个答案”里挑选,把那些明显离谱的选项先剔除掉。
区别于Greedy search每次都会选择一个最优的输出,Beam search则是会选择一个 束宽(beam size)(k)也就是在生成过程中会从生成的内容中选择k个最为第t步的输出,而后在t+1步中会将前k步的输出结合起来构成新的输出。
top_k_params = SamplingParams(
temperature=0.8,
top_k=50, # 只考虑概率最高的50个token
max_tokens=100
)
核采样
核采样是Top-k的“升级版”:不固定k值,而是动态选择一组概率累积和达到p的最小token集合。例如top_p=0.9表示选择概率最高的token,直到它们的累积概率超过90%。 这种方式比Top-k更灵活——当分布很集中时只选几个token;当分布很分散时会选更多token,让模型有更多探索空间。
直观理解:模型先按概率从高到低“收罗”候选词,直到收罗到的词的总概率达到90%为止,然后只在这批词里做选择。分布集中时候选词少(更确定),分布分散时候选词多(更灵活)。
nucleus_params = SamplingParams(
temperature=0.8,
top_p=0.9, # 累积概率阈值90%
max_tokens=100
)
Beam Search
与上述采样方式不同,Beam Search不是随机采样,而是一种确定性搜索算法。它同时维护k条候选序列(称为“束”),每一步都扩展所有候选,只保留总体概率最高的k条。最终选择概率最高的完整序列作为输出。
直观理解:不像贪婪解码那样“走一步看一步”,Beam Search同时探索多条路径,保留最有希望的几条往前走,最后选出最好的那条。就像下棋时考虑多步之后的局面。
beam_search_params = SamplingParams(
use_beam_search=True,
best_of=5, # 束宽度(同时探索5条路径)
temperature=0, # Beam search时通常设为0
max_tokens=100
)
不同生成参数
温度调节
比如说温度调节使用:
@torch.no_grad()
def generate(self, idx, eos, max_new_tokens, temperature=1.0, top_k=None):
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.params.max_seq_len else idx[:, -self.params.max_seq_len:]
# forward the model to get the logits for the index in the sequence
logits = self(idx_cond)
logits = logits[:, -1, :] # crop to just the final time step
if temperature == 0.0:
# "sample" the single most likely index
_, idx_next = torch.topk(logits, k=1, dim=-1)
else:
# pluck the logits at the final step and scale by desired temperature
logits = logits / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
if idx_next==eos:
break
return idx
上面生成器中,设定最大生成长度max_new_tokens,通过前馈计算(self(idx_cond))生成之后通过选取最后时间步的概率($b,t,vocab_size \rightarrow b, 1, vocab_szie$)这样就相当于得到模型新的输出(每个词的概率)当选择的温度参数为0时,模型会选择最可能的 token(即选择 logits 中最大值对应的索引)。这是确定性的选择。反之就会,logits 会被 temperature 除以,从而影响选择的多样性。较高的温度值会使得概率分布变得更均匀,增加随机性;较低的温度值会让概率分布更加尖锐,使得选择更有偏向性。
从上面代码其实也很容易发现 温度系数是如何影响输出的:
通过温度系数$T$来平滑最后输出:
当$T=1$ 时,公式恢复为标准的softmax计算,logits 被直接用来计算概率。
当$T>1$ 时,logits 被缩小,概率分布变得更加平滑。这个时候,低概率的选项也可能被采样到,从而增加生成的多样性。温度较高时,模型的输出更加随机,生成的文本更加多样化。
当$T<1$时,logits 被放大,概率分布更加尖锐。这个时候,高概率的选项会变得更加突出,低概率的选项几乎被完全抑制,从而使模型的输出更加确定性。低温度时,模型倾向于生成高概率的单词,减少了生成的多样性。
那么按照理论上当设置temperature=0时候输出应该是相同的,因为次数每一步都是使用greedy decoding进行处理,但是实际上不是的这是因为数值精度原因导致发生差异。总的来说temperature只能起到控制采用的随机性。
重复惩罚控制
具体控制模型输出方法和温度调节相似,在计算方法上两部分都是相似的,不过:温度调节–>对所有的输出token都去调节,重复惩罚控制–>对已经输出的token去调节,在实际控制过程中先重复惩罚控制而后topk温度等这部分参数控制。
Lookahead Search
在生成过程中,它不仅考虑当前 token,还预先评估多步生成结果的质量,以此来选择最合适的当前步骤。它是一种对未来进行前瞻评估的策略,能够平衡生成的连贯性和多样性。使用方法比较简单
probs = F.softmax(logits, dim=-1)
candidate_probs = []
for _ in range(lookahead_depth):
idx_next = torch.multinomial(probs, num_samples=1)
candidate_score = self.evaluate_candidate(idx, idx_next, eos)
candidate_probs.append((candidate_score, idx_next))
candidate_probs.sort(reverse=True, key=lambda x: x[0])
best_candidate = candidate_probs[0][1]
idx = torch.cat((idx, best_candidate), dim=1)
if best_candidate == eos:
break
控制模型输出
根据官方文档在控制模型输出过程中,有两种方式去控制模型输出格式:1、json_schema;2、pydantic model方式,两种方式差异不大。比如说使用json_schema方式进行控制,那么模型会按照json_schema进行输出,比如说(使用豆包模型可以使用openai方式进行调用):
from openai import OpenAI
client = OpenAI(
base_url="https://ark.cn-beijing.volces.com/api/v3",
api_key="xxx", # 调用api和本地vllm在线推理是没有差异的
)
json_schema = {
"name": "trump_analysis",
"schema": {
"type": "object",
"properties": {
"姓名": {"type": "string", "minLength": 1},
"年龄": {
"type": "string",
"pattern": "^\\d{1,3}$" # 限制为合理数字字符串
},
"出生年月日": {
"type": "string",
"pattern": "^\\d{4}-\\d{2}-\\d{2}$" # 强制 YYYY-MM-DD 格式
},
"财富世界排名": {"type": "string", "pattern": "^\\d+$"},
"职位": {
"type": "array",
"items": {"type": "string", "minLength": 1},
"minItems": 1, # 至少有一个职位
}
},
"required": ["姓名", "年龄", "出生年月日", "财富世界排名", "职位"],
"additionalProperties": False
}
}
completion = client.chat.completions.create(
model="doubao-seed-1-6-251015",
messages = [
{"role": "user", "content": "分析一个特朗普的生平,如年龄、世界富豪排名,按照json格式输出"},
],
response_format=json_schema
)
print(completion.choices[0].message.content)
只需要在模型输出过程中进行指定: response_format={"type": "json_object"} 即可控制模型按照json格式输出,除此之外可以使用 json_schema 去控制让模型去填写字段到我的要求格式中。除此之外在书写 json_schema 过程中也可以直接去对字符进行控制比如说:"net_worth": {"type": "string","pattern": r"^\$[0-9]+(\.[0-9]{1,2})? (Billion|Million)$"}, 通过正则匹配的方式控制模型输出:
# 不使用正则匹配
"net_worth": "约25亿美元",
# 使用正则匹配
"net_worth": "$2.6 Billion",
除此之外如果模型是使用vllm进行本地部署在控制模型输出上和上面代码没有差异。
本地启动vllm(启动参数):
HF_ENDPOINT=https://hf-mirror.com HF_HUB_CACHE=/root/autodl-tmp/.cache vllm serve Qwen/Qwen3-0.6B --host 0.0.0.0 --port 8001 --gpu-memory-utilization 0.5 --max-model-len 16384 --max-num-seqs 256 --trust-remote-code --served-model-name qwen3-0.6B
比如说使用pydantic类型进行控制(测试使用上面提到的 qwen3-0.6b 模型):
client = OpenAI(base_url="http://127.0.0.1:8001/v1",api_key="EMPTY")
class Step(BaseModel):
explanation: str
output: str
class MathResponse(BaseModel):
steps: list[Step]
final_answer: str
def pydantic_test():
completion = client.beta.chat.completions.parse(
model="qwen3-0.6B",
messages=[
{"role": "system", "content": "你是一个数学大师"},
{"role": "user", "content": "计算 x^2 +2x+ 28 = 32."},
],
response_format=MathResponse,
)
message = completion.choices[0].message
print(message)
assert message.parsed
for i, step in enumerate(message.parsed.steps):
print(f"Step #{i}:", step)
print("Answer:", message.parsed.final_answer)
底层原理
在使用vllm中启动过程中通过参数 --guided-decoding-backend guidance 去控制模型输出(支持参数有 guidance 以及 xgrammar 默认是 auto)以 xgrammar 为例,其内部原理核心两部分:1、Pushdown Automaton(PDA);2、自适应 Token Mask 缓存。
先用一个具体例子解释生成过程,比如说上面我指定的是:
prompt=分析一个特朗普的生平,如年龄、世界富豪排名,按照json格式输出,而后我给定的json格式是:{"姓名": {"type": "string", "minLength": 1},"年龄": {"type": "string","pattern": "^\\d{1,3}$"},}那么模型(vllm)中输出过程为:
预处理阶段:首先将我的json schema转化为一个状态机,比如状态0必须输出{,状态1必须输出:"姓名",依此类推,而后计算离线mask,直接扫描vllm中的词表,比如状态0只有{合法其他直接mask。生成过程:

对于第一部分:普通的有限状态机无法处理复杂的嵌套结构,而这正是 XGrammar 引入 PDA 的原因。可以将 PDA 简单理解为一个带有“栈”记忆机制的智能体。以生成标准的 JSON 格式为例:当模型生成一个左大括号 { 时,PDA 会将其入栈(Push);当需要闭合结构并生成右大括号 } 时,PDA 会将其出栈(Pop)。通过这种严密的“栈”式匹配,XGrammar 能够像编译器一样,在生成层面死死守住语法的嵌套规则,确保输出的每一层级都严格符合规范。
对于第二部分:仅仅有 PDA 还不够。在当今动辄 128k 词汇量的 LLM 词表中,如果在 Runtime(运行时)逐一让 CPU 去验证数以十万计的 Token 是否符合当前语法状态,这无疑会成为一场性能灾难。XGrammar 通过一套巧妙的分类与缓存机制破局:
1、预处理:Token 的“双轨制”分类,在模型开始生成前,XGrammar 会将整个词表的 Token 划分为两类:上下文无关 Token (Context-Independent Tokens): 这类 Token 的合法性仅取决于当前 PDA 所在的节点状态,无需回溯栈内的历史记录。上下文相关 Token (Context-Dependent Tokens): 这类 Token 的合法性不仅取决于当前节点,还强依赖于栈内信息(例如:当前究竟嵌套了多少层,是否到了该闭合多层右括号的时候)。
2、运行时:空间换时间的极致压缩基于上述分类,XGrammar 构建了极其高效的自适应缓存机制:预计算缓存: 在生成前,系统预先计算好所有“上下文无关 Token”的合法性,并将其存储在一个高度压缩的位图缓存(Token Mask Cache)中。$O(1)$ 极速读取: 在实际生成阶段,对于绝大部分 Token,系统直接以 $O(1)$ 的时间复杂度从缓存中读取合法性掩码(Mask),瞬间完成筛选。按需校验: 仅仅对极少数的“上下文相关 Token”,才会在 CPU 上进行实时的状态机校验。
在vllm中起作用方式是:LLM 在自回归生成文本时,每一步都会输出一个包含所有词汇概率的 Logits 向量。XGrammar 作为一个 Logits Processor 插入到了采样(Sampling)之前:获取掩码:XGrammar 根据当前生成的状态,瞬间生成一个布尔型的掩码(Mask),1 代表符合语法规则,0 代表违规。修改概率:XGrammar 遍历 Logits 向量,将所有非法 Token 的对数概率强行修改为 $-\infty$(负无穷)。采样:经过 Softmax 计算后,非法 Token 的生成概率变为绝对的 $0$。模型只能被迫从合法的 Token 中采样。